


RegEx oder regulärer Ausdruck ist eine Zeichenfolge, die ein Suchmuster bildet.
RegEx kann verwendet werden, um zu überprüfen, ob eine Zeichenfolge ein bestimmtes Suchmuster enthält.
Python bietet ein integriertes Paket namens re, das zur Verarbeitung regulärer Ausdrücke verwendet werden kann.
Importieren Sie das re-Modul:
import re
Sobald Sie das re-Modul importiert haben, können Sie mit der Verwendung regulärer Ausdrücke beginnen:
Beispiel
Rufen Sie eine Zeichenfolge ab, um zu sehen, ob sie mit „China“ und beginnt endet mit „Land“ endet mit:
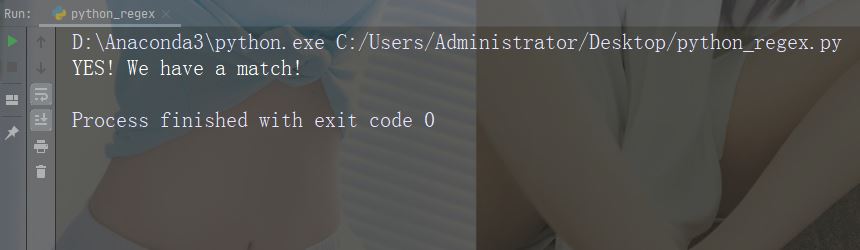
import re txt = "China is a great country" x = re.search("^China.*country$", txt)
Laufende Instanz
import re txt = "China is a great country" x = re.search("^China.*country$", txt) if (x): print("YES! We have a match!") else: print("No match")
re-Modul bietet eine Reihe von Funktionen, die es uns ermöglichen, Zeichenfolgen für den Abgleich abzurufen:
Metazeichen sind diese die Zeichen mit besonderer Bedeutung haben
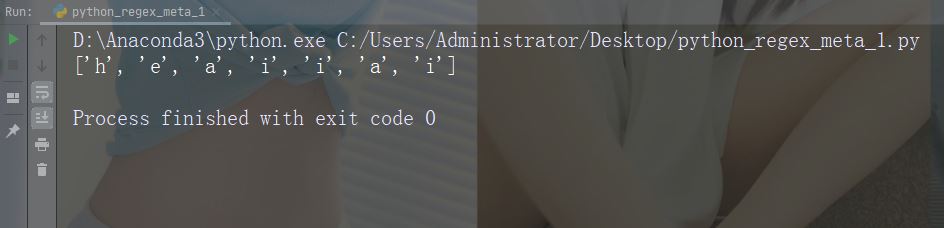
Zeichen: [] Beschreibung: Eine Reihe von Zeichenbeispielen: „[a-m]“
import re str = "The rain in Spain" #Find all lower case characters alphabetically between "a" and "m": x = re.findall("[a-m]", str) print(x)
Führen Sie das Beispiel aus
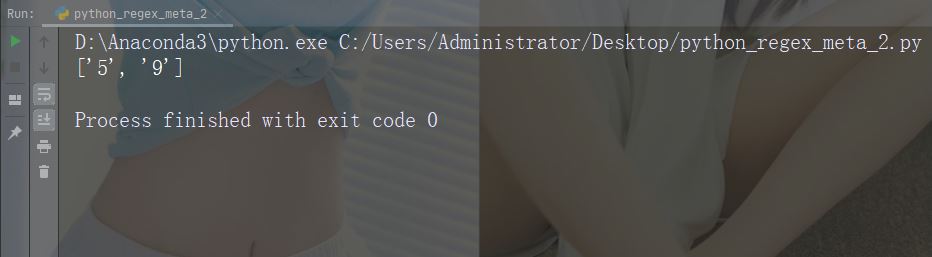
Zeichen: Beschreibung: Zeigt spezielle Sequenzen an (kann auch zum Escape verwendet werden Sonderzeichen) Beispiel: „d“
import re str = "That will be 59 dollars" #Find all digit characters: x = re.findall("\d", str) print(x)
Run-Beispiel
Zeichen: . Beschreibung: Beliebiges Zeichen (außer Newline) Beispiel: „he…o“
import re str = "hello world" #Search for a sequence that starts with "he", followed by two (any) characters, and an "o": x = re.findall("he..o", str) print(x)
Run-Beispiel
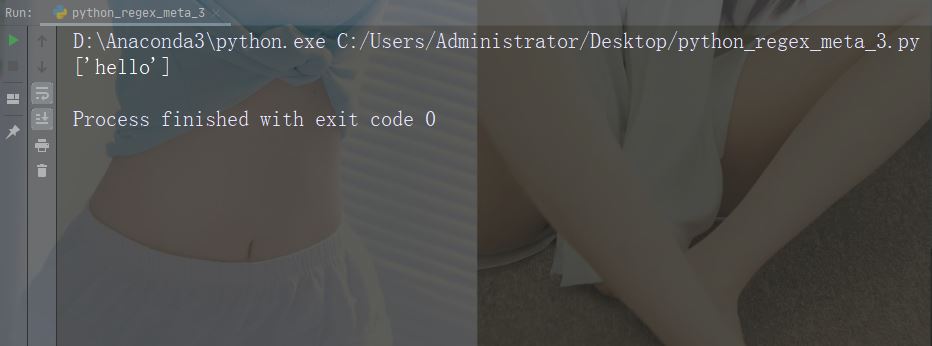
Zeichen: ^ Beschreibung : Beginnen Sie mit Beispiel: „^hello“
import re str = "hello world" #Check if the string starts with 'hello': x = re.findall("^hello", str) if (x): print("Yes, the string starts with 'hello'") else: print("No match")
Führen Sie das Beispiel aus
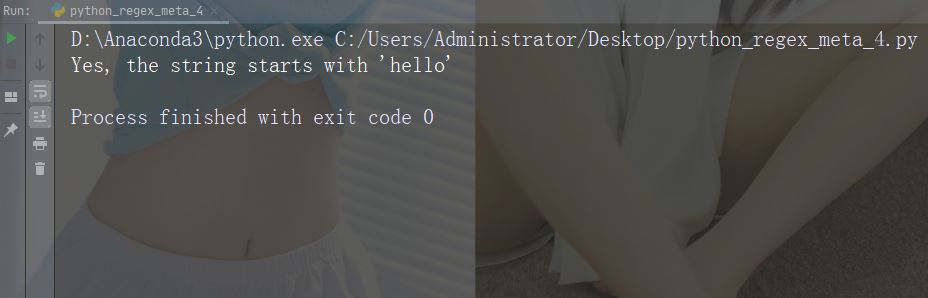
Zeichen: $ Beschreibung: Endet mit Beispiel: „world$“
import re str = "hello world" #Check if the string ends with 'world': x = re.findall("world$", str) if (x): print("Yes, the string ends with 'world'") else: print("No match")
Führen Sie das Beispiel aus
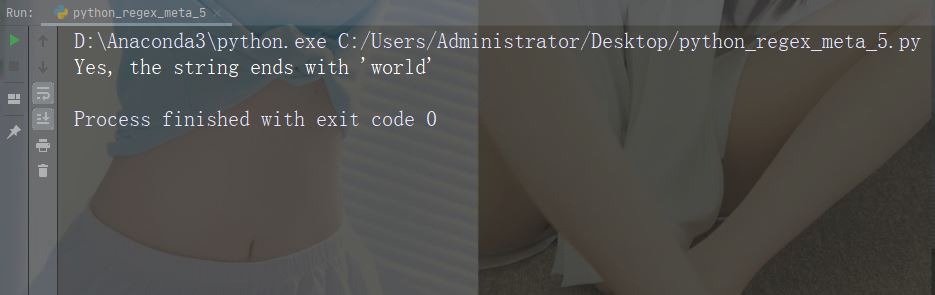
Zeichen: * Beschreibung: Null oder mehrere Vorkommen. Beispiel: „aix*“
import re str = "The rain in Spain falls mainly in the plain!" #Check if the string contains "ai" followed by 0 or more "x" characters: x = re.findall("aix*", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
Führen Sie das Beispiel aus : Geben Sie die genaue Anzahl der Vorkommen an. Beispiel: „al{2}“
import re str = "The rain in Spain falls mainly in the plain!" #Check if the string contains "ai" followed by 1 or more "x" characters: x = re.findall("aix+", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
Führen Sie das Beispiel aus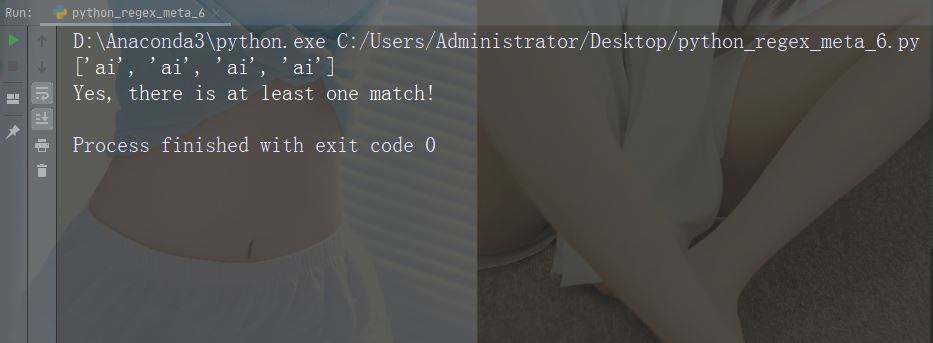
Zeichen: |. Beschreibung: Entweder Beispiel: „falls|stays“
import re str = "The rain in Spain falls mainly in the plain!" #Check if the string contains "a" followed by exactly two "l" characters: x = re.findall("al{2}", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
Führen Sie das Beispiel aus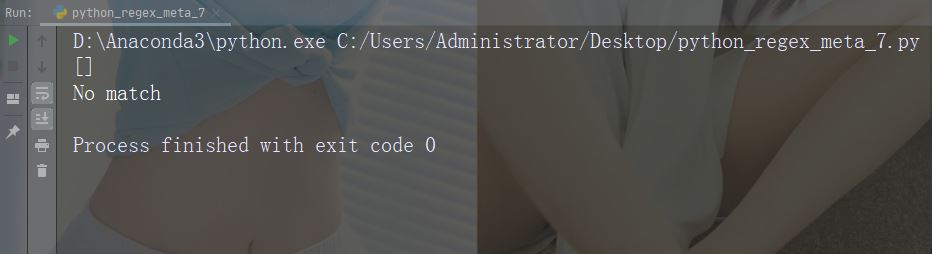
Zeichen : ( ) Beschreibung: Erfassen und gruppieren
Spezielle Sequenz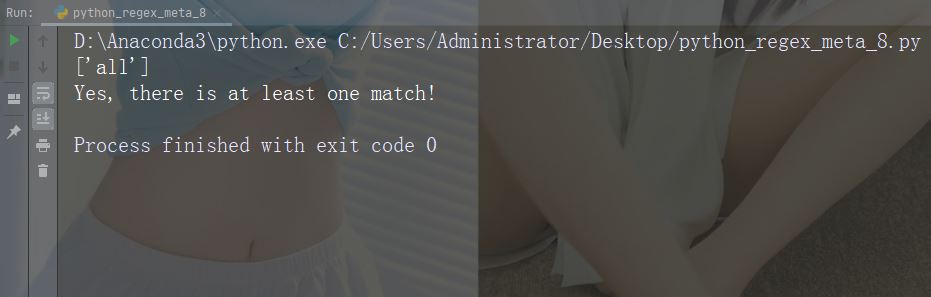
import re str = "The rain in Spain falls mainly in the plain!" #Check if the string contains either "falls" or "stays": x = re.findall("falls|stays", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
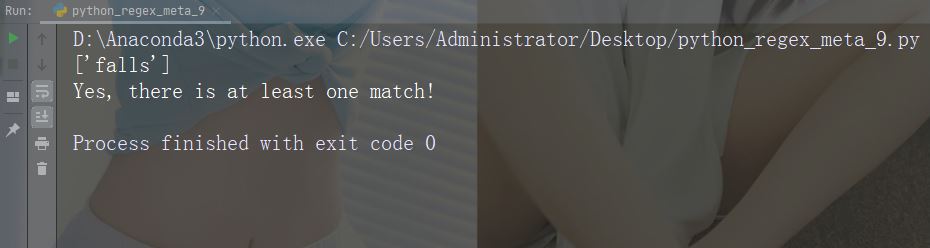
import re str = "The rain in Spain" #Check if the string starts with "The": x = re.findall("\AThe", str) print(x) if (x): print("Yes, there is a match!") else: print("No match")
import re str = "The rain in Spain" #Check if "ain" is present at the beginning of a WORD: x = re.findall(r"\bain", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
Characters: d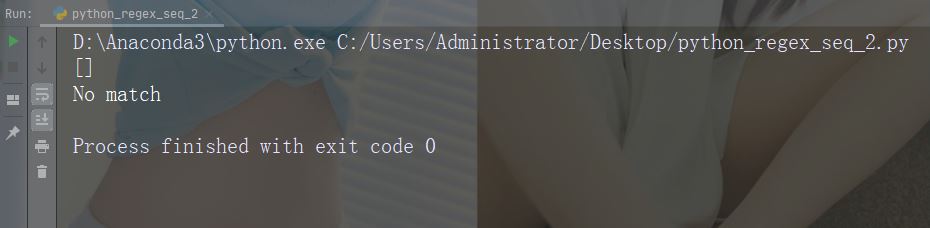
Zeichen: D
Beschreibung: Gibt Übereinstimmungen zurück, bei denen die Zeichenfolge keine Zahlen enthält. Übereinstimmung
Beispiel: „D“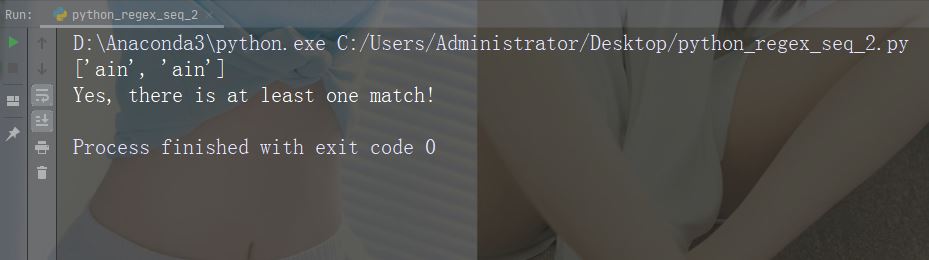
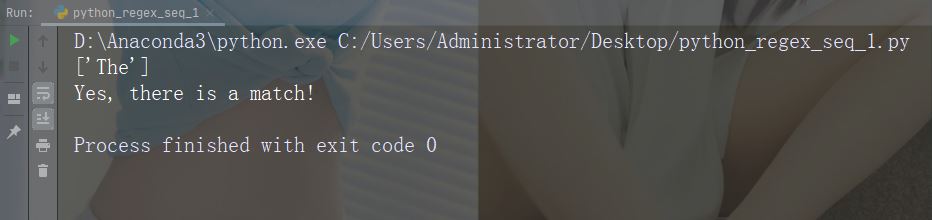
import re str = "The rain in Spain" #Check if "ain" is present at the end of a WORD: x = re.findall(r"ain\b", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
Zeichen: s
描述:返回字符串包含空白字符的匹配项
示例:“\s”
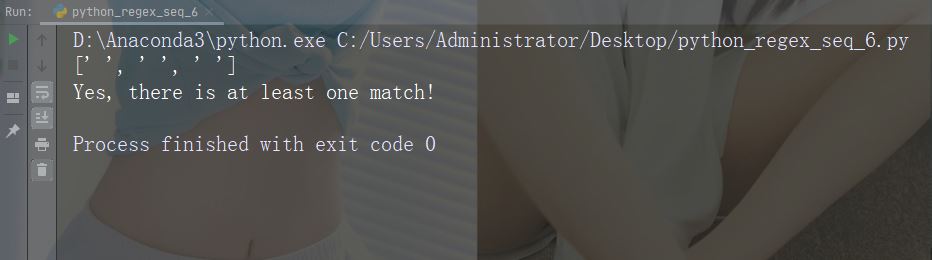
import re str = "The rain in Spain" #Return a match at every white-space character: x = re.findall("\s", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
字符:\S
描述:返回字符串不包含空白字符的匹配项
示例:“\S”
import re str = "The rain in Spain" #Return a match at every NON white-space character: x = re.findall("\S", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
字符:\w
描述: 返回一个匹配项,其中字符串包含任何单词字符 (从 a 到 Z 的字符,从 0 到 9 的数字和下划线 _ 字符)
示例:“\w”
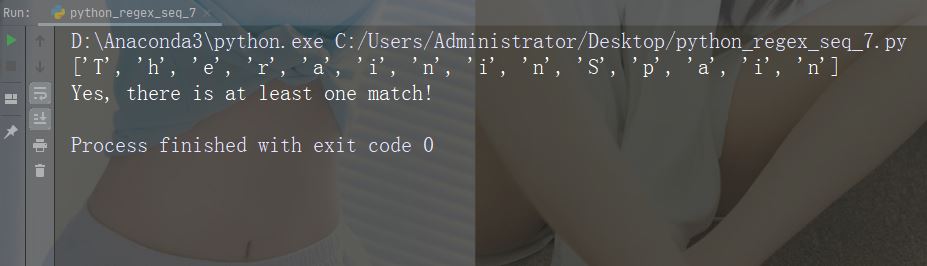
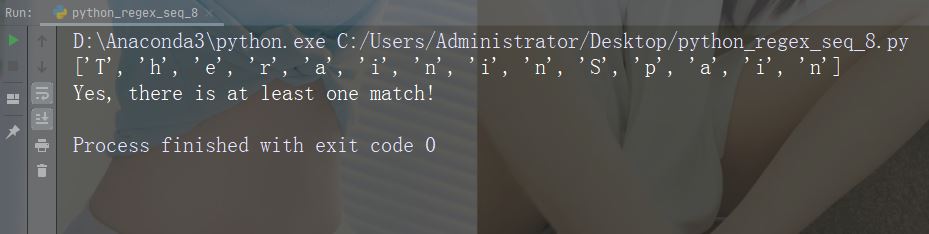
import re str = "The rain in Spain" #Return a match at every word character (characters from a to Z, digits from 0-9, and the underscore _ character): x = re.findall("\w", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
字符:\W
描述:返回一个匹配项,其中字符串不包含任何单词字符
示例:“\W”
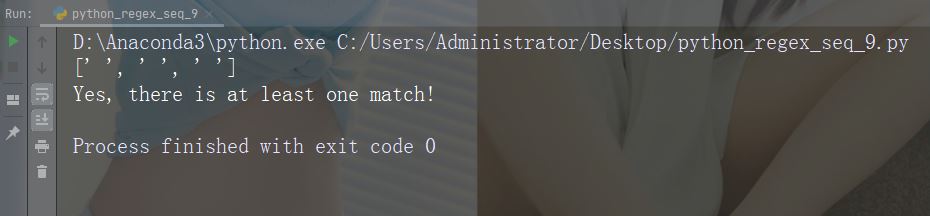
import re str = "The rain in Spain" #Return a match at every NON word character (characters NOT between a and Z. Like "!", "?" white-space etc.): x = re.findall("\W", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
字符:\Z
描述:如果指定的字符位于字符串的末尾,则返回匹配项 。
示例:“Spain\Z”
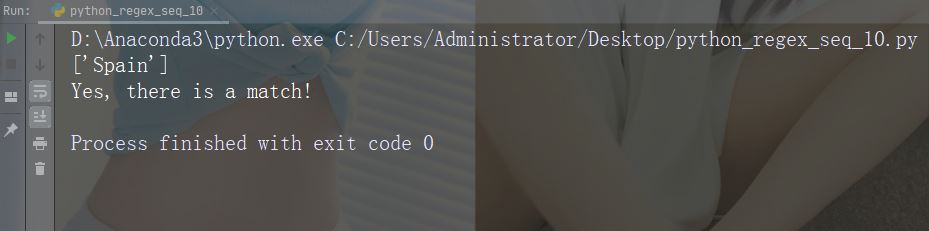
import re str = "The rain in Spain" #Check if the string ends with "Spain": x = re.findall("Spain\Z", str) print(x) if (x): print("Yes, there is a match!") else: print("No match")
运行示例
集合(Set)是一对方括号 [] 内的一组字符,具有特殊含义。
字符:[arn]
描述:返回一个匹配项,其中存在指定字符(a,r 或 n)之一
示例
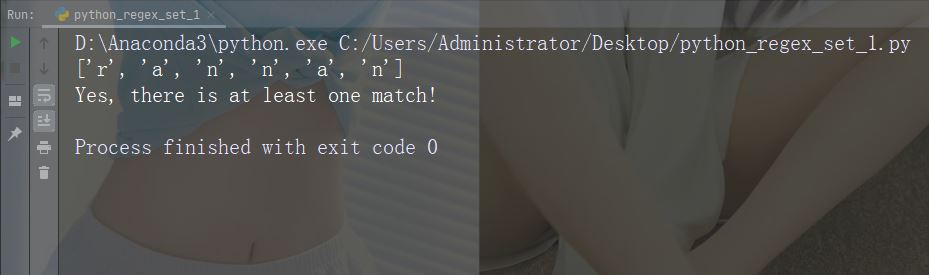
import re str = "The rain in Spain" #Check if the string has any a, r, or n characters: x = re.findall("[arn]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
字符:[a-n]
描述:返回字母顺序 a 和 n 之间的任意小写字符匹配项
示例
import re str = "The rain in Spain" #Check if the string has any characters between a and n: x = re.findall("[a-n]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
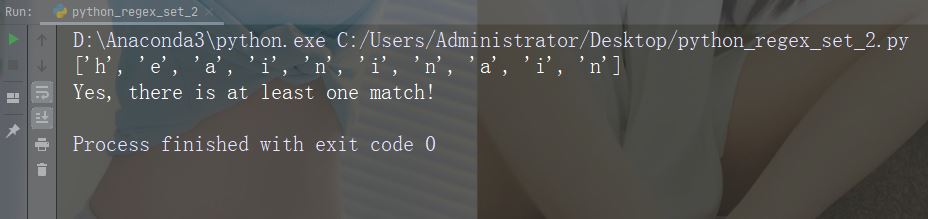
字符:[^arn]
描述:返回除 a、r 和 n 之外的任意字符的匹配项
示例
import re str = "The rain in Spain" #Check if the string has other characters than a, r, or n: x = re.findall("[^arn]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
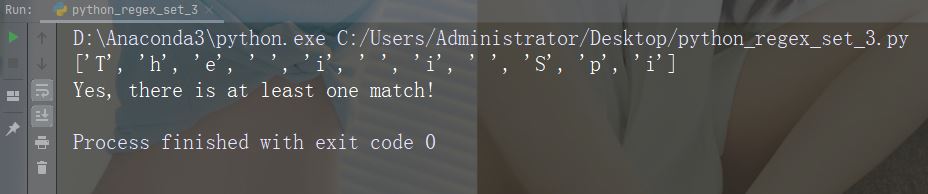
字符:[0123]
描述:返回存在任何指定数字(0、1、2 或 3)的匹配项
示例
import re str = "The rain in Spain" #Check if the string has any 0, 1, 2, or 3 digits: x = re.findall("[0123]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
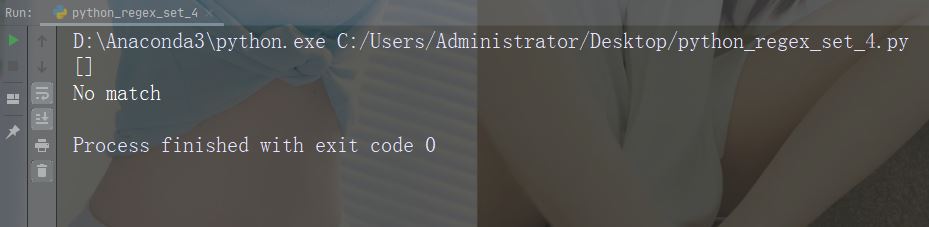
字符:[0-9]
描述:返回 0 与 9 之间任意数字的匹配
示例
import re str = "8 times before 11:45 AM" #Check if the string has any digits: x = re.findall("[0-9]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
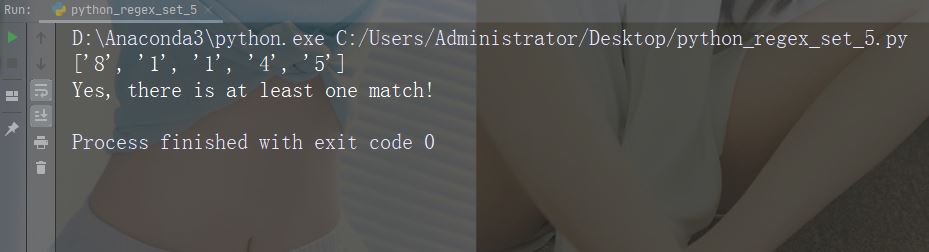
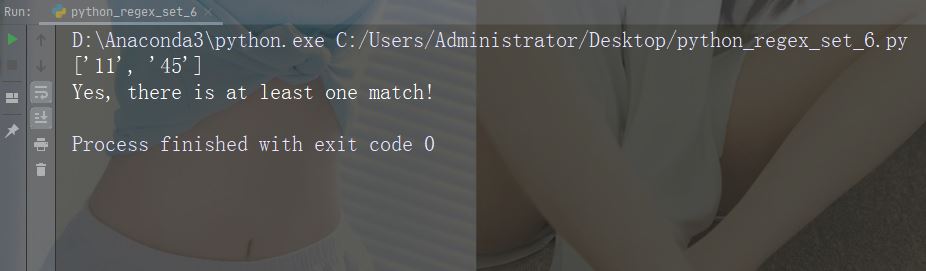
字符:[0-5][0-9]
描述:返回介于 0 到 9 之间的任何数字的匹配项
示例
import re str = "8 times before 11:45 AM" #Check if the string has any two-digit numbers, from 00 to 59: x = re.findall("[0-5][0-9]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
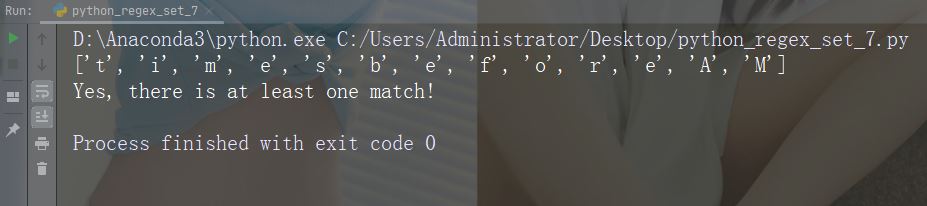
字符:[a-zA-Z]
描述:返回字母顺序 a 和 z 之间的任何字符的匹配,小写或大写
示例
import re str = "8 times before 11:45 AM" #Check if the string has any characters from a to z lower case, and A to Z upper case: x = re.findall("[a-zA-Z]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
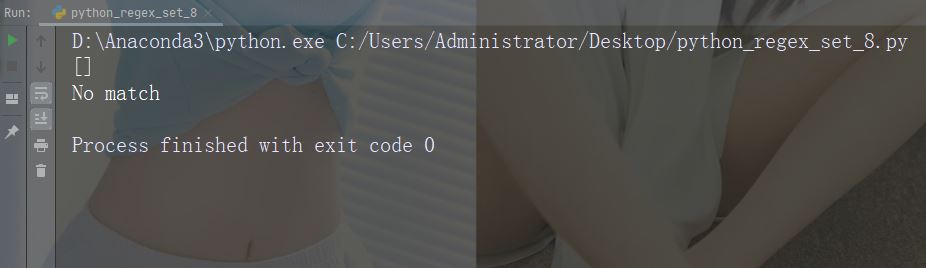
字符:[+]
描述:在集合中,+、*、.、|、()、$、{} 没有特殊含义,因此 [+] 表示:返回字符串中任何 + 字符的匹配项。
示例
import re str = "8 times before 11:45 AM" #Check if the string has any + characters: x = re.findall("[+]", str) print(x) if (x): print("Yes, there is at least one match!") else: print("No match")
运行示例
findall() 函数返回包含所有匹配项的列表。
实例
打印所有匹配的列表
import re str = "China is a great country" x = re.findall("a", str) print(x)
运行实例
这个列表以被找到的顺序包含匹配项。
如果未找到匹配项,则返回空列表。
实例
如果未找到匹配,则返回空列表:
import re str = "China is a great country" x = re.findall("USA", str) print(x)
运行实例
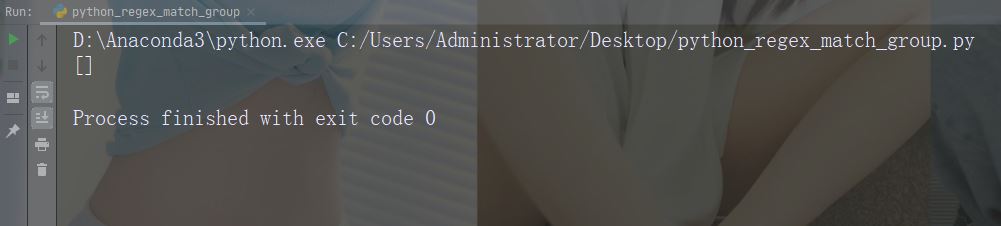
search() 函数搜索字符串中的匹配项,如果存在匹配则返回 Match 对象。
如果有多个匹配,则仅返回首个匹配项。
实例
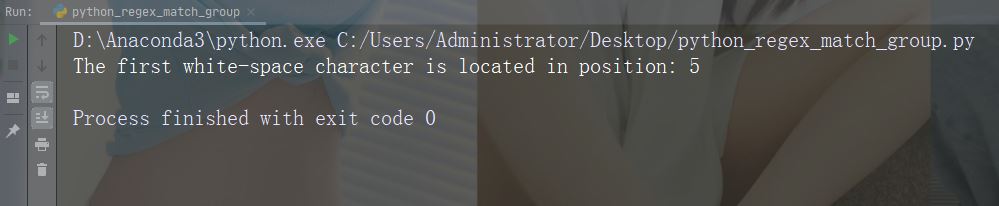
在字符串中搜索第一个空白字符
import re str = "China is a great country" x = re.search("\s", str) print("The first white-space character is located in position:", x.start())
运行实例
如果未找到匹配,则返回值 None:
实例
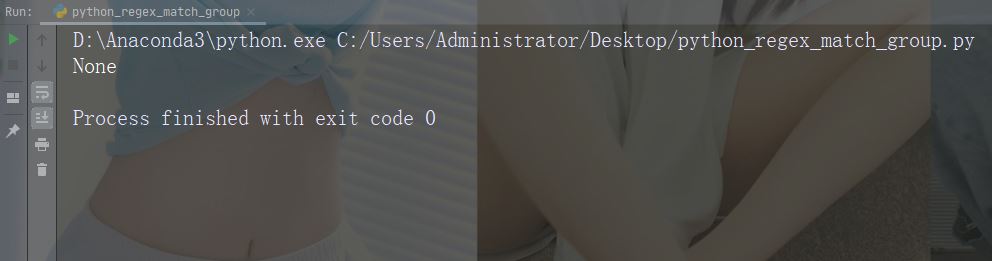
进行不返回匹配的检索
import re str = "China is a great country" x = re.search("USA", str) print(x)
运行实例
split() 函数返回一个列表,其中字符串在每次匹配时被拆分。
实例
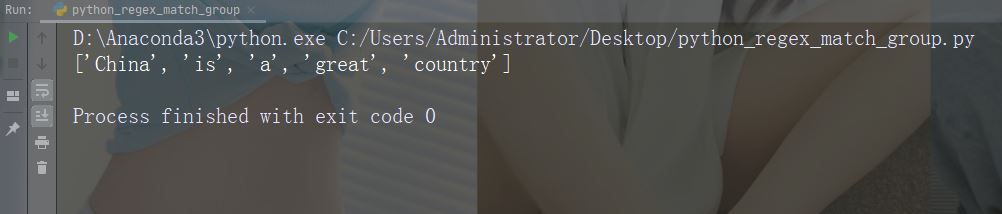
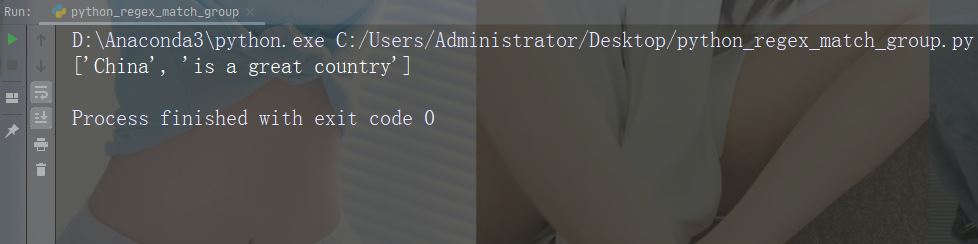
在每个空白字符处进行拆分
import re str = "China is a great country" x = re.split("\s", str) print(x)
运行实例
可以通过指定 maxsplit 参数来控制出现次数:
实例
仅在首次出现时拆分字符串:
import re str = "China is a great country" x = re.split("\s", str, 1) print(x)
运行实例
sub() 函数把匹配替换为您选择的文本
实例
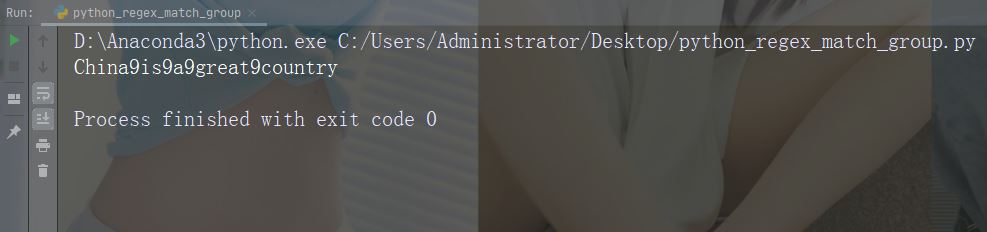
用数字 9 替换每个空白字符
import re str = "China is a great country" x = re.sub("\s", "9", str) print(x)
运行实例
可以通过指定 count 参数来控制替换次数:
实例
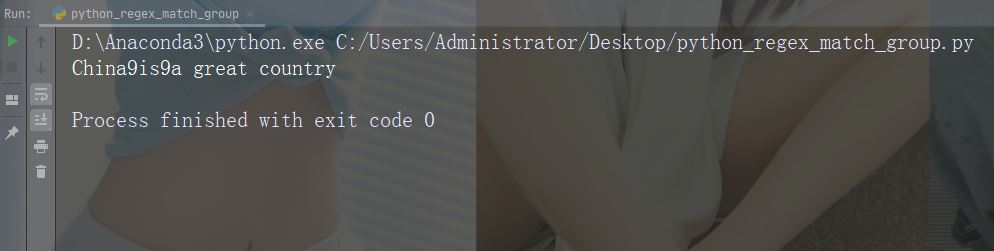
替换前两次出现
import re str = "China is a great country" x = re.sub("\s", "9", str, 2) print(x)
运行实例
Match 对象是包含有关搜索和结果信息的对象。
注释:如果没有匹配,则返回值 None,而不是 Match 对象。
实例
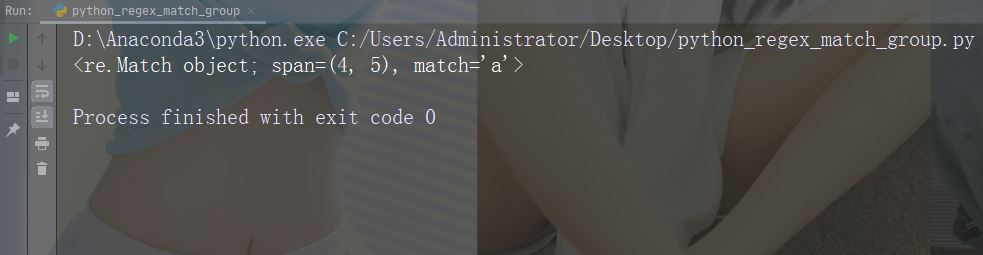
执行会返回 Match 对象的搜索:
import re str = "China is a great country" x = re.search("a", str) print(x) # 将打印一个对象
运行实例
Match 对象提供了用于取回有关搜索及结果信息的属性和方法:
span()返回的元组包含了匹配的开始和结束位置
.string返回传入函数的字符串
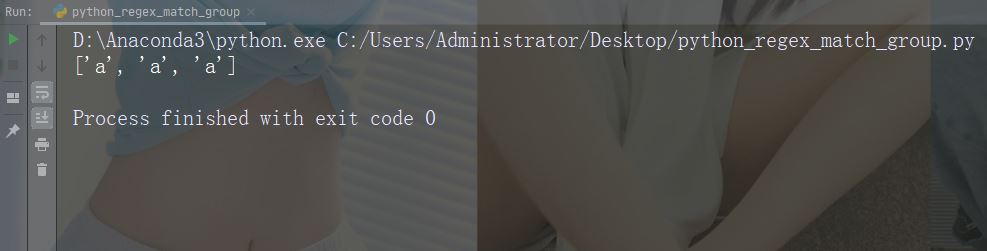
group()返回匹配的字符串部分
实例
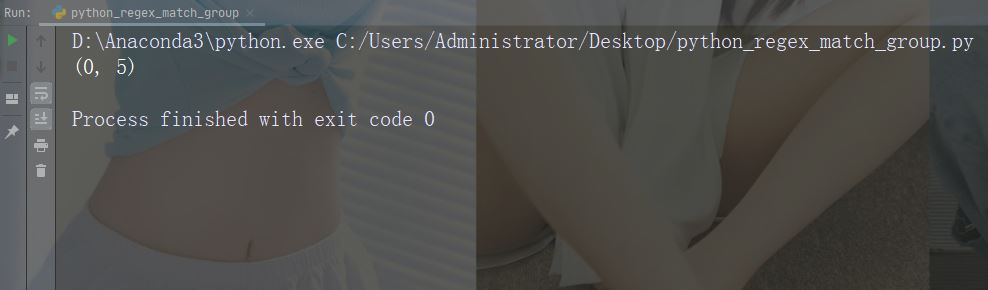
打印首个匹配出现的位置(开始和结束位置)。
正则表达式查找以大写 “C” 开头的任何单词:
import re str = "China is a great country" x = re.search(r"\bC\w+", str) print(x.span())
运行实例
实例
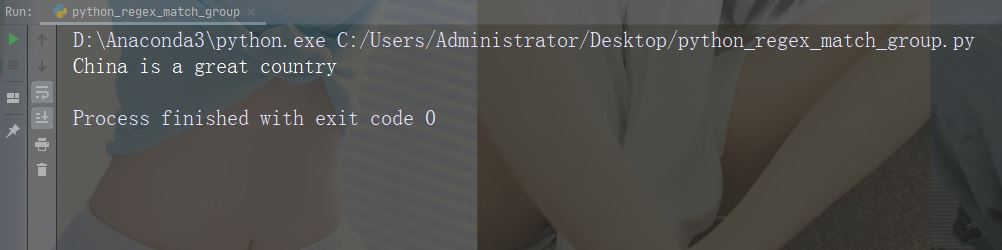
打印传入函数的字符串
import re str = "China is a great country" x = re.search(r"\bC\w+", str) print(x.string)
运行实例
实例
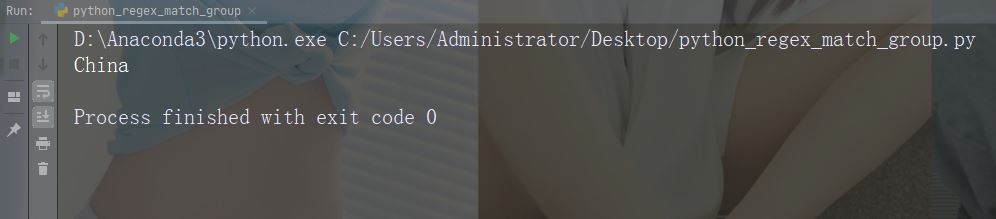
打印匹配的字符串部分
正则表达式查找以大写 “C” 开头的任何单词:
import re str = "China is a great country" x = re.search(r"\bC\w+", str) print(x.group())
运行实例
注释:如果没有匹配项,则返回值 None,而不是 Match 对象。
Das obige ist der detaillierte Inhalt vonSo verwenden Sie den regulären RegEx-Ausdruck von Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































