




Unternehmensdigitalisierung ist in den letzten Jahren ein heißes Thema. Es bezieht sich auf den Einsatz digitaler Technologien der neuen Generation wie künstliche Intelligenz, Big Data und Cloud Computing Geschäftsmodell zu transformieren und dadurch neues Wachstum im Unternehmensgeschäft zu fördern. Die Unternehmensdigitalisierung umfasst im Allgemeinen die Digitalisierung des Geschäftsbetriebs und die Digitalisierung der Unternehmensführung. Diese gemeinsame Nutzung führt hauptsächlich die Digitalisierung der Unternehmensführungsebene ein.
Informationsdigitalisierung bedeutet einfach ausgedrückt, Informationen auf digitale Weise zu lesen, zu schreiben, zu speichern und zu übertragen. Von den früheren Papierdokumenten bis hin zu den aktuellen elektronischen Dokumenten und Online-Zusammenarbeitsdokumenten ist die Informationsdigitalisierung im heutigen Büro zur neuen Normalität geworden. Derzeit nutzt Alibaba DingTalk Documents und Yuque Documents für die geschäftliche Zusammenarbeit, und die Zahl der Online-Dokumente hat mehr als 20 Millionen erreicht. Darüber hinaus verfügen viele Unternehmen über eigene interne Content-Communities, wie Alibabas Intranet Alibaba Internal and External Networks und die technische Community ATA. Derzeit gibt es in der ATA-Community fast 300.000 technische Artikel, die allesamt sehr wertvolle Content-Assets sind.
Die Digitalisierung von Prozessen bezeichnet den Einsatz digitaler Technologie zur Transformation von Serviceprozessen und zur Verbesserung der Serviceeffizienz. Es wird eine Menge transaktionaler Arbeit anfallen, z. B. in der internen Verwaltung, in der IT, im Personalwesen usw. Das BPMS-Prozessmanagementsystem kann Arbeitsprozesse standardisieren, einen auf Geschäftsregeln basierenden Workflow formulieren und diesen automatisch entsprechend dem Workflow ausführen, wodurch die Arbeitskosten erheblich gesenkt werden können. RPA wird hauptsächlich zur Lösung des Problems der Multisystemumschaltung im Prozess eingesetzt. Da es manuelle Klickeingabevorgänge auf der Systemschnittstelle simulieren kann, kann es verschiedene Systemplattformen verbinden. Die nächste Entwicklungsrichtung der Prozessdigitalisierung ist die Intelligenz von Prozessen, realisiert durch Konversationsroboter und RPA. Heutzutage können aufgabenbasierte Gesprächsroboter Benutzern dabei helfen, einige einfache Aufgaben innerhalb weniger Dialogrunden zu erledigen, z. B. um Urlaub zu bitten, Tickets zu buchen usw.
Ziel der Unternehmensdigitalisierung ist die Etablierung eines neuen Geschäftsmodells durch digitale Technologie. Innerhalb des Unternehmens gibt es tatsächlich einige Business Middle Offices, wie zum Beispiel die Geschäftsdigitalisierung der Einkaufsabteilung, die sich auf die Digitalisierung einer Reihe von Prozessen bezieht, von der Produktsuche über die Initiierung von Kaufanträgen, das Verfassen von Kaufverträgen, die Zahlung, die Auftragsausführung usw . Ein weiteres Beispiel ist die Geschäftsdigitalisierung des Legal Middle Office. Am Beispiel des Vertragszentrums wird die Digitalisierung des gesamten Vertragslebenszyklus von der Vertragsgestaltung über die Vertragsprüfung bis hin zur Vertragsunterzeichnung und Vertragserfüllung realisiert.
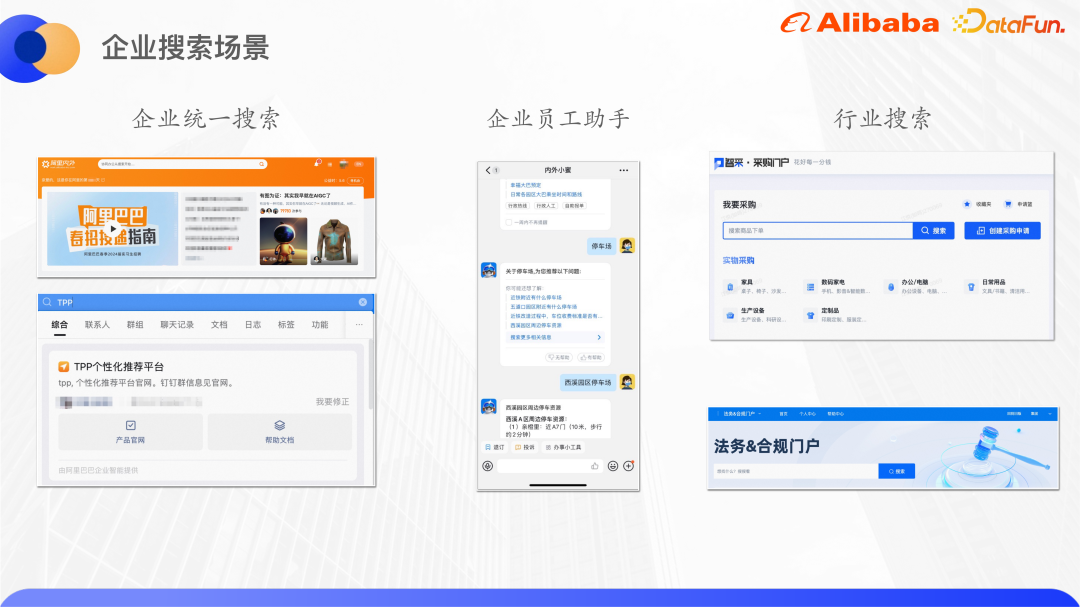
Die durch die Digitalisierung erzeugten riesigen Datenmengen und Dokumente werden in verschiedenen Geschäftssystemen verstreut sein. Daher ist eine intelligente Unternehmenssuchmaschine erforderlich, die den Mitarbeitern hilft, die gesuchten Informationen schnell zu finden. Am Beispiel der Alibaba Group lauten die Hauptszenarien für die Unternehmenssuche wie folgt:
(1) Einheitliche Suche, auch als umfassende Suche bekannt, die Informationen aus mehreren Inhaltsseiten zusammenfasst, darunter DingTalk-Dokumente, Yuque-Dokumentation, ATA usw. Die Eingänge zur einheitlichen Suche befinden sich derzeit in Alibabas internem Netzwerk Alibaba Internal und External sowie in der Nur-Mitarbeiter-Version von DingTalk. Der kombinierte Datenverkehr dieser beiden Eingänge erreicht etwa 140 QPS, was in einem ToB-Szenario einen sehr hohen Datenverkehr darstellt.
(2) Der Unternehmensmitarbeiterassistent bezieht sich auf Xiaomi innerhalb und außerhalb. Er ist ein intelligenter Serviceroboter für Alibabas interne Mitarbeiter. Er vereint Unternehmenswissen mit Frage- und Antwortdiensten in den Bereichen Personalwesen, Verwaltung, IT und anderen Bereichen. Die Fast-Service-Kanäle, darunter der DingTalk-Eingang und einige Plug-in-Eingänge, stehen insgesamt rund 250.000 Menschen offen und gehören auch zu den Verkehrsstandorten der Gruppe.
(3) Die Branchensuche entspricht der im vorherigen Kapitel erwähnten Digitalisierung des Geschäfts. Beispielsweise verfügt der Einkauf über ein Portal namens Procurement Mall. Käufer können in der Procurement Mall suchen, Produkte auswählen und Beschaffungsanträge stellen zum E-Commerce, aber der Nutzer ist auch der Käufer des Unternehmens; das Legal-Compliance-Unternehmen verfügt auch über ein entsprechendes Portal, in dem Jurastudenten nach Verträgen suchen und eine Reihe von Aufgaben wie Vertragsgestaltung, Genehmigung usw. durchführen können. und unterschreiben.

Im Allgemeinen verfügt jedes Geschäftssystem oder jede Inhaltsseite im Unternehmen über ein eigenes Suchgeschäftssystem, das voneinander isoliert werden muss Phänomen der Informationsinseln. Wenn ein technischer Klassenkamerad beispielsweise auf ein technisches Problem stößt, kann er zunächst zu ATA gehen, um nach technischen Artikeln zu diesem Problem zu suchen. Wenn er diese nicht finden kann, sucht er dann nach ähnlichen Inhalten in Zhibo, DingTalk Documents und Yuque Documents , was insgesamt vier oder fünf Suchvorgänge erfordert. Dieses Suchverhalten ist zweifellos sehr ineffizient. Daher hoffen wir, diese Inhalte in einer einheitlichen Unternehmenssuche zusammenzuführen, sodass alle relevanten Informationen mit nur einer Suche abgerufen werden können.
Darüber hinaus müssen Branchensuchen mit Geschäftsattributen grundsätzlich voneinander isoliert werden. Beispielsweise sind die Benutzer des Beschaffungszentrums die Käufer der Gruppe, und die Benutzer des Vertragszentrums sind die Rechtsangelegenheiten der Gruppe. Die Anzahl der Benutzer in diesen beiden Suchszenarien ist sehr gering, sodass das Benutzerverhalten relativ spärlich ist auf dem Empfehlungsalgorithmus, der Benutzerverhaltensdaten verwendet. Der Effekt wird stark reduziert. Auch in den Bereichen Beschaffung und Recht gibt es nur sehr wenige annotierte Daten, da für die Annotation Fachleute erforderlich sind und die Kosten hoch sind, sodass es schwierig ist, qualitativ hochwertige Datensätze zu sammeln.
Das letzte Problem ist das Übereinstimmungsproblem zwischen Abfrage und Dokument. Die Länge der gesuchten Abfrage beträgt im Grunde nur ein Dutzend Wörter, es fehlt der Kontext und die semantischen Informationen sind nicht ausreichend Für das Verständnis kurzer Texte gibt es in der Wissenschaft viele verwandte Forschungsarbeiten. Bei den durchsuchten Elementen handelt es sich grundsätzlich um lange Dokumente mit einer Anzahl von Hunderten bis Tausenden Zeichen. Auch das Verstehen und Darstellen des Inhalts langer Dokumente ist eine sehr schwierige Aufgabe.
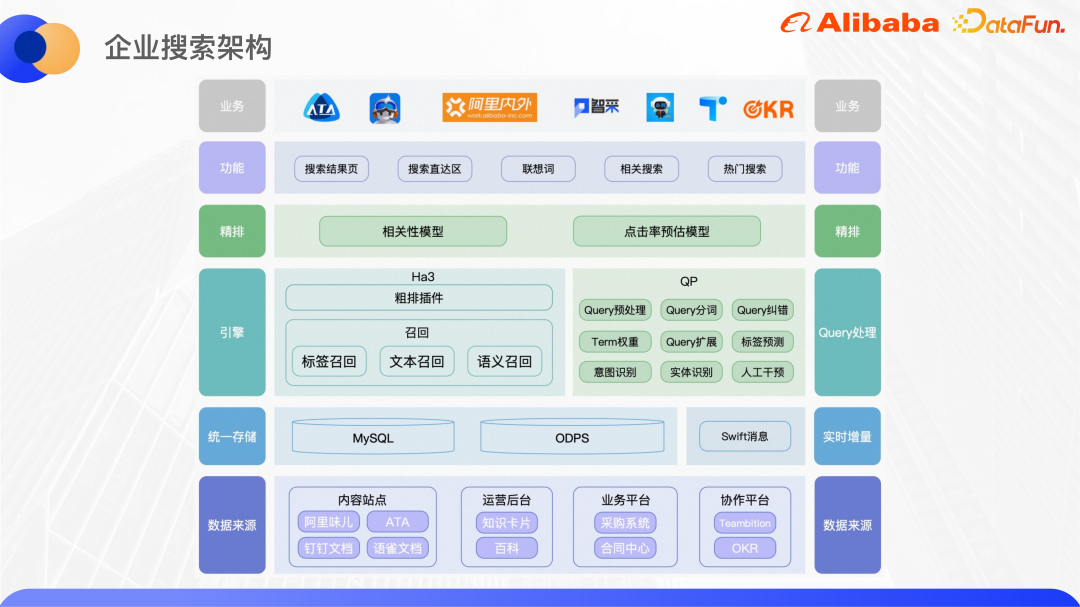
Das obige Bild zeigt die grundlegende Architektur unserer aktuellen Unternehmenssuche. Hier stellen wir hauptsächlich den einheitlichen Suchteil vor.
Derzeit ist die einheitliche Suche mit mehr als 40 großen und kleinen Inhaltsseiten wie ATA, DingTalk Documents und Yuque Documents verbunden. Alibabas selbst entwickelte Ha3-Engine wird für den Rückruf und die grobe Sortierung verwendet. Vor dem Rückruf wird der QP-Dienst des Algorithmus aufgerufen, um die Abfrage des Benutzers zu analysieren und Abfragesegmentierung, Fehlerkorrektur, Termgewichtung, Abfrageerweiterung, NER-Absichtserkennung usw. bereitzustellen. Gemäß den QP-Ergebnissen und der Geschäftslogik wird die Abfragezeichenfolge auf der Engine-Seite zum Abruf zusammengestellt. Das auf Ha3 basierende grobe Sortier-Plug-in kann einige leichte Sortiermodelle wie GBDT usw. unterstützen. In der Feinranking-Phase können komplexere Modelle zum Sortieren verwendet werden. Das Korrelationsmodell wird hauptsächlich verwendet, um die Genauigkeit der Suche sicherzustellen, und das Klickraten-Schätzmodell optimiert die Klickrate direkt.
Neben der Suchsortierung sind auch andere Suchperipheriefunktionen integriert, z. B. der Suchdirektbereich des Such-Dropdown-Felds, zugehörige Wörter, verwandte Suchen, beliebte Suchen usw. Derzeit sind die von der oberen Ebene unterstützten Dienste hauptsächlich die einheitliche Suche innerhalb und außerhalb von Alibaba und Alibaba DingTalk, die vertikale Suche nach Beschaffungs- und Rechtsangelegenheiten sowie das Abfrageverständnis des ATA Teambition OKR-Systems.
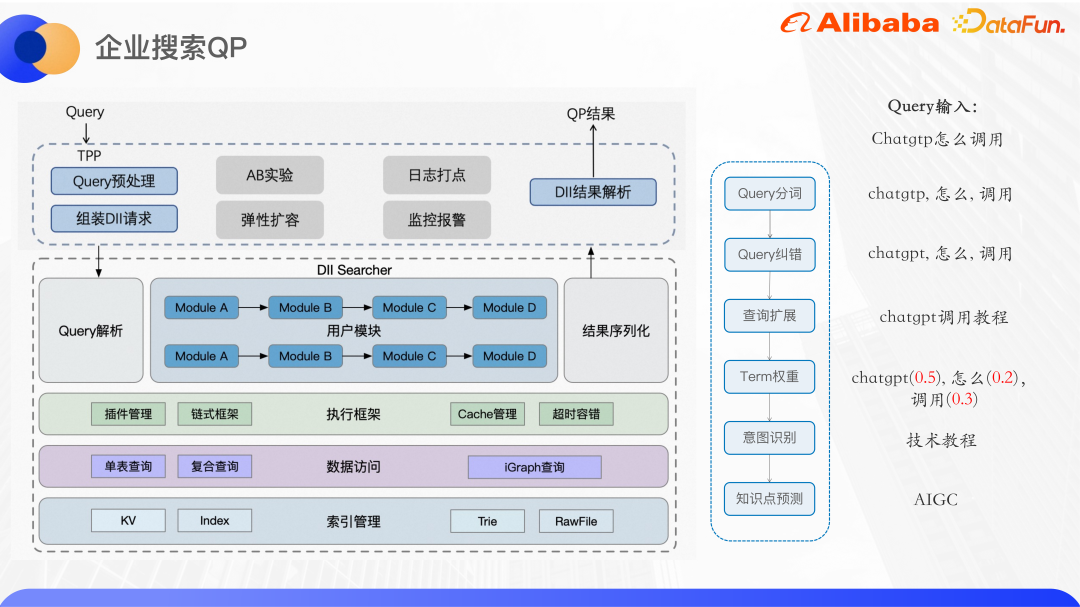
Das obige Bild zeigt die allgemeine Architektur der Unternehmenssuche QP. Der QP-Dienst wird auf einer Algorithmus-Onlinedienstplattform namens DII bereitgestellt. Die DII-Plattform kann die Erstellung und Abfrage von KV-Tabellen und Indextabellenindizes unterstützen. Es handelt sich um ein Kettendienst-Framework, und komplexe Geschäftslogik muss in relativ unabhängige und zusammenhängende Geschäftsmodule aufgeteilt werden. Beispielsweise ist der Such-QP-Dienst innerhalb und außerhalb von Alibaba in mehrere Funktionsmodule wie Wortsegmentierung, Fehlerkorrektur, Abfrageerweiterung, Begriffsgewichtung und Absichtserkennung unterteilt. Der Vorteil des Chain-Frameworks besteht darin, dass es die gemeinsame Entwicklung mehrerer Personen ermöglicht. Jede Person ist für die Entwicklung ihres eigenen Moduls verantwortlich, solange die vor- und nachgelagerten Schnittstellen vereinbart sind und verschiedene QP-Dienste dasselbe Modul wiederverwenden können. Reduzierung der Codeduplizierung. Darüber hinaus wird eine Schicht auf den zugrunde liegenden Algorithmusdienst gewickelt, um eine TPP-Schnittstelle zur Außenwelt bereitzustellen. TPP ist eine ausgereifte Algorithmus-Empfehlungsplattform innerhalb von Alibaba. Sie kann problemlos AB-Experimente und elastische Erweiterungen durchführen. Die Protokollverwaltung sowie die Überwachungs- und Alarmmechanismen sind ebenfalls sehr ausgereift.
Führen Sie eine Abfragevorverarbeitung auf der TPP-Seite durch, stellen Sie dann die DII-Anforderung zusammen, rufen Sie den DII-Algorithmusdienst auf, analysieren Sie das Ergebnis nach Erhalt und geben Sie es schließlich an den Anrufer zurück.
Als Nächstes stellen wir die Arbeit zur Abfrageabsichtserkennung in zwei Unternehmensszenarien vor.
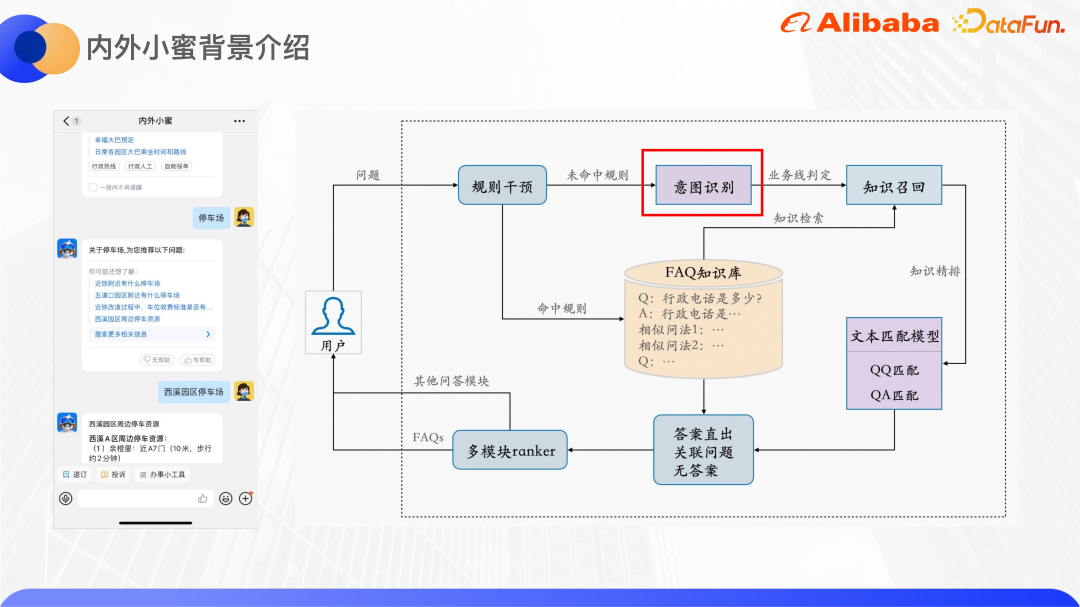
Die unterste Ebene des internen und externen Xiaomi basiert auf der Cloud-Xiaomi-Q&A-Engine, die von der Damo Academy eingeführt wurde und FAQ-Fragen und Antworten mit mehreren Runden unterstützen kann Fragen und Antworten und Fragen und Antworten zum Wissensgraphen. Die rechte Seite des Bildes oben zeigt den allgemeinen Rahmen der FAQ-Frage- und Antwort-Engine.
Nachdem der Benutzer eine Abfrage eingegeben hat, gibt es ein Regeleingriffsmodul, das es Unternehmen und Betrieben hauptsächlich ermöglicht, einige Regeln festzulegen. Wenn die Regel erfüllt ist, wird die festgelegte Antwort direkt zurückgegeben nicht getroffen, Algorithmus verlassen. Das Absichtserkennungsmodul prognostiziert Benutzeranfragen an den entsprechenden Geschäftsbereich. In der FAQ-Wissensdatenbank jedes Geschäftsbereichs gibt es viele QA-Paare, und jede Frage wird mit einigen ähnlichen Fragen konfiguriert. Verwenden Sie Query, um den Kandidatensatz von QA-Paaren in der Wissensdatenbank abzurufen, und verwenden Sie dann das Textabgleichsmodul, um die QA-Paare zu verfeinern. Basierend auf der Modellbewertung wird beurteilt, ob die Antwort richtig ist, verwandte Fragen empfohlen werden oder vorhanden sind ist keine Antwort. Neben der FAQ-Frage-und-Antwort-Engine wird es auch andere Frage-und-Antwort-Engines wie aufgabenbasierte Frage-und-Antwort-Engines und Wissensgraph-Frage-und-Antwort-Engines geben. Daher wird schließlich ein Multimodul-Ranker entwickelt, um auszuwählen, welche Engine angezeigt werden soll die Antwort an den Benutzer.
Im Folgenden liegt der Schwerpunkt auf dem Modul zur Absichtserkennung.
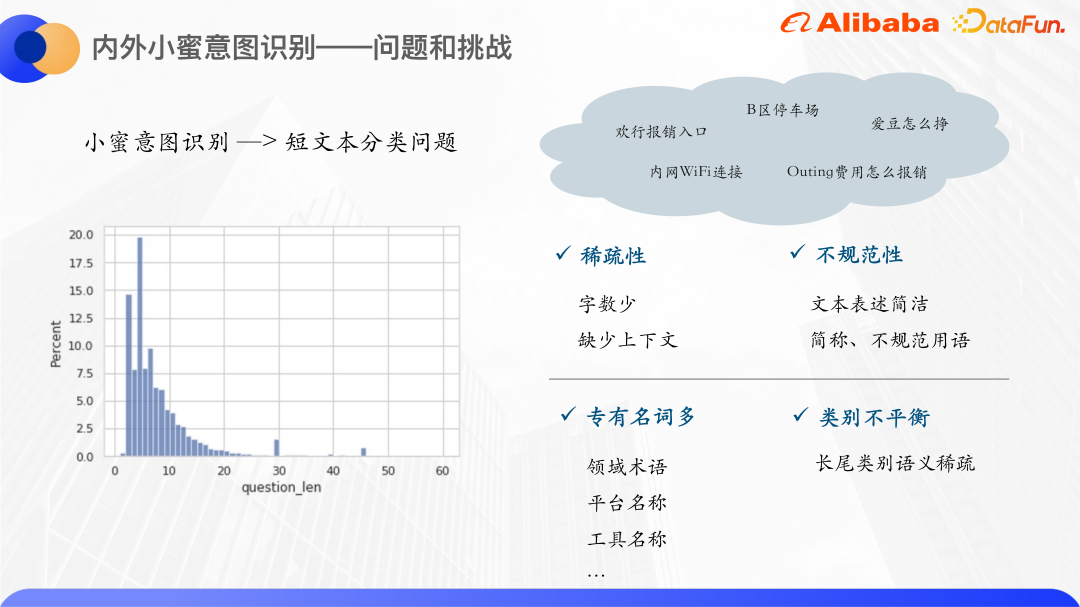
Beim Zählen der Benutzeranfragen von Xiaomi innerhalb und außerhalb des letzten Jahres haben wir festgestellt, dass sich die meisten Benutzeranfragewörter auf einen Bereich zwischen 0 und 20 konzentrieren und mehr als 80 % der Suchanfragewörter ausmachen liegen innerhalb von 10. Daher ist die Absichtserkennung von Xiaomi innen und außen ein Problem der Kurztextklassifizierung. Die Anzahl der Kurztexte ist sehr gering. Wenn sie also durch das traditionelle Vektorraummodell dargestellt werden, ist der Vektorraum spärlich. Und im Allgemeinen sind kurze Textausdrücke nicht sehr standardisiert, es gibt viele Abkürzungen und unregelmäßige Begriffe, sodass es mehr OOV-Phänomene gibt.
Ein weiteres Merkmal von Xiaomis Kurztextabfrage ist, dass es viele Eigennamen gibt, normalerweise interne Plattform- und Toolnamen, wie Huanxing, Idol usw. Die Texte dieser Eigennamen selbst verfügen nicht über kategoriebezogene semantische Informationen, sodass es schwierig ist, effektive semantische Darstellungen zu erlernen. Daher haben wir darüber nachgedacht, dieses Problem durch Wissenserweiterung zu lösen.
Bei der allgemeinen Wissenserweiterung werden Open-Source-Wissensgraphen verwendet, aber die Eigennamen innerhalb des Unternehmens können die entsprechenden Entitäten im Open-Source-Wissensgraphen nicht finden, daher suchen wir nach Wissen aus unserem Inneren. Es kommt vor, dass Alibaba über eine Wissenskarten-Suchfunktion verfügt, die in hohem Maße mit dem Bereich Xiaomi in Verbindung steht. Hier können beispielsweise Wissenskarten von Huanxing und Idou gefunden werden Wissenskarten werden als Wissensquellen verwendet.
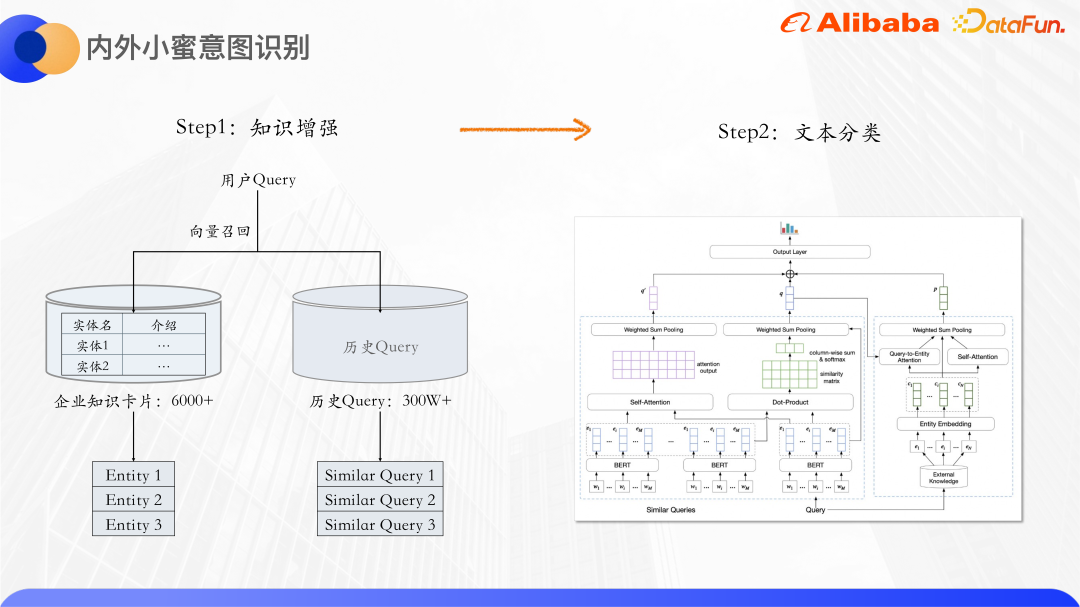
Der erste ist die Wissenserweiterung. Insgesamt gibt es mehr als 6.000 Wissenskarten für Unternehmen. Die damit verbundenen Wissenskarten nutzen auch historische Abfragen, da es viele ähnliche Abfragen gibt, z. B. Intranet-WLAN-Verbindung, WLAN-Intranet-Verbindung usw. Ähnliche Abfragen können sich gegenseitig ergänzen semantische Informationen, was das Problem der Knappheit von Texten weiter entschärft. Zusätzlich zu den Wissenskartenentitäten werden ähnliche Abfragen abgerufen und die ursprünglichen Abfragen zur Klassifizierung an das Textklassifizierungsmodell gesendet.
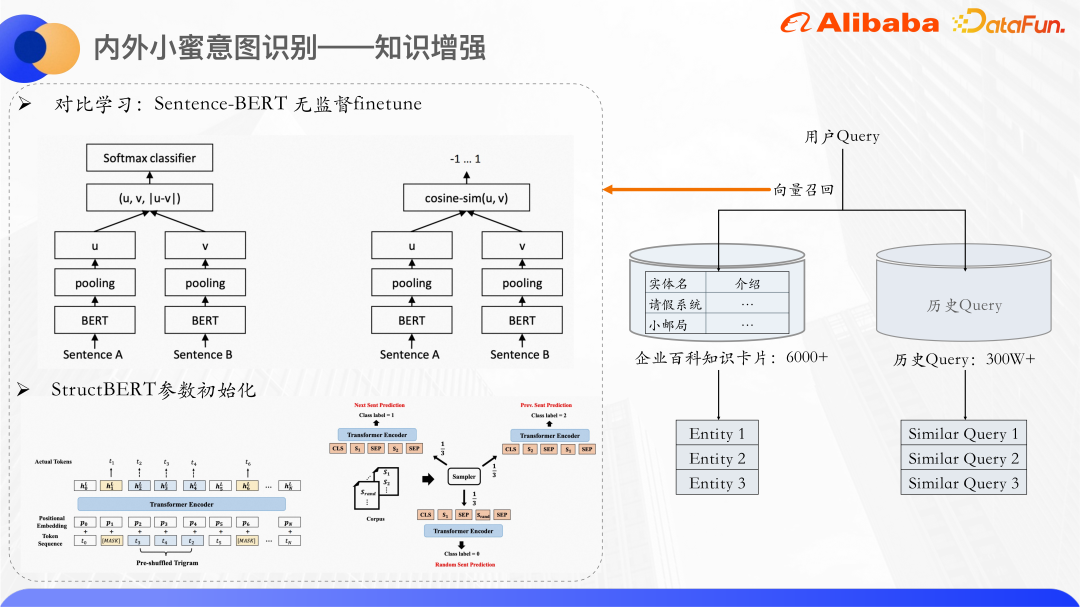
Verwenden Sie den Vektorrückruf, um Entitäten und ähnliche Abfragen von Wissenskarten abzurufen. Verwenden Sie Bert, um die konkrete Menge der Textbeschreibung der Abfrage bzw. der Wissenskarte zu berechnen. Im Allgemeinen werden die CLS-Vektoren von Bert nicht direkt als Satzdarstellungen verwendet. In vielen Artikeln wird auch erwähnt, dass die direkte Verwendung von CLS-Vektoren als Satzdarstellungen zu schlechten Ergebnissen führt, da die von Bert ausgegebenen Vektoren Probleme mit der Ausdrucksverschlechterung aufweisen und nicht für die direkte Verwendung geeignet sind führt eine unbeaufsichtigte Ähnlichkeitsberechnung durch und nutzt daher die Idee des kontrastiven Lernens, um ähnliche Stichproben näher zusammenzubringen und unterschiedliche Stichproben so gleichmäßig wie möglich zu verteilen.
Insbesondere ist ein Satz-Bert eine Feinabstimmung des Datensatzes, und seine Modellstruktur und Trainingsmethode können bessere Satzvektordarstellungen erzeugen. Es handelt sich um eine Zwei-Turm-Struktur. Die beiden Sätze werden jeweils in Bert eingegeben. Nach dem Zusammenführen der von Bert ausgegebenen verborgenen Zustände werden die Satzvektoren der beiden Sätze erhalten. Das Optimierungsziel ist hier der Verlust des vergleichenden Lernens, infoNCE.
Positives Beispiel: Geben Sie die Probe zweimal direkt in das Modell ein, aber der Ausfall dieser beiden Zeiten ist unterschiedlich, sodass die Darstellungsvektoren geringfügig unterschiedlich sind.
Negativbeispiel: Alle anderen Sätze im selben Satz.
Optimieren Sie diesen Verlust und nutzen Sie das Satz-Bert-Modell, um Satzvektoren vorherzusagen.
Wir verwenden StructBERT-Modellparameter , um den Bert-Teil hier zu initialisieren. StructBERT ist ein von der DAMO Academy vorgeschlagenes Vortrainingsmodell. Seine Modellstruktur ist die gleiche wie beim nativen BERT. Seine Kernidee besteht darin, Sprachstrukturinformationen in die Vortrainingsaufgabe zu integrieren, um die Satzvektoren und Wissenskarten der Abfrage zu erhalten. Durch Berechnung der Kosinusähnlichkeit von Vektoren werden die k ähnlichsten Wissenskarten und ähnlichen Abfragen abgerufen.
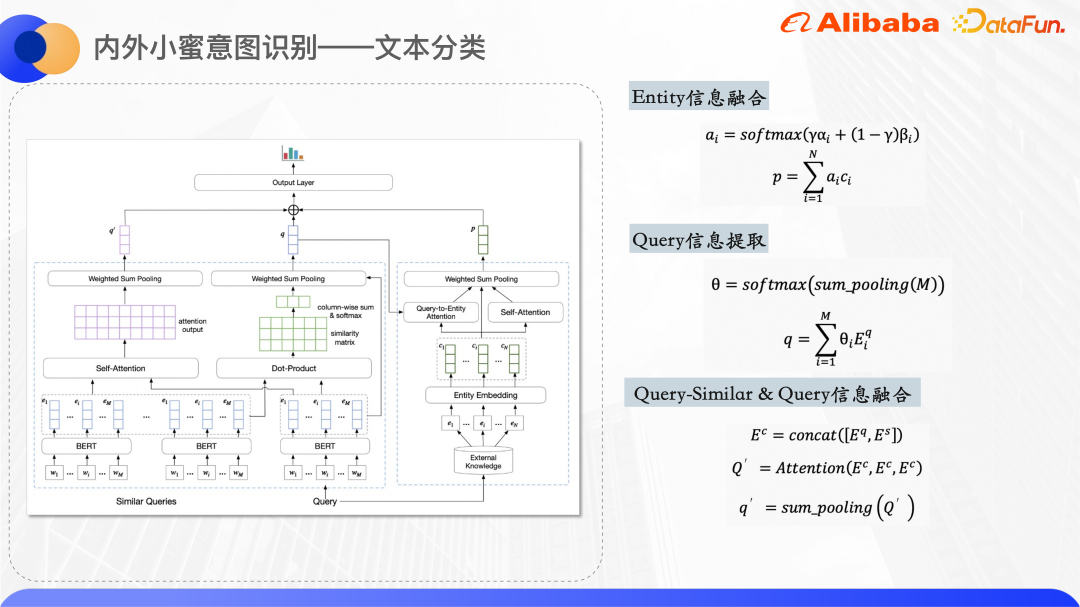
Das obige Bild ist die Modellstruktur der Textklassifizierung. Bert wird in der Codierungsebene verwendet, um die Darstellung der ursprünglichen Abfrage und der Wortvektoren ähnlicher Abfragen zu extrahieren Eine Entitäts-ID-Einbettung, die ID-Einbettung wird zufällig initialisiert.
Die rechte Seite des Modellstrukturdiagramms wird verwendet, um die von der Abfrage abgerufenen Entitäten zu verarbeiten und eine einheitliche Vektordarstellung der Entitäten zu erhalten. Da der kurze Text selbst relativ vage ist, weisen die zurückgerufenen Wissenskartenentitäten auch ein gewisses Maß an Rauschen auf. Durch die Verwendung von zwei Aufmerksamkeitsmechanismen kann das Modell den richtigen Entitäten mehr Aufmerksamkeit schenken. Eine davon ist die Abfrage-zu-Entitäts-Aufmerksamkeit (Query-to-Entity Attention), die darauf abzielt, dass das Modell den Entitäten, die mit der Abfrage in Zusammenhang stehen, mehr Aufmerksamkeit schenkt. Das andere ist die Selbstaufmerksamkeit der Entität selbst, die das Gewicht einander ähnlicher Entitäten erhöhen und das Gewicht verrauschter Entitäten verringern kann. Durch die Kombination der beiden Aufmerksamkeitsgewichtungssätze wird eine Vektordarstellung der endgültigen Entität erhalten.
Die linke Seite des Modellstrukturdiagramms dient zur Verarbeitung der ursprünglichen Abfrage und ähnlicher Abfragen, da beobachtet wird, dass die überlappenden Wörter ähnlicher Abfragen und ursprünglicher Abfragen das zentrale Wort von darstellen können Die Abfrage wird also bis zu einem gewissen Grad berechnet. Die Ähnlichkeitsmatrix wird für das Summenpooling ermittelt und das Gewicht jedes Wortes in der ursprünglichen Abfrage im Verhältnis zur ähnlichen Abfrage wird ermittelt Sorgen Sie dafür, dass das Modell dem zentralen Wort mehr Aufmerksamkeit schenkt, und kombinieren Sie dann die ähnliche Abfrage und die ursprüngliche Abfrage. Die Wortvektoren werden miteinander verkettet, um die fusionierten semantischen Informationen zu berechnen.
Schließlich werden die oben genannten drei Vektoren zusammengefügt und die Wahrscheinlichkeit jeder Kategorie durch Vorhersage dichter Schichten ermittelt.
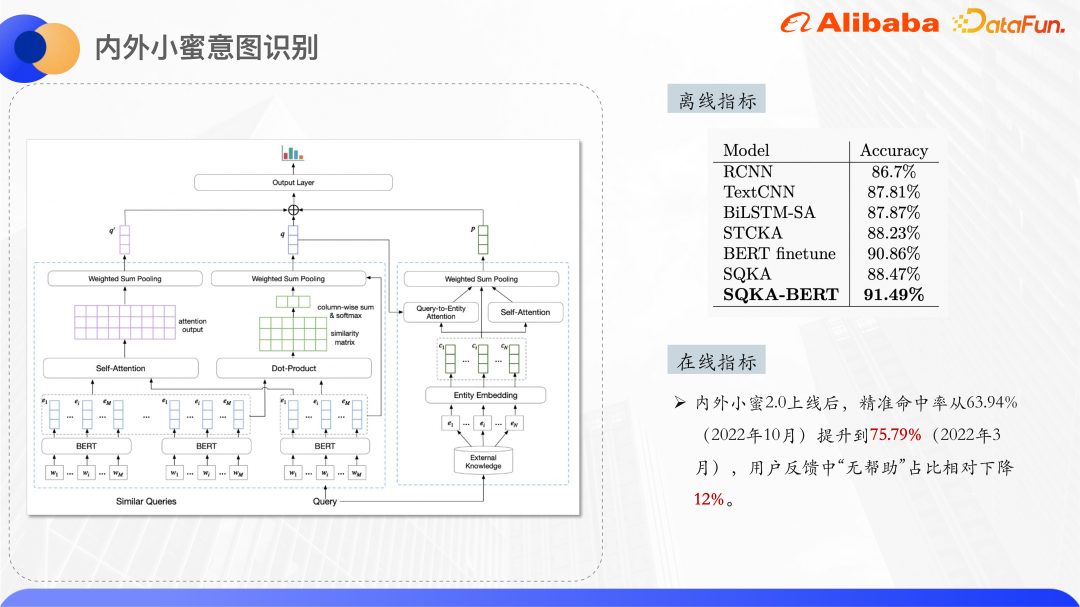
Das Obige sind die experimentellen Ergebnisse , mehr als Das Ergebnis der BERT-Feinabstimmung übertrifft alle Nicht-Bert-Modelle, auch wenn BERT nicht in der Codierungsschicht verwendet wird.
#🎜 🎜# Nehmen Sie das Einkaufszentrum als Beispiel. Das Einkaufszentrum verfügt über ein eigenes Produktkategoriesystem. Jedes Produkt wird einer Produktkategorie zugeordnet, bevor es in die Regale gestellt wird. Um die Genauigkeit der Suche in Einkaufszentren zu verbessern, ist es notwendig, die Suchanfrage einer bestimmten Kategorie zuzuordnen und dann die Suchranking-Ergebnisse entsprechend dieser Kategorie anzupassen. Sie können auch die Unterkategorienavigation und verwandte Suchvorgänge auf der Benutzeroberfläche anzeigen die Kategorieergebnisse.
Kategorievorhersage erfordert manuell gekennzeichnete Datensätze, aber im Beschaffungsbereich sind die Kosten für die Kennzeichnung aus Sicht relativ hoch der Klassifizierung kleiner Stichproben, um dieses Problem zu lösen.
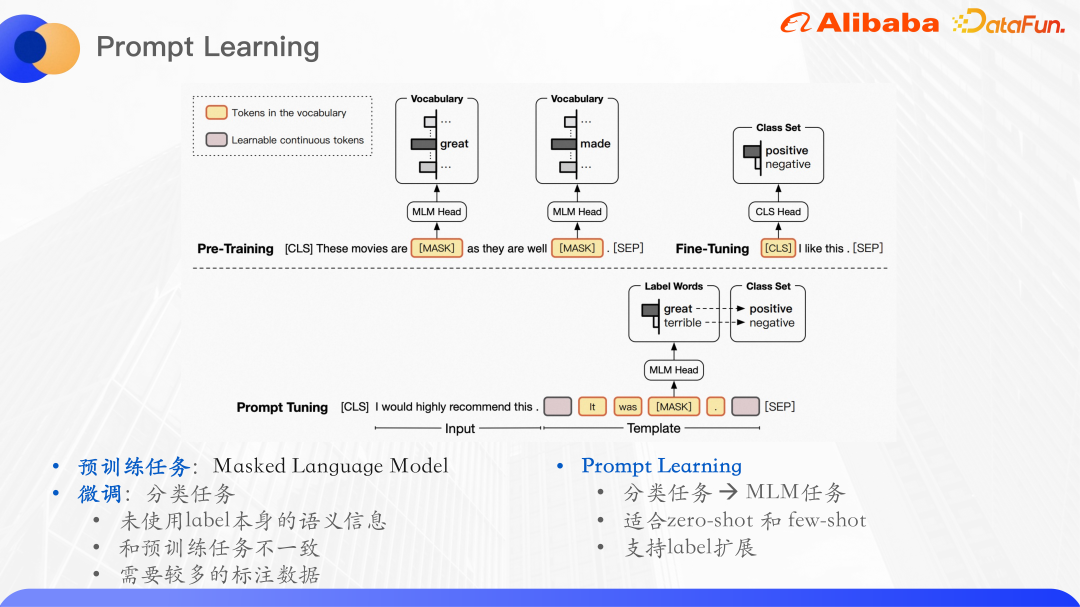
Vorab trainiertes Modell in NLP Aufgaben Es hat starke Sprachverständnisfähigkeiten gezeigt. Das typische Verwendungsparadigma besteht darin, zunächst einen großen, unbeschrifteten Datensatz vorab zu trainieren und dann eine Feinabstimmung an überwachten nachgelagerten Aufgaben durchzuführen. Berts Vortrainingsaufgabe besteht beispielsweise hauptsächlich aus einem Maskensprachmodell. Dies bedeutet, dass ein Teil der Wörter in einem Satz zufällig ausgeblendet, in das ursprüngliche Modell eingegeben und dann die Wörter im Maskenteil vorhergesagt wird, um die Wahrscheinlichkeit zu maximieren Worte.
Die Aufgabe der Textklassifizierung besteht im Wesentlichen darin, die Eingabe für eine bestimmte Etiketten-ID vorherzusagen verwendet nicht die semantischen Informationen des Etiketts selbst. Die Feinabstimmungsaufgabe und die Vortrainingsaufgabe sind inkonsistent, und das aus der Vortrainingsaufgabe gelernte Sprachmodell kann nicht maximiert werden entstanden.
Das Paradigma des vorab trainierten Sprachmodells wird als promptes Lernen bezeichnet und kann als Hinweis auf das vorab trainierte Sprachmodell verstanden werden, um menschliche Probleme besser zu verstehen . Insbesondere wird dem Eingabetext ein zusätzlicher Absatz hinzugefügt. In diesem Absatz werden die mit der Beschriftung verbundenen Wörter maskiert, und dann wird das Modell verwendet, um die Wörter an der Position der Maske vorherzusagen, wodurch die Klassifizierungsaufgabe in eine Maske umgewandelt wird Sprachmodell: Nach der Vorhersage des Wortes an der Maskenposition ist es häufig erforderlich, das Wort dem Etikettensatz zuzuordnen, um eine typische Klassifizierungsaufgabe für kleine Stichproben zu erstellen dann wird die Maske fallen gelassen. Der Teil ist das Wort, das vorhergesagt werden muss.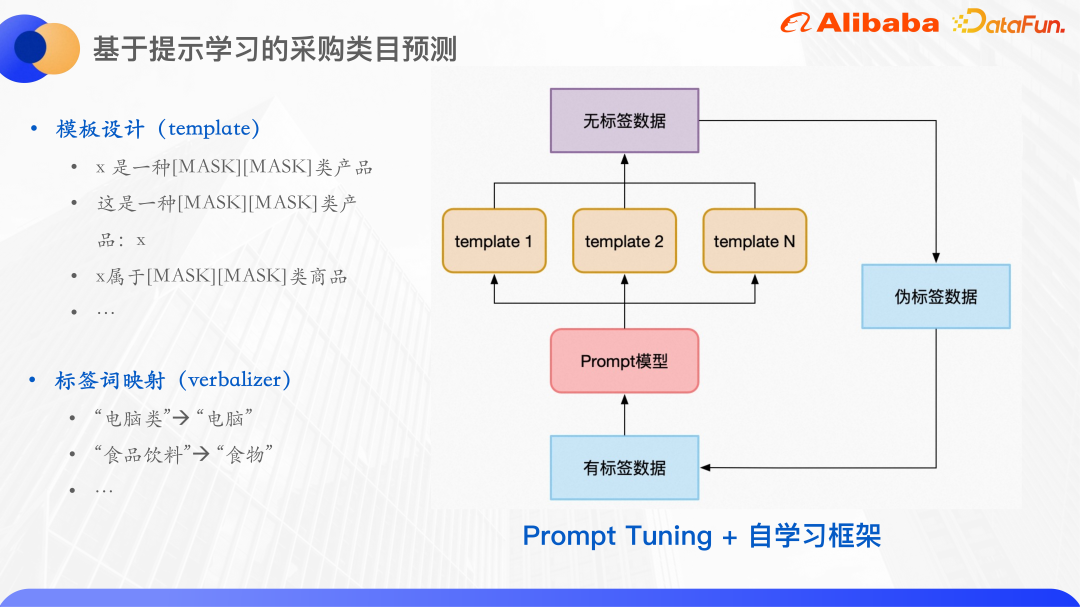
Für die Vorlage wird eine Zuordnung von vorhergesagten Wörtern zu Tag-Wörtern erstellt .
Erstens sind vorhergesagte Wörter nicht unbedingt Bezeichnungen. Denn um das Training zu erleichtern, ist die Anzahl der Maskenzeichen für jede Probe gleich. Die ursprünglichen Etikettenwörter bestehen aus 3 Zeichen, 4 Zeichen usw. Hier werden die Vorhersagewörter und Etikettenwörter zugeordnet und in zwei Zeichen vereinheitlicht.
Darüber hinaus verwenden Sie basierend auf schnellem Lernen mithilfe des selbstlernenden Frameworks zunächst beschriftete Daten, um ein Modell für jede Vorlage zu trainieren, und integrieren Sie dann mehrere Modelle, um unbeschriftete Daten vorherzusagen Für eine Runde wird trainiert, und Proben mit hoher Konfidenz werden als Pseudo-Label-Daten ausgewählt und dem Trainingssatz hinzugefügt. Auf diese Weise werden mehr Label-Daten erhalten und dann wird eine weitere Runde des Modelltrainings durchgeführt.
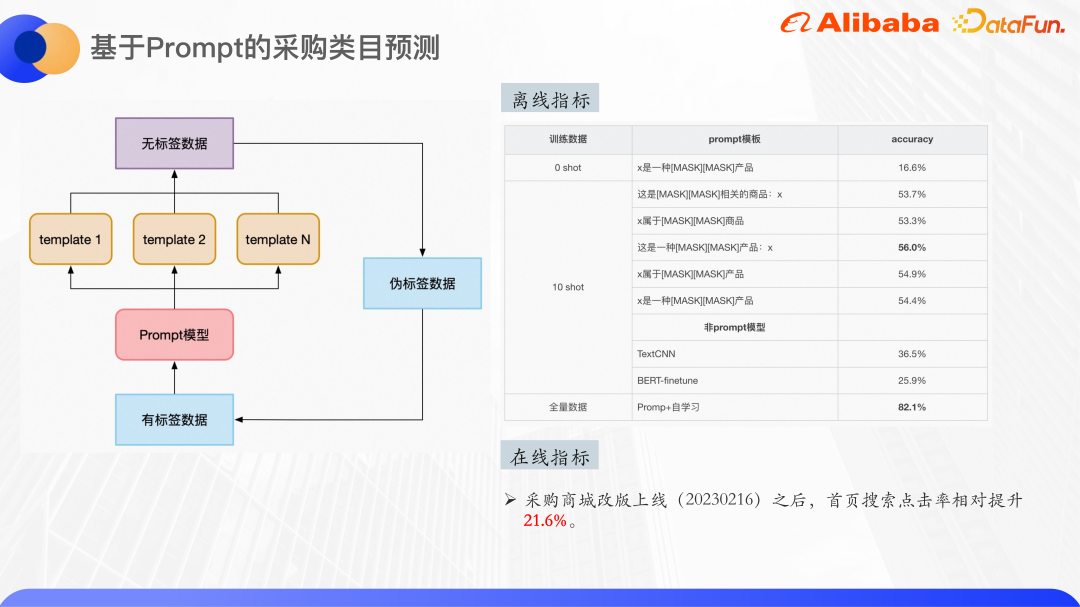
Das obige Bild ist etwas experimentell Ergebnisse: Sie können den Klassifizierungseffekt im Zero-Shot-Szenario sehen. Das vorab trainierte Modell verwendet Bert-Basis, mit insgesamt 30 Klassen kann Zero-Shot eine Genauigkeit von 16 % erreichen. Beim Training mit dem Zehn-Schuss-Datensatz können mehrere Vorlagen eine maximale Genauigkeit von 56 % erreichen, und die Verbesserung ist offensichtlich. Es ist ersichtlich, dass die Wahl der Vorlage auch einen gewissen Einfluss auf die Ergebnisse haben wird.
Derselbe Zehn-Schuss-Datensatz wurde auch mit TextCNN und BERT-Finetune getestet, und die Ergebnisse waren weitaus niedriger als beim Hinweislernen. Feinabstimmungseffekt, sodass das Lernen von Hinweisen in kleinen Beispielszenarien sehr effektiv ist.
Bei Verwendung der gesamten Datenmenge, etwa 4000 Trainingsbeispielen und Selbstlernen erreichte der Effekt schließlich etwa 82 %. Durch das Hinzufügen einiger Nachbearbeitungen, wie z. B. der Online-Kartenschwelle, kann sichergestellt werden, dass die Klassifizierungsgenauigkeit über 90 % liegt.
Es gibt zwei große Schwierigkeiten beim Verständnis der Unternehmensszenarioabfrage:

(1) Unzureichende Domänenkenntnisse,
Im Allgemeinen kurz Beim Textverständnis werden Wissensdiagramme verwendet, um das Wissen zu verbessern. Aufgrund der Besonderheiten von Unternehmensszenarien ist es jedoch schwierig, die Anforderungen von Open-Source-Wissensdiagrammen zu erfüllen. Daher werden halbstrukturierte Daten innerhalb des Unternehmens zur Wissenserweiterung verwendet.(2) In einigen Berufsfeldern im Unternehmen gibt es nur sehr wenige gekennzeichnete Daten, # 🎜🎜# Es gibt viele Szenen mit 0 Stichproben und kleinen Stichproben. In diesem Fall ist es natürlich, über die Verwendung eines vorab trainierten Modells nachzudenken, um Hinweislernen hinzuzufügen, aber die experimentellen Ergebnisse von 0 Stichproben sind nicht besonders gut , weil im vorhandenen vorab trainierten Modell Der verwendete Korpus deckt tatsächlich nicht das Domänenwissen unserer Unternehmensszenarien ab.
So ist es möglich, ein vorab trainiertes großes Modell auf Unternehmensebene zu trainieren und die internen vertikalen Felder des Unternehmens darauf zu nutzen Auf der Grundlage allgemeiner Korpusdaten werden Daten wie Alibabas ATA-Artikeldaten, Vertragsdaten und Codedaten trainiert, um ein großes vorab trainiertes Modell zu erhalten. Anschließend wird schnelles Lernen oder Kontextlernen verwendet, um verschiedene Aufgaben wie die Textklassifizierung zu vereinheitlichen. NER und Textzuordnung in eine Sprachmodellaufgabe.
Außerdem gilt es für sachliche Aufgaben wie Frage- und Antwort-QA und Suche, wie man die Richtigkeit der Antworten anhand der Ergebnisse des generativen Sprachmodells ist ebenfalls eine Frage, die berücksichtigt werden muss.
IV. Frage-und-Antwort-SitzungF1: Das gesamte Absichtserkennungsmodell von Alibaba Gibt es relevante Papiere oder Codes?
A2: Abfragen und ähnliche Abfragen verwenden die Eingabe auf Token-Dimensionsebene. Wissenskarten verwenden nur die ID-Einbettung, da es angesichts des Namens der Wissenskarte selbst einige interne Produktnamen gibt, die nicht in der Textsemantik enthalten sind. Besonders aussagekräftig. Wenn diese Wissenskarten im Text beschrieben werden, handelt es sich lediglich um einen relativ langen Text, der zu viel Rauschen verursachen kann. Daher wird die Textbeschreibung nicht verwendet, sondern nur die ID-Einbettung dieser Wissenskarte. ... Oder habt ihr Ideen dazu?
F4: Ist es sinnvoll, die Genauigkeit der Antwort des gerade erwähnten vorab trainierten großen Modells des Unternehmens zu erweitern? Können Sie den relevanten Inhalt erweitern?
Fügen Sie nach der Eingabe, also nach der Ausgabe des großen Modells, etwas Vorverarbeitung hinzu. Während der Vorverarbeitung können Sie Wissensdiagramme oder anderes Wissen hinzufügen, um die Genauigkeit der Antwort sicherzustellen.
Das obige ist der detaillierte Inhalt vonAbfrageabsichtserkennung basierend auf Wissenserweiterung und vorab trainiertem großem Modell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist digitale Währung?
Was ist digitale Währung?
 So öffnen Sie ESP-Dateien
So öffnen Sie ESP-Dateien
 So deaktivieren Sie den Echtzeitschutz im Windows-Sicherheitscenter
So deaktivieren Sie den Echtzeitschutz im Windows-Sicherheitscenter
 Was sind die neuen Funktionen von Hongmeng OS 3.0?
Was sind die neuen Funktionen von Hongmeng OS 3.0?
 So entsperren Sie das Oppo-Telefon, wenn ich das Passwort vergessen habe
So entsperren Sie das Oppo-Telefon, wenn ich das Passwort vergessen habe
 So lösen Sie das Problem, dass localhost nicht geöffnet werden kann
So lösen Sie das Problem, dass localhost nicht geöffnet werden kann
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Wie kaufe und verkaufe ich Bitcoin? Tutorial zum Bitcoin-Handel
Wie kaufe und verkaufe ich Bitcoin? Tutorial zum Bitcoin-Handel








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



