


Nach der Veröffentlichung von ChatGPT hat sich das Ökosystem im Bereich der Verarbeitung natürlicher Sprache völlig verändert. Viele Probleme, die zuvor nicht gelöst werden konnten, können mit ChatGPT gelöst werden.
Aber es bringt auch ein Problem mit sich: Die Leistung großer Modelle ist zu stark und es ist schwierig, die Unterschiede der einzelnen Modelle mit bloßem Auge zu beurteilen#🎜🎜 ##🎜🎜 #.
Wenn beispielsweise mehrere Versionen des Modells mit unterschiedlichen Basismodellen und Hyperparametern trainiert werden, kann die Leistung in den Beispielen ähnlich sein und es ist unmöglich, sie vollständig zu quantifizieren Der Unterschied zwischen den beiden Modellen.Derzeit
Bewertung großer SprachmodelleEs gibt zwei Hauptoptionen: #🎜🎜 #1. Rufen Sie die API-Schnittstellenbewertung von OpenAI auf.
. 2. Manuelle Anmerkung
Daten preisgeben. Um solche „großen Modellbewertungsprobleme“ zu lösen, haben Forscher der Peking University, der West Lake University, der North Carolina State University, der Carnegie Mellon University und MSRA gemeinsam gearbeitet hat mit PandaLM ein neues Framework zur Bewertung von Sprachmodellen entwickelt, das sich der Realisierung datenschutzschonender, zuverlässiger, reproduzierbarer und kostengünstiger Lösungen zur Bewertung großer Modelle widmet.

Bei gleichem Kontext kann PandaLM die Antwortausgabe verschiedener LLMs vergleichen und spezifische Gründe angeben.
Um die Zuverlässigkeit und Konsistenz des Tools zu demonstrieren, erstellten die Forscher einen vielfältigen, von Menschen kommentierten Testdatensatz, der aus etwa 1.000 Proben besteht, wobei PandaLM eine Genauigkeit von -7B von 94 % erreicht der Bewertungsfähigkeit von ChatGPT
.Drei Codezeilen verwenden PandaLM
Wenn zwei verschiedene große Modelle unterschiedliche Antworten auf dieselbe Anweisung und denselben Kontext erzeugen, zielt PandaLM darauf ab, die zu vergleichen Antwortqualität dieser beiden großen Modelle und Ausgabe der Vergleichsergebnisse, Vergleichsgründe und Antworten als Referenz.Es gibt drei Vergleichsergebnisse: Antwort 1 ist besser, Antwort 2 ist besser, Antwort 1 und Antwort 2 sind von ähnlicher Qualität.
Wenn Sie die Leistung mehrerer großer Modelle vergleichen, verwenden Sie einfach PandaLM, um sie paarweise zu vergleichen, und fassen Sie dann die Ergebnisse der paarweisen Vergleiche zusammen, um die Leistung mehrerer großer Modelle zu vergleichen Durch Rangfolge oder Zeichnen eines Beziehungsdiagramms der Teilordnung eines Modells können Sie die Leistungsunterschiede zwischen verschiedenen Modellen klar und intuitiv analysieren.
PandaLM muss nur „lokal bereitgestellt“ werden und „erfordert keine menschliche Beteiligung“, sodass die Bewertung von PandaLM die Privatsphäre schützen kann und recht kostengünstig ist.
Um eine bessere Interpretierbarkeit zu gewährleisten, kann PandaLM seine Auswahl auch in natürlicher Sprache erklären und einen zusätzlichen Satz von Referenzantworten generieren.
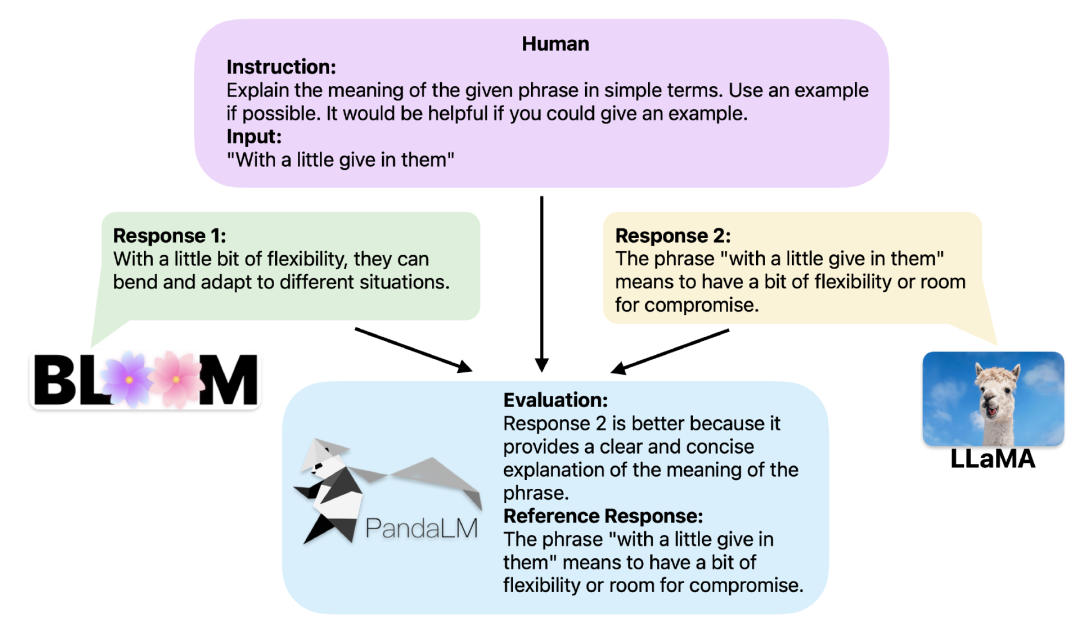 Im Projekt unterstützen die Forscher nicht nur die Nutzung von PandaLM über das Web Die Benutzeroberfläche unterstützt zur Fallanalyse und zur Vereinfachung der Verwendung auch drei Codezeilen zum Aufrufen von PandaLM zur Textauswertung, die von beliebigen Modellen und Daten generiert wird.
Im Projekt unterstützen die Forscher nicht nur die Nutzung von PandaLM über das Web Die Benutzeroberfläche unterstützt zur Fallanalyse und zur Vereinfachung der Verwendung auch drei Codezeilen zum Aufrufen von PandaLM zur Textauswertung, die von beliebigen Modellen und Daten generiert wird.
Angesichts der Tatsache, dass viele bestehende Modelle und Frameworks nicht Open Source sind oder es schwierig ist, die Inferenz lokal durchzuführen, unterstützt PandaLM die Verwendung bestimmter Modellgewichte zum Generieren von auszuwertendem Text oder die direkte Übergabe einer .json-Datei, die den auszuwertenden Text enthält.
Benutzer können PandaLM nutzen, um benutzerdefinierte Modelle und Eingabedaten auszuwerten, indem sie einfach eine Liste mit dem Modellnamen/HuggingFace-Modell-ID oder dem .json-Dateipfad übergeben. Das Folgende ist ein minimalistisches Anwendungsbeispiel:

Um jedem die flexible Nutzung von PandaLM zur kostenlosen Evaluierung zu ermöglichen, haben die Forscher auch die Modellgewichte von PandaLM auf der Huggingface-Website veröffentlicht, die über geladen werden kann Folgender Befehl PandaLM-7B-Modell:

Reproduzierbarkeit
Da die Gewichte von PandaLM öffentlich sind, auch wenn die Ausgabe des Sprachmodells Zufälligkeit aufweist, wenn behoben Nach dem zufälligen Seeding können die Bewertungsergebnisse von PandaLM immer noch konsistent bleiben.
Die Aktualisierung des Modells basierend auf der Online-API ist undurchsichtig, seine Ausgabe kann zu verschiedenen Zeiten sehr inkonsistent sein und die alte Version des Modells ist nicht mehr zugänglich, sodass die Bewertung basierend auf der Online-API häufig nicht möglich ist reproduzierbar.
Automatisierung, Datenschutz und geringer Overhead
Stellen Sie das PandaLM-Modell einfach lokal bereit und rufen Sie vorgefertigte Befehle auf, um mit der Evaluierung verschiedener großer Modelle zu beginnen. Es ist nicht erforderlich, mit Experten in Kontakt zu bleiben, wie dies bei der Einstellung von Experten der Fall ist Annotation Es gibt kein Problem von Datenlecks während der Kommunikation und es fallen keine API-Gebühren oder Arbeitskosten an, was es sehr kostengünstig macht.
Bewertungsebene
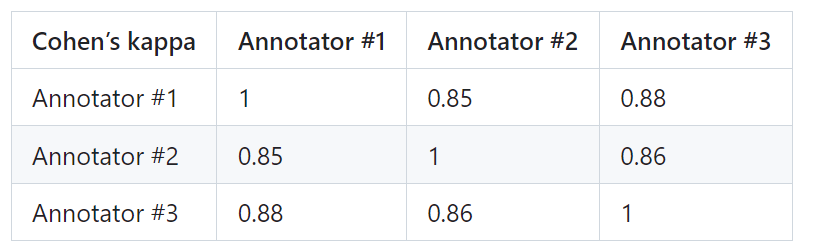
Um die Zuverlässigkeit von PandaLM zu beweisen, beauftragten die Forscher drei Experten mit der Durchführung unabhängiger wiederholter Annotationen und erstellten einen manuell annotierten Testsatz.
Das Testset enthält 50 verschiedene Szenen und jede Szene enthält mehrere Aufgaben. Dieser Testsatz ist vielfältig, zuverlässig und entspricht den menschlichen Vorlieben für Text. Jede Stichprobe des Testsatzes besteht aus einer Anweisung und einem Kontext sowie zwei Antworten, die von verschiedenen großen Modellen generiert werden, und die Qualität der beiden Antworten wird von Menschen verglichen.
Screenen Sie Proben mit großen Unterschieden zwischen Annotatoren aus, um sicherzustellen, dass die IAA (Inter Annotator Agreement) jedes Annotators im endgültigen Testsatz nahe bei 0,85 liegt. Es ist erwähnenswert, dass der Trainingssatz von PandaLM keine Überschneidungen mit dem manuell annotierten Testsatz aufweist, der erstellt wurde.
Diese gefilterten Proben erfordern zusätzliches Wissen oder schwer zu beschaffende Informationen zur Beurteilung, was es für Menschen schwierig macht, sie genau zu kennzeichnen.
Der gefilterte Testsatz enthält 1000 Proben, während der ursprüngliche ungefilterte Testsatz 2500 Proben enthält. Die Verteilung des Testsatzes beträgt {0:105, 1:422, 2:472}, wobei 0 angibt, dass die beiden Antworten von ähnlicher Qualität sind, 1 angibt, dass Antwort 1 besser ist, und 2 angibt, dass Antwort 2 besser ist. Unter Berücksichtigung des menschlichen Testsatzes als Benchmark sieht der Leistungsvergleich zwischen PandaLM und gpt-3.5-turbo wie folgt aus:
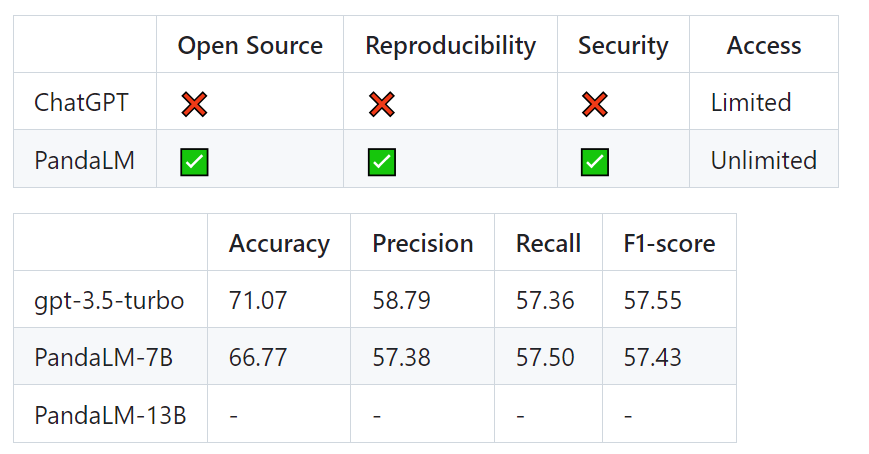
Es ist ersichtlich, dass PandaLM-7B das Niveau von gpt-3.5-turbo 94 erreicht hat % in Bezug auf Präzision, Rückruf und F1-Score ist PandaLM-7B fast das gleiche wie gpt-3.5-turbo.
Daher kann man im Vergleich zu gpt-3.5-turbo davon ausgehen, dass PandaLM-7B bereits über beträchtliche Fähigkeiten zur Evaluierung großer Modelle verfügt.
Zusätzlich zu Genauigkeit, Präzision, Rückruf und F1-Score des Testsatzes liefert es auch Vergleichsergebnisse zwischen 5 großen Open-Source-Modellen ähnlicher Größe.
Zuerst verwendeten wir dieselben Trainingsdaten zur Feinabstimmung der fünf Modelle und verwendeten dann Menschen, gpt-3.5-turbo und PandaLM, um die fünf Modelle jeweils zu vergleichen.
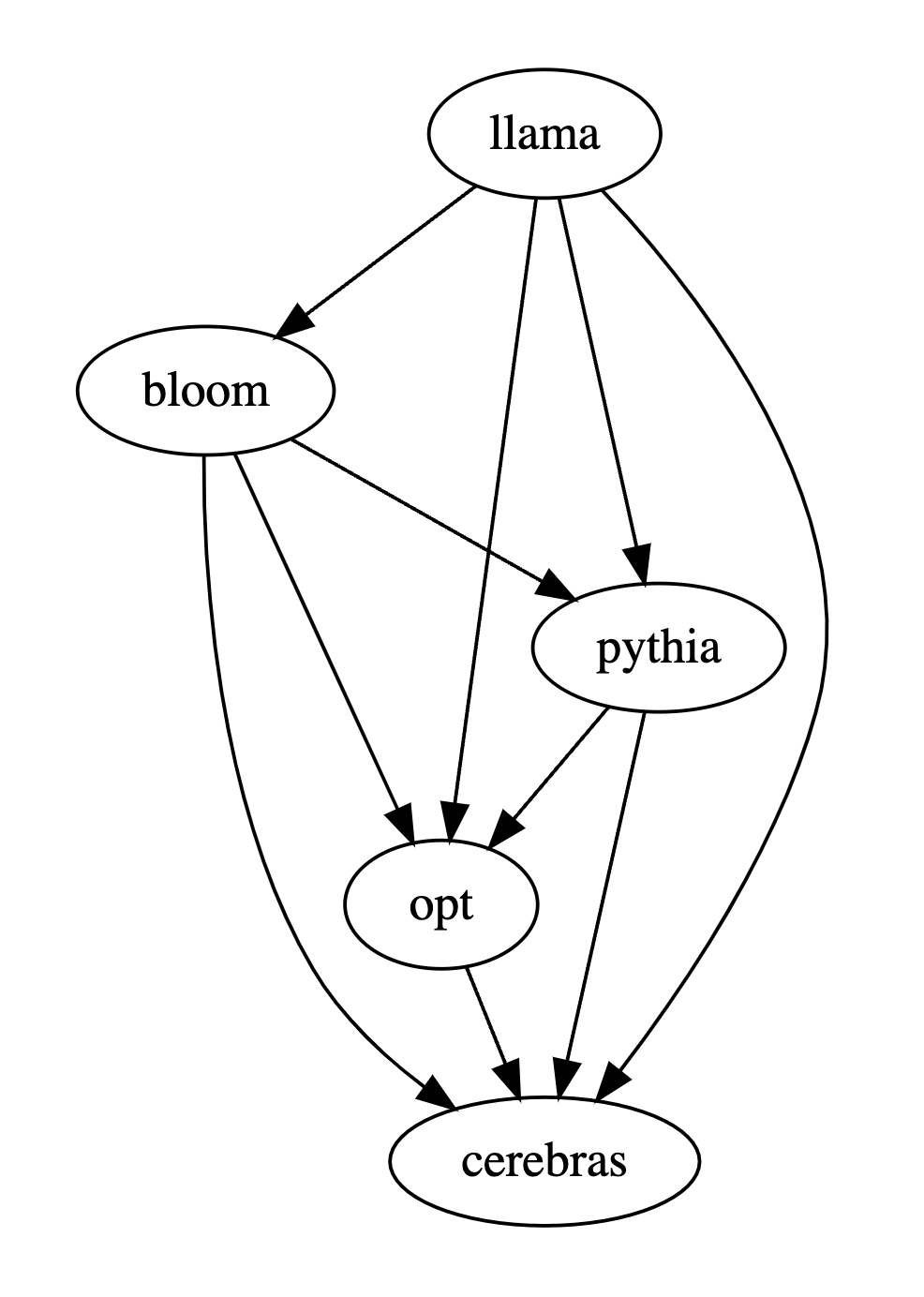
Das erste Tupel (72, 28, 11) in der ersten Zeile der Tabelle unten zeigt an, dass es 72 LLaMA-7B-Antworten gibt, die besser sind als Bloom-7B, und 28 LLaMA-7B-Antworten sind besser als Bloom- 7B Der Unterschied besteht darin, dass die beiden Modelle 11 ähnliche Antwortqualitäten haben.
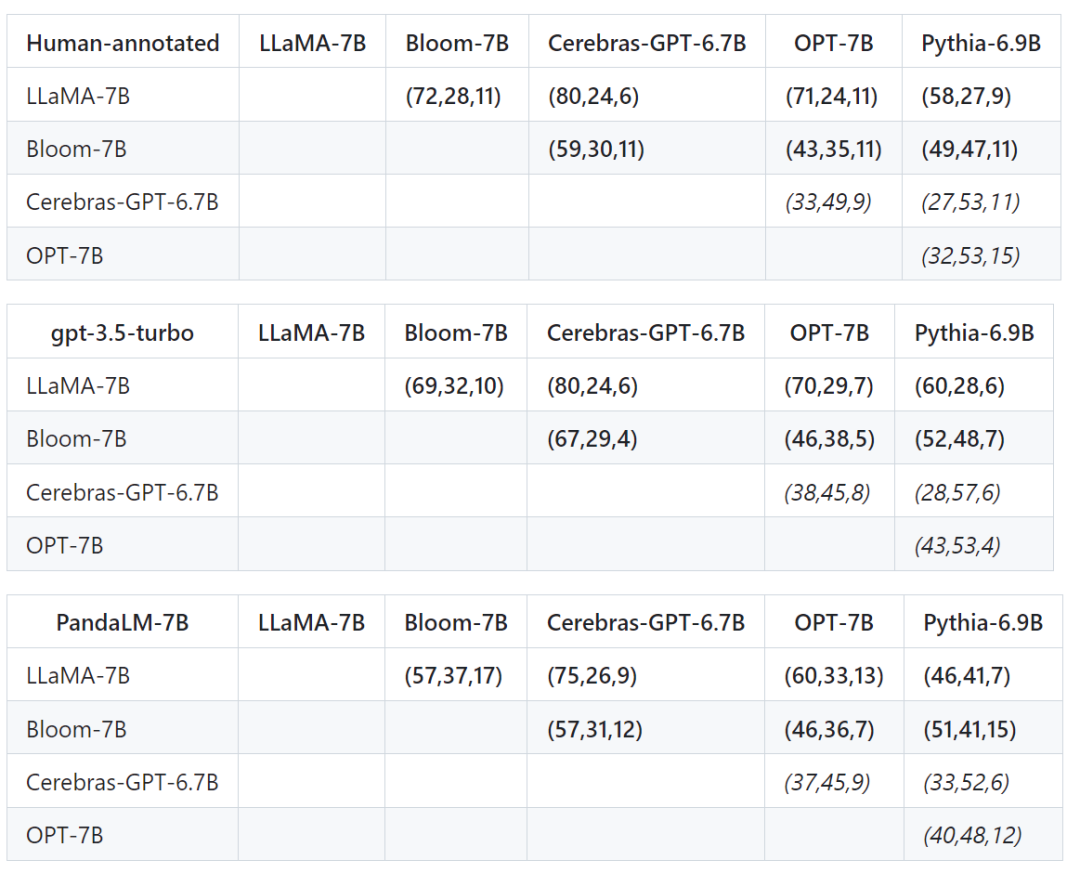
In diesem Beispiel denken Menschen also, dass LLaMA-7B besser ist als Bloom-7B. Die Ergebnisse in den folgenden drei Tabellen zeigen, dass Menschen, gpt-3.5-turbo und PandaLM-7B völlig übereinstimmende Urteile über die Beziehung zwischen den Vor- und Nachteilen der einzelnen Modelle haben.
PandaLM bietet neben der menschlichen Bewertung und der OpenAI-API-Bewertung eine dritte Lösung zur Bewertung großer Modelle. PandaLM verfügt nicht nur über ein hohes Bewertungsniveau, sondern auch die Bewertungsergebnisse sind reproduzierbar und die Bewertung Der Prozess ist automatisiert, datenschutzschonend und mit geringem Aufwand verbunden.
In Zukunft wird PandaLM die Forschung an großen Modellen in Wissenschaft und Industrie fördern, damit mehr Menschen von der Entwicklung großer Modelle profitieren können.
Das obige ist der detaillierte Inhalt vonPandaLM, ein Open-Source-„Schiedsrichter-Großmodell' der Peking-Universität, der West Lake University und anderen: drei Codezeilen zur vollautomatischen Bewertung von LLM mit einer Genauigkeit von 94 % von ChatGPT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So legen Sie fest, dass beide Enden in CSS ausgerichtet sind
So legen Sie fest, dass beide Enden in CSS ausgerichtet sind
 Telnet-Befehl
Telnet-Befehl
 So konfigurieren Sie Maven in der Idee
So konfigurieren Sie Maven in der Idee
 So lösen Sie dns_probe_possible
So lösen Sie dns_probe_possible
 Was sind die formellen Handelsplattformen für digitale Währungen?
Was sind die formellen Handelsplattformen für digitale Währungen?
 Was bedeutet es, wenn eine Nachricht gesendet, aber von der anderen Partei abgelehnt wurde?
Was bedeutet es, wenn eine Nachricht gesendet, aber von der anderen Partei abgelehnt wurde?
 So implementieren Sie die JSP-Paging-Funktion
So implementieren Sie die JSP-Paging-Funktion
 Abfragetool für Registrierungsdomänennamen
Abfragetool für Registrierungsdomänennamen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



