


wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
tar -zxvf jdk-8u151-linux-x64.tar.gz
mv jdk1.8.0_151/ /usr/java8
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile
java -version
Hinweis: Sie können Huawei-Quelle (mittlere Geschwindigkeit, akzeptabel, der Fokus liegt auf der Vollversion) und Tsinghua-Quelle zum Herunterladen auswählen Hadoop-Installationspaket (Die Download-Geschwindigkeit von Version 3.0.0 und höher ist zu langsam und es gibt nur wenige Versionen), Quelle der Beijing Foreign Studies University (die Download-Geschwindigkeit ist sehr hoch, aber es gibt nur wenige Versionen) – Ich habe es persönlich getestet #🎜 🎜#
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/ mv /opt/hadoop-3.1.3 /opt/hadoop
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
hadoop version
a Führen Sie den folgenden Befehl aus, um mit dem Aufrufen der Bearbeitungsseite zu beginnen. vim /opt/hadoop/etc/hadoop/core-site.xml
a. 执行以下命令开始进入编辑页面。 <property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
d. 按Esc键退出编辑模式,输入:wq保存退出。
a. 执行以下命令开始进入编辑页面。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
ssh-keygen -t rsa
d. 按Esc键退出编辑模式,输入:wq保存退出。
cd ~ cd .ssh cat id_rsa.pub >> authorized_keys
vi /etc/profile
若报错,执行下面操作后重新执行上面两句命令;若没有报错直接进入第五步:
输入如下命令,在环境变量中添加下面的配置
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
然后向里面加入如下的内容
source /etc/profile
输入如下命令使改动生效b Geben Sie i ein, um in den Bearbeitungsmodus zu gelangen. c. Fügen Sie den folgenden Inhalt in den Knoten <configuration></configuration> ein.
hadoop namenode -format
d Drücken Sie die Esc-Taste, um den Bearbeitungsmodus zu verlassen, geben Sie zum Speichern und Beenden Folgendes ein: wq. a Führen Sie den folgenden Befehl aus, um mit dem Aufrufen der Bearbeitungsseite zu beginnen. start-dfs.sh
b Geben Sie i ein, um in den Bearbeitungsmodus zu gelangen. c. Fügen Sie den folgenden Inhalt in den Knoten <configuration> ein. start-yarn.sh
d Drücken Sie die Esc-Taste, um den Bearbeitungsmodus zu verlassen, geben Sie zum Speichern und Beenden Folgendes ein: wq. Viertens: Konfigurieren Sie die passwortfreie SSH-Anmeldungjps
Wenn ein Fehler gemeldet wird, führen Sie die folgenden Vorgänge aus und führen Sie dann die beiden oben genannten Befehle erneut aus. Wenn kein Fehler gemeldet wird, fahren Sie direkt mit Schritt fünf fort: 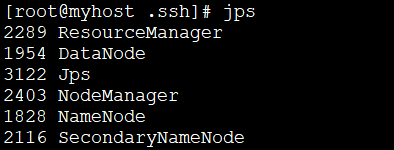 # 🎜🎜#
# 🎜🎜#Geben Sie den folgenden Befehl ein, fügen Sie die folgende Konfiguration zur Umgebungsvariablen hinzu
Fügen Sie dann den folgenden Inhalt hinzu
rrreee
Geben Sie den folgenden Befehl ein, damit die Änderungen wirksam werden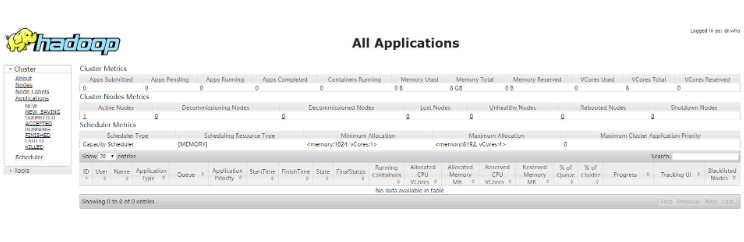 rrreee
rrreee
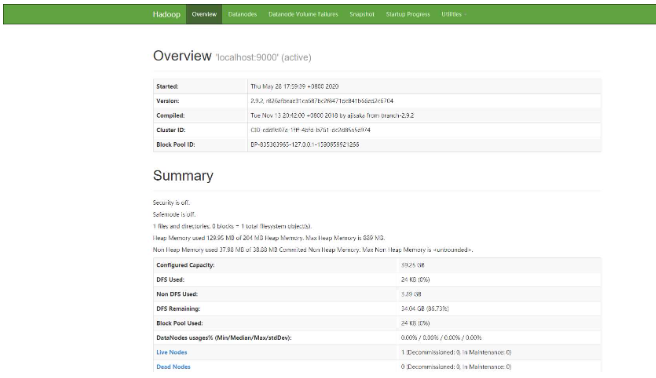
2.
Das obige ist der detaillierte Inhalt vonSo installieren Sie Hadoop unter Linux. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



