


Nachdem ChatGPT populär wurde, gibt es so viele Möglichkeiten, es zu verwenden.
Manche Leute nutzen es, um Lebensratschläge einzuholen, manche nutzen es einfach als Suchmaschine und manche nutzen es zum Verfassen von Aufsätzen.
Es macht keinen Spaß, eine Abschlussarbeit zu schreiben.
Einige Universitäten in den Vereinigten Staaten haben Studenten verboten, ChatGPT zum Schreiben von Hausaufgaben zu verwenden, und haben außerdem eine Reihe von Software entwickelt, um zu identifizieren und festzustellen, ob die von Studenten eingereichten Arbeiten von GPT erstellt wurden.
Hier liegt ein Problem vor.
Der Aufsatz von jemandem war ursprünglich schlecht geschrieben, aber die KI, die den Text beurteilte, dachte, er sei von einem Kollegen geschrieben worden.
Darüber hinaus liegt die Wahrscheinlichkeit, dass von Chinesen verfasste englische Arbeiten als von KI erstellt beurteilt werden, bei bis zu 61 %.

Das... was bedeutet das? Zittern!
Derzeit entwickeln sich generative Sprachmodelle rasant und haben tatsächlich große Fortschritte in der digitalen Kommunikation gebracht.
Aber es gibt wirklich viel Missbrauch.
Obwohl Forscher viele Erkennungsmethoden zur Unterscheidung von KI- und menschengenerierten Inhalten vorgeschlagen haben, müssen die Fairness und Stabilität dieser Erkennungsmethoden noch verbessert werden.
Zu diesem Zweck bewerteten die Forscher die Leistung mehrerer weit verbreiteter GPT-Detektoren anhand von Arbeiten, die von muttersprachlichen und nicht-muttersprachlichen englischsprachigen Autoren verfasst wurden.
Forschungsergebnisse zeigen, dass diese Detektoren von Nicht-Muttersprachlern geschriebene Proben immer fälschlicherweise als von der KI generiert erkennen, während von Muttersprachlern geschriebene Proben grundsätzlich genau identifiziert werden können.
Darüber hinaus haben Forscher gezeigt, dass diese Verzerrung mit einigen einfachen Strategien gemildert und GPT-Detektoren effektiv umgangen werden können.
Was bedeutet das? Dies zeigt, dass der GPT-Detektor auf Autoren herabschaut, deren Sprachkenntnisse nicht sehr gut sind, was sehr ärgerlich ist.
Ich kann nicht anders, als an dieses Spiel zu denken, um zu beurteilen, ob die KI eine echte Person ist, Sie aber vermuten, dass es sich um eine KI handelt, und das System sagt: „Die andere Partei könnte Sie als anstößig empfinden.“ .“
Die Forscher erhielten 91 TOEFL-Aufsätze von einem chinesischen Bildungsforum und 88 Aufsätze amerikanischer Achtklässler aus dem Datensatz der Hewlett Foundation, um 7 weit verbreitete GPT-Detektoren zu erkennen.
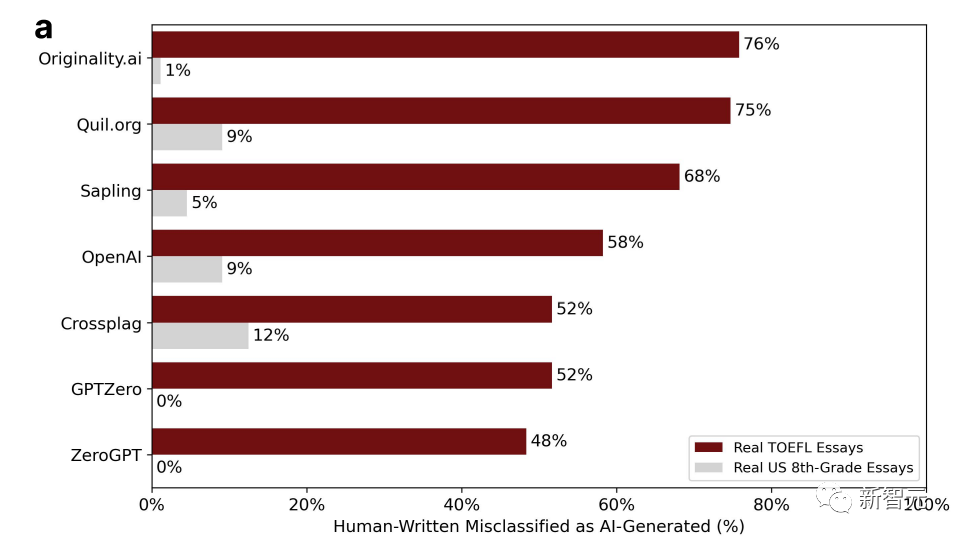
Der Prozentsatz in der Grafik stellt den Anteil der „Fehleinschätzungen“ dar. Das heißt, es wurde von einem Menschen geschrieben, aber die Erkennungssoftware geht davon aus, dass es von KI generiert wurde.
Sie sehen, dass die Daten sehr unterschiedlich sind.
Unter den sieben Detektoren beträgt die höchste Wahrscheinlichkeit einer Fehleinschätzung bei Aufsätzen amerikanischer Achtklässler nur 12 %, und es gibt zwei GPTs mit null Fehleinschätzungen.
Grundsätzlich werden mehr als die Hälfte der TOEFL-Aufsätze in chinesischen Foren falsch beurteilt, und die höchste Wahrscheinlichkeit einer Fehleinschätzung kann 76 % erreichen.
18 der 91 TOEFL-Aufsätze wurden von allen 7 GPT-Detektoren einhellig als von KI generiert eingestuft, während 89 der 91 Aufsätze von mindestens einem GPT-Detektor falsch beurteilt wurden.
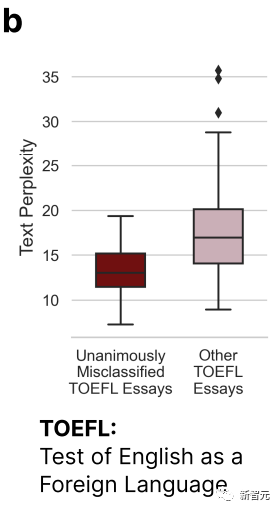
Auf dem Bild oben können wir erkennen, dass die TOEFL-Aufsätze, die von allen 7 GPTs falsch beurteilt wurden, deutlich weniger komplex sind als andere Aufsätze.
Dies bestätigt die Schlussfolgerung vom Anfang – der GPT-Detektor wird eine gewisse Voreingenommenheit gegenüber Autoren mit eingeschränkten sprachlichen Ausdrucksfähigkeiten haben.
Daher glauben Forscher, dass der GPT-Detektor mehr Artikel lesen sollte, die von Nicht-Muttersprachlern geschrieben wurden. Nur mit mehr Stichproben kann eine Verzerrung beseitigt werden.
Als nächstes warfen die Forscher von Nicht-Muttersprachlern verfasste TOEFL-Aufsätze in ChatGPT, um die Sprache zu bereichern und die Wortgebrauchsgewohnheiten von Muttersprachlern nachzuahmen.
Gleichzeitig wurden als Kontrollgruppe auch Aufsätze amerikanischer Achtklässler in ChatGPT geworfen und die Sprache vereinfacht, um die Schreibeigenschaften von Nicht-Muttersprachlern zu imitieren. Das Bild unten zeigt das neue Beurteilungsergebnis nach der Korrektur.
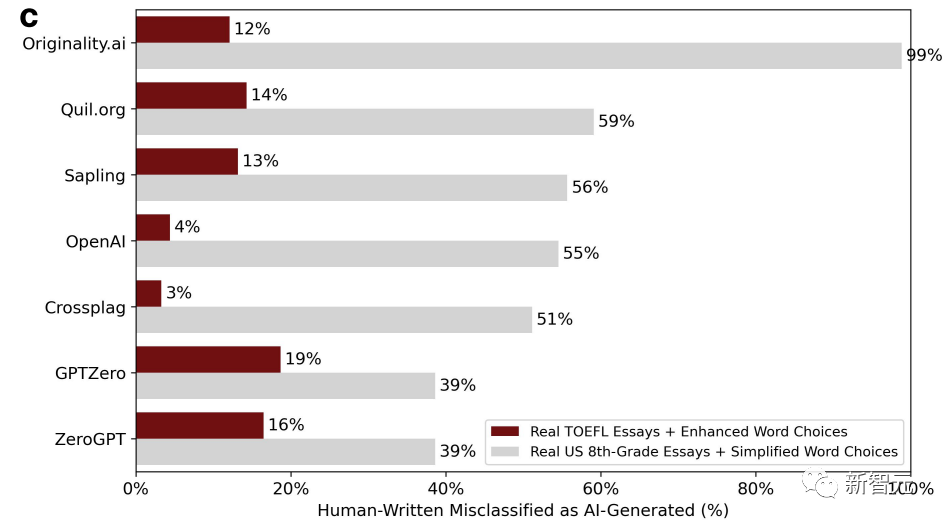
Wir können feststellen, dass sich die Situation drastisch verändert hat. Die Fehleinschätzungsrate von TOEFL-Aufsätzen, die die Sprache bereichern, ist auf nur 3 % und sogar auf 19 % gesunken. Im Gegensatz zur vorherigen Falsch-Positiv-Rate, die im Grunde mehr als die Hälfte betrug.
Im Gegenteil, die Fehlerquote bei Aufsätzen von Achtklässlern ist sprunghaft angestiegen. Es gibt sogar einen GPT-Detektor mit einer Fehlerquote von bis zu 99 %, was im Grunde alle Fehler ist.
Weil sich die Variable der Artikelkomplexität geändert hat.
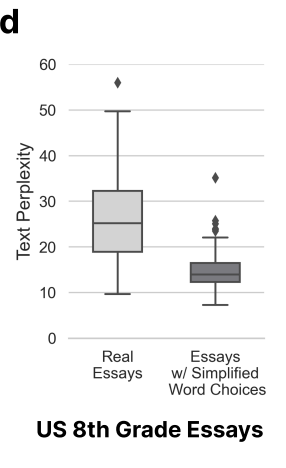
Hier kamen die Forscher zu dem Schluss, dass die von Nicht-Muttersprachlern geschriebenen Texte nicht authentisch sind, eine geringe Komplexität aufweisen und leicht falsch eingeschätzt werden.
Dies führt auch zu einem technischen Problem, aber auch zu einem Wertproblem. Die Verwendung von Komplexität zur Bestimmung, ob KI oder Menschen die Urheber sind, ist vernünftig, umfassend und streng.
Das Ergebnis ist offensichtlich nicht.
Gemessen an der Komplexität erleiden Nicht-Muttersprachler einen großen Verlust, weil sie Nicht-Muttersprachler sind (Unsinn).
Forscher glauben, dass die Verbesserung der Sprachvielfalt nicht nur die Voreingenommenheit gegenüber Nicht-Muttersprachlern mildern kann, sondern auch GPT-generierten Inhalten ermöglichen kann, GPT-Detektoren zu umgehen.
Um diesen Punkt zu beweisen, wählten die Forscher die Themen der Zulassungsaufsätze für amerikanische Universitätsbewerbungen von 2022 bis 2023 aus, gaben sie in ChatGPT-3.5 ein und generierten insgesamt 31 gefälschte Aufsätze.
Der GPT-Detektor war zunächst recht effektiv, in der zweiten Runde jedoch nicht mehr. Dies liegt daran, dass die Forscher diese Arbeiten in der zweiten Runde in ChatGPT einspielten und sie aufpolierten, wobei sie eine literarische Sprache verwendeten, um die Qualität des Textes zu verbessern.
Auf diese Weise sank die Genauigkeit des GPT-Detektors von 100 % auf 0 %. Wie unten dargestellt:
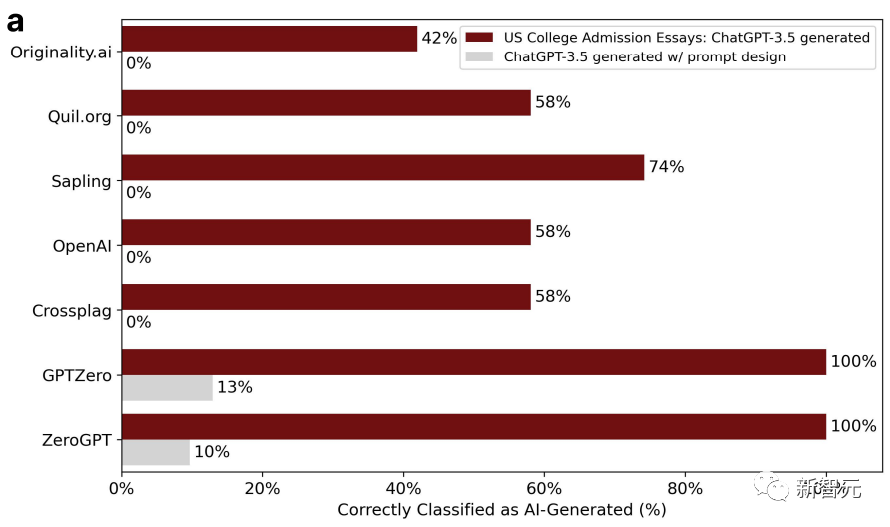
Die Komplexität des polierten Artikels hat sich entsprechend ebenfalls erhöht.
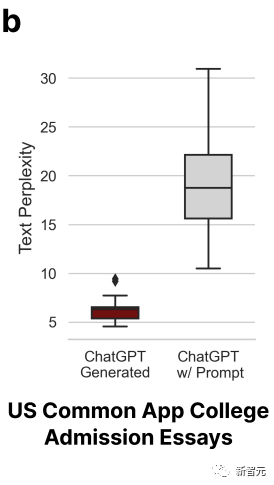
Gleichzeitig nutzten die Forscher 145 Abschlussberichtsthemen der Stanford University, um ChatGPT Abstracts erstellen zu lassen.
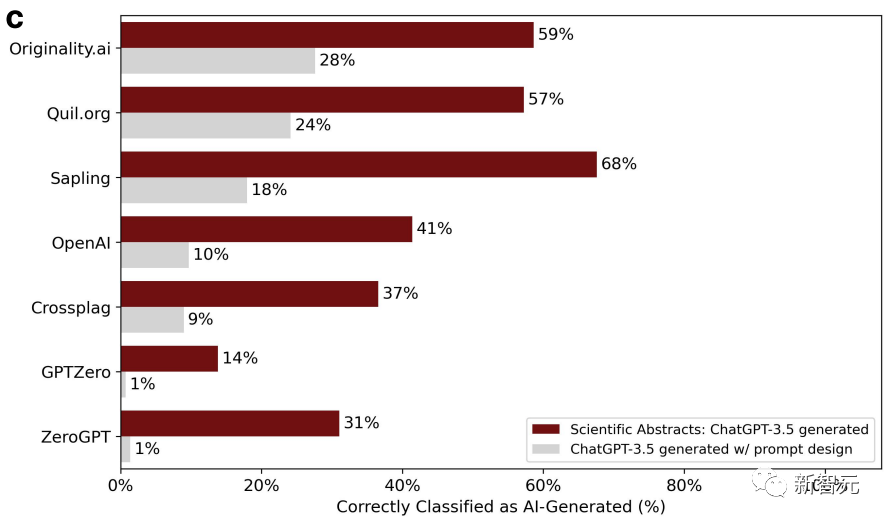
Zusammenfassung Nach dem Polieren nimmt die Genauigkeit der Beurteilung des Detektors weiter ab.
Die Forscher kamen erneut zu dem Schluss, dass ausgefeilte Artikel leicht falsch eingeschätzt werden und von der KI generiert werden. Zwei Runden sind besser als eine.
Kurz gesagt, alles in allem scheinen verschiedene GPT-Detektoren immer noch nicht in der Lage zu sein, den wesentlichsten Unterschied zwischen KI-Generierung und menschlichem Schreiben zu erfassen.
Das Schreiben der Menschen ist auch in drei, sechs oder neun Ebenen unterteilt. Es ist unvernünftig, nur nach Komplexität zu urteilen.
Abgesehen von Voreingenommenheiten muss auch die Technologie selbst verbessert werden.
Das obige ist der detaillierte Inhalt vonEmpörend! Neueste Forschungsergebnisse: 61 % der von Chinesen verfassten englischsprachigen Arbeiten werden vom ChatGPT-Detektor als KI-generiert eingestuft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



