


Der Quellcode des Linux-Kernels ist im Verzeichnis /usr/src/linux gespeichert. Die Zusammensetzung des Kernel-Quellcodes: 1. Arch-Verzeichnis, das den Kerncode enthält, der sich auf die vom Kernquellcode unterstützte Hardware-Architektur bezieht. 2. Include-Verzeichnis, das die meisten Kern-Include-Dateien enthält enthält den Kern-Startcode; 4. mm-Verzeichnis, enthält den gesamten Speicherverwaltungscode; 5. Drivers-Verzeichnis, enthält alle Gerätetreiber im System 6. IPC-Verzeichnis, enthält den Kern-Interprozess-Kommunikationscode;
Wo ist der Quellcode des Linux-Kernels?
Der Linux-Kernel-Quellcode kann aus vielen Quellen bezogen werden. Normalerweise enthält das Verzeichnis /usr/src/linux nach der Installation des Linux-Systems den Kernel-Quellcode.
Wenn Sie beim Lesen des Quellcodes reibungsloser vorgehen möchten, ist es am besten, im Voraus ein gewisses Verständnis für den Wissenshintergrund des Quellcodes zu haben.
Die Zusammensetzung des Linux-Kernel-Quellcodes ist wie folgt (angenommen relativ zum Linux-Verzeichnis):
arch
Dieses Unterverzeichnis enthält den Kerncode, der sich auf die von diesem Kernquellcode unterstützte Hardwarearchitektur bezieht. Für die X86-Plattform ist es beispielsweise i386.
include
Dieses Verzeichnis enthält die meisten Kern-Include-Dateien. Für jede unterstützte Architektur gibt es außerdem ein Unterverzeichnis.
init
Dieses Verzeichnis enthält den Kern-Startcode.
mm
Dieses Verzeichnis enthält den gesamten Speicherverwaltungscode. Der Speicherverwaltungscode, der sich auf die spezifische Hardwarearchitektur bezieht, befindet sich im Verzeichnis arch/*/mm. Derjenige, der X86 entspricht, ist beispielsweise arch/i386/mm/fault.c.
Treiber
Alle Gerätetreiber im System befinden sich in diesem Verzeichnis. Gerätetreiber sind weiter in Kategorien unterteilt, mit entsprechenden Unterverzeichnissen für jede Kategorie. Der Soundkartentreiber entspricht beispielsweise „drivers/sound“.
Ipc
Dieses Verzeichnis enthält den Kerncode für die prozessübergreifende Kommunikation.
modules
Dieses Verzeichnis enthält Module, die erstellt wurden und dynamisch geladen werden können.
fs Linux
unterstützte Dateisystemcodes. Verschiedene Dateisysteme haben unterschiedliche Unterverzeichnisse, die einander entsprechen. Beispielsweise entspricht das ext2-Dateisystem dem ext2-Unterverzeichnis.
Kernel
Hauptkerncode. Gleichzeitig wird der Code für die Prozessorstruktur im Verzeichnis arch/*/kernel abgelegt.
Net
Der Kernnetzwerk-Teilecode. Jedes darin enthaltene Unterverzeichnis entspricht einem Aspekt des Netzwerks.
Lib
Dieses Verzeichnis enthält den Kernbibliothekscode. Bibliothekscode, der sich auf die Prozessorarchitektur bezieht, wird im Verzeichnis arch/*/lib/ abgelegt.
Scripts
Dieses Verzeichnis enthält Skriptdateien, die zur Konfiguration des Kerns verwendet werden.
Dokumentation
Dieses Verzeichnis enthält einige Dokumente als Referenz.
Wenn Sie Linux analysieren und das Wesentliche des Betriebssystems verstehen möchten, ist das Lesen des Kernel-Quellcodes der effektivste Weg. Wir alle wissen, dass es viel Übung und Code-Schreiben erfordert, um ein guter Programmierer zu werden. Programmieren ist wichtig, aber wer nur programmiert, kann sich leicht auf seine eigenen Wissensgebiete beschränken. Wenn wir die Breite unseres Wissens erweitern wollen, müssen wir uns mehr Code aneignen, der von anderen geschrieben wurde, insbesondere Code, der von Leuten geschrieben wurde, die weiter fortgeschritten sind als wir. Durch diesen Ansatz können wir aus den Zwängen unseres eigenen Wissenskreises ausbrechen, in den Wissenskreis anderer eintreten und mehr über Informationen erfahren, die wir im Allgemeinen kurzfristig nicht lernen können. Der Linux-Kernel wird von unzähligen „Meistern“ in der Open-Source-Community sorgfältig gepflegt, und diese Leute können alle als Top-Code-Meister bezeichnet werden. Durch das Lesen des Linux-Kernel-Codes erlernen wir nicht nur Kernel-bezogenes Wissen, sondern meiner Meinung nach ist das Erlernen und Verstehen unserer Programmierkenntnisse und unseres Verständnisses von Computern noch wertvoller.
Durch ein Projekt bin ich auch mit der Analyse des Linux-Kernel-Quellcodes in Berührung gekommen. Von der Quellcode-Analyse habe ich sehr profitiert. Neben dem Erwerb relevanter Kernel-Kenntnisse hat es auch mein bisheriges Verständnis von Kernel-Code verändert:
1. Die Analyse des Kernel-Quellcodes ist nicht „außer Reichweite“. Die Schwierigkeit der Analyse des Kernel-Quellcodes liegt nicht im Quellcode selbst, sondern darin, wie geeignetere Methoden und Mittel zur Analyse des Codes verwendet werden können. Die Größe des Kernels bedeutet, dass wir ihn nicht Schritt für Schritt von der Hauptfunktion aus analysieren können, wie wir es bei der Analyse eines allgemeinen Demoprogramms tun. Wir brauchen eine Möglichkeit, von der Mitte aus einzugreifen, um den Kernel-Quellcode Stück für Stück zu „durchbrechen“. Dieser „Request-on-Demand“-Ansatz ermöglicht es uns, die Hauptzeile des Quellcodes zu erfassen, anstatt uns zu sehr auf bestimmte Details zu konzentrieren.
2. Das Design des Kerns ist wunderschön. Der jeweilige Status des Kernels bestimmt, dass die Ausführungseffizienz des Kernels hoch genug sein muss, um den Echtzeitanforderungen aktueller Computeranwendungen gerecht zu werden. Aus diesem Grund verwendet der Linux-Kernel eine Hybridprogrammierung aus C-Sprache und Assembler. Aber wir alle wissen, dass die Effizienz der Softwareausführung und die Wartbarkeit der Software in vielen Fällen im Widerspruch zueinander stehen. Wie die Wartbarkeit des Kernels verbessert und gleichzeitig die Effizienz des Kernels sichergestellt werden kann, hängt vom „schönen“ Design des Kernels ab.
3. Erstaunliche Programmierkenntnisse. Im allgemeinen Bereich des Anwendungssoftware-Designs darf der Status der Codierung nicht überbewertet werden, da Entwickler dem guten Design von Software mehr Aufmerksamkeit schenken und Codierung nur eine Frage der Implementierungsmethode ist – genau wie die Verwendung einer Axt zum Holzhacken, ohne zu viel Nachdenken. Dies gilt jedoch nicht für den Kernel. Ein gutes Codierungsdesign verbessert nicht nur die Wartbarkeit, sondern auch die Codeleistung.
Jeder wird ein anderes Verständnis des Kernels haben, je tiefer sich unser Verständnis des Kernels vertieft, desto mehr Gedanken und Erfahrungen werden wir über sein Design und seine Implementierung haben. Daher möchte dieser Artikel mehr Menschen, die vor der Tür des Linux-Kernels stehen, dazu anleiten, in die Welt von Linux einzutauchen und die Magie und Großartigkeit des Kernels selbst zu erleben. Und ich bin kein Experte für Kernel-Quellcode. Ich hoffe nur, dass ich meine eigenen Erfahrungen und Erfahrungen bei der Analyse von Quellcode weitergeben und denjenigen, die sie benötigen, Referenz und Hilfe bieten kann Für die Computerindustrie tragen Sie insbesondere im Hinblick auf den Betriebssystemkern Ihre eigenen bescheidenen Anstrengungen bei. Lassen Sie mich ohne weitere Umschweife (es ist schon zu langatmig, sorry~) meine eigene Methode zur Analyse des Linux-Kernel-Quellcodes vorstellen.
3 Kernel-Quellcode-Analysemethode
Das Gleiche gilt für die Analyse des Kernel-Codes. Zuerst müssen wir den Inhalt des zu analysierenden Codes lokalisieren. Handelt es sich um den Code für die Prozesssynchronisierung und -planung, den Code für die Speicherverwaltung, den Code für die Geräteverwaltung, den Code für den Systemstart usw. Aufgrund der enormen Größe des Kernels können wir nicht den gesamten Kernel-Code auf einmal analysieren, sodass wir uns eine angemessene Arbeitsteilung geben müssen. Wie uns das Algorithmusdesign sagt, müssen wir zur Lösung eines großen Problems zunächst die damit verbundenen Teilprobleme lösen.
Nachdem wir den zu analysierenden Codebereich gefunden haben, können wir alle verfügbaren Ressourcen nutzen, um die Gesamtstruktur und die allgemeinen Funktionen dieses Teils des Codes so umfassend wie möglich zu verstehen.
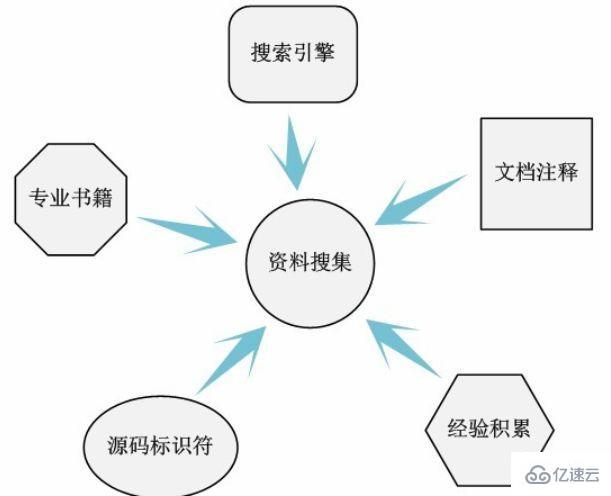
Alle hier genannten Ressourcen beziehen sich auf die großen Online-Suchmaschinen Baidu, Google, Lehrbücher und Fachbücher zu Betriebssystemprinzipien oder auf von anderen bereitgestellte Erfahrungen und Informationen oder sogar auf bereitgestellte Dokumentationen und Kommentare zum Linux-Quellcode und Namen von Quellcode-Bezeichnern (unterschätzen Sie nicht die Benennung von Bezeichnern im Code, manchmal können sie wichtige Informationen liefern). Kurz gesagt, alle Ressourcen beziehen sich hier auf alle verfügbaren Ressourcen, die Ihnen einfallen. Natürlich ist es für uns unmöglich, durch diese Form der Informationssammlung alle gewünschten Informationen zu erhalten, wir wollen lediglich so umfassend wie möglich sein. Denn je umfassender die Informationen gesammelt werden, desto mehr Informationen können bei der anschließenden Analyse des Codes verwendet werden und desto weniger schwierig wird der Analyseprozess.
Hier ist ein einfaches Beispiel. Angenommen, wir möchten den Code analysieren, der vom Frequenzkonvertierungsmechanismus von Linux implementiert wird. Bisher kennen wir diesen Begriff nur aus der wörtlichen Bedeutung, sodass wir grob vermuten können, dass er mit der Frequenzanpassung der CPU zusammenhängt. Durch die Informationssammlung sollten wir in der Lage sein, die folgenden relevanten Informationen zu erhalten:
1. CPUFreq-Mechanismus.
2. Leistung, Energiesparen, Userspace, OnDemand, konservative Frequenzregulierungsstrategien.
3. /driver/cpufreq/.
4. /documention/cpufreq.
5. P-Zustand und C-Zustand.
Wenn Sie diese Informationen bei der Analyse des Linux-Kernel-Codes sammeln können, sollten Sie großes „Glück“ haben. Schließlich sind die Informationen über den Linux-Kernel zwar nicht so umfangreich wie über .NET und JQuery, aber im Vergleich zu vor mehr als zehn Jahren, als es keine leistungsstarken Suchmaschinen und keine relevanten Forschungsmaterialien gab, sollte er als „großartig“ bezeichnet werden „Ernte“-Ära! Durch eine einfache „Suche“ (es kann ein bis zwei Tage dauern) haben wir sogar das Quellcode-Dateiverzeichnis gefunden, in dem sich dieser Teil des Codes befindet. Ich muss sagen, dass diese Art von Informationen einfach „unbezahlbar“ sind!
Bei der Datenerfassung hatten wir „Glück“, das Quellcodeverzeichnis zu finden, das sich auf den Quellcode bezieht. Dies bedeutet jedoch nicht, dass wir tatsächlich den Quellcode in diesem Verzeichnis analysieren. Manchmal sind die Verzeichnisse, die wir finden, möglicherweise verstreut, und manchmal enthalten die Verzeichnisse, die wir finden, viel Code, der sich auf bestimmte Maschinen bezieht, und wir kümmern uns mehr um den Hauptmechanismus des zu analysierenden Codes als um den speziellen Code, der sich auf die Maschine bezieht ( Dies wird uns helfen, die Natur des Kernels besser zu verstehen. Daher müssen wir die Informationen, die Codedateien in den Informationen enthalten, sorgfältig auswählen. Natürlich ist es unwahrscheinlich, dass dieser Schritt auf einmal abgeschlossen wird, und niemand kann garantieren, dass alle zu analysierenden Quellcodedateien gleichzeitig ausgewählt werden können und keine davon übersehen wird. Aber wir müssen uns keine Sorgen machen, solange wir die Kernquelldateien der meisten Module erfassen können, können wir sie später natürlich alle durch eine detaillierte Analyse des Codes finden.
Zurück zum obigen Beispiel: Wir haben die Dokumentation unter /documention/cpufreq sorgfältig gelesen. Der aktuelle Linux-Quellcode speichert die Dokumentation zum Modul im Dokumentationsordner des Quellcodeverzeichnisses. Wenn das zu analysierende Modul nicht über Dokumentation verfügt, erhöht dies die Schwierigkeit, die wichtigsten Quellcodedateien zu finden wird nicht dazu führen, dass wir den Quellcode, den wir analysieren möchten, nicht finden können. Durch das Lesen der Dokumentation können wir zumindest auf die Quelldatei /driver/cpufreq/cpufreq.c achten. Durch diese Dokumentation der Quelldateien, kombiniert mit den zuvor gesammelten Frequenzmodulationsstrategien, können wir leicht auf die fünf Quelldateien cpufreq_performance.c, cpufreq_powersave.c, cpufreq_userspace.c, cpufreq_ondemand und cpufreq_conservative.c achten. Wurden alle beteiligten Dokumente gefunden? Machen Sie sich keine Sorgen, beginnen Sie mit der Analyse und früher oder später werden Sie andere Quelldateien finden. Wenn Sie SourceInsight verwenden, um den Kernel-Quellcode unter Windows zu lesen, können wir andere Dateien freq_table.c, cpufreq_stats.c und /include/linux/cpufreq durch Funktionen wie Funktionsaufrufe und die Suche nach Symbolreferenzen in Kombination mit Codeanalyse leicht finden. H.
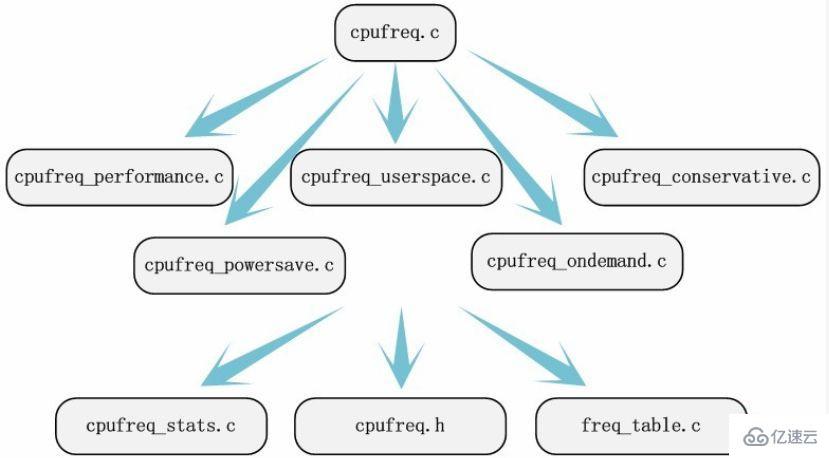
Entsprechend der gesuchten Informationsflussrichtung können wir die zu analysierenden Quellcodedateien vollständig lokalisieren. Der Schritt des Auffindens des Quellcodes ist nicht sehr kritisch, da wir nicht alle Quellcodedateien finden müssen und einen Teil der Arbeit auf den Prozess der Codeanalyse verlagern können. Die Positionierung des Quellcodes ist ebenfalls von entscheidender Bedeutung. Das Auffinden eines Teils der Quellcodedateien ist die Grundlage für die Analyse des Quellcodes.
Einfache Kommentare
Analysieren Sie in den gefundenen Quellcodedateien die allgemeine Bedeutung und Funktion jeder Variablen, Makros, Funktionen, Strukturen und anderen Codeelemente. Der Grund, warum dies als einfacher Kommentar bezeichnet wird, bedeutet nicht, dass die Kommentararbeit in diesem Teil sehr einfach ist, sondern dass der Kommentar in diesem Teil nicht zu detailliert sein muss, solange er die Bedeutung des Kommentars grob beschreibt relevante Codeelemente. Im Gegenteil: Die Arbeit hier ist tatsächlich der schwierigste Schritt im gesamten Analyseprozess. Da dies das erste Mal ist, dass man tief in den Kernel-Code einsteigt, werden die große Anzahl unbekannter GNU-C-Syntax und die überwältigenden Makrodefinitionen insbesondere für diejenigen, die den Kernel-Quellcode zum ersten Mal analysieren, sehr enttäuschend sein. Solange Sie sich zu diesem Zeitpunkt beruhigen und alle wichtigen Schwierigkeiten verstehen, können Sie sicherstellen, dass Sie in Zukunft nicht in die Falle geraten, wenn Sie auf ähnliche Schwierigkeiten stoßen. Darüber hinaus wird unser sonstiges Wissen rund um den Kernel wie ein Baum weiter wachsen.
Zum Beispiel wird die Verwendung des Makros „DEFINE_PER_CPU“ am Anfang der Datei cpufreq.c angezeigt. Wir können die Bedeutung und Funktion dieses Makros grundsätzlich verstehen, indem wir die Informationen konsultieren. Die hier verwendete Methode ist im Wesentlichen dieselbe wie die zuvor zum Sammeln von Daten verwendete Methode. Darüber hinaus können wir auch die von sourceinsight bereitgestellte Funktion „Gehe zu Definition“ verwenden, um die Definition anzuzeigen, oder LKML (Linux Kernel Mail List) verwenden, um sie anzuzeigen. Kurz gesagt, mit allen möglichen Mitteln können wir immer die Bedeutung dieses Makros verstehen – definieren Sie eine unabhängig verwendete Variable für jede CPU.
Wir bestehen nicht darauf, die Kommentare auf einmal genau zu beschreiben (wir müssen nicht einmal den spezifischen Implementierungsprozess jeder Funktion herausfinden, sondern nur die allgemeine funktionale Bedeutung herausfinden), sondern kombinieren die gesammelten Informationen und Folgendes Code Durch die Analyse wird die Bedeutung von Kommentaren kontinuierlich verbessert (hier sind die Originalkommentare und die Identifikatorbenennung im Quellcode von großem Nutzen). Durch ständige Anmerkungen, ständige Bezugnahme auf Informationen und ständige Änderung der Bedeutung von Anmerkungen.
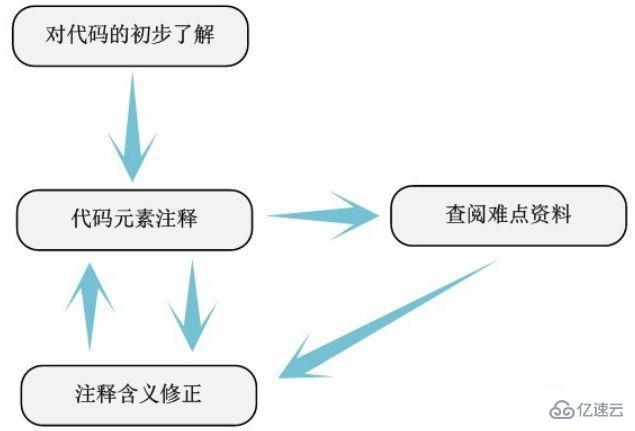
Nachdem wir einfach alle beteiligten Quellcodedateien mit Anmerkungen versehen haben, können wir folgende Ergebnisse erzielen:
1. Verstehen Sie grundsätzlich die Bedeutung der Codeelemente im Quellcode.
2. Grundsätzlich wurden alle wichtigen Quellcodedateien dieses Moduls gefunden.
In Kombination mit der Gesamt- oder Architekturbeschreibung des zu analysierenden Codes auf Basis der zuvor gesammelten Informationen und Daten können wir die Analyseergebnisse mit den Daten vergleichen, um unser Verständnis des Codes zu ermitteln und zu überarbeiten. Auf diese Weise können wir durch einen einfachen Kommentar die Hauptstruktur des Quellcodemoduls als Ganzes erfassen. Dadurch wird auch der grundlegende Zweck unserer einfachen Anmerkung erreicht.
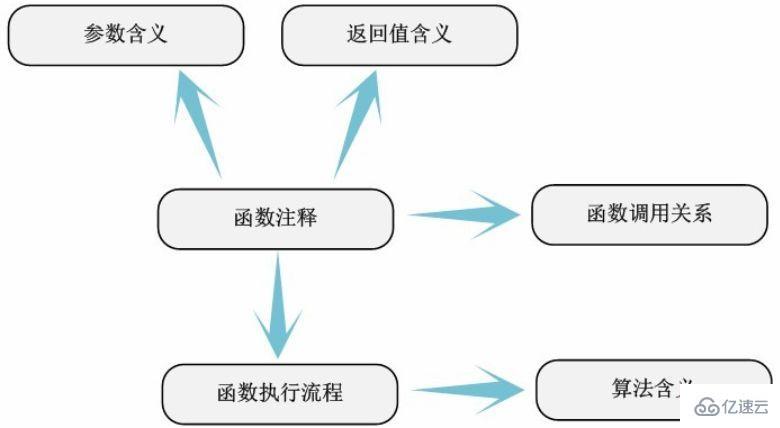
Nach Abschluss der einfachen Kommentare des Codes kann davon ausgegangen werden, dass die Analyse des Moduls zur Hälfte abgeschlossen ist und der verbleibende Inhalt eine eingehende Analyse und ein gründliches Verständnis des Codes ist. Einfache Kommentare können die spezifische Bedeutung von Codeelementen nicht immer sehr genau beschreiben, daher sind detaillierte Kommentare unbedingt erforderlich. In diesem Schritt müssen wir Folgendes klären:
1. Wenn die Variablendefinition verwendet wird.
2. Wenn der durch das Makro definierte Code verwendet wird.
3. Die Bedeutung von Funktionsparametern und Rückgabewerten.
4. Der Ausführungsablauf und die Aufrufbeziehung der Funktion.
5. Die spezifische Bedeutung und Nutzungsbedingungen der Strukturfelder.
Wir können diesen Schritt sogar als detaillierte Funktionsanmerkung bezeichnen, da die Bedeutung von Codeelementen außerhalb der Funktion in einfachen Kommentaren grundsätzlich klar ist. Der Ausführungsablauf und der Algorithmus der Funktion selbst sind die Hauptaufgaben dieses Teils der Annotation und Analyse.
Zum Beispiel, wie der Implementierungsalgorithmus der cpufreq_ondemand-Richtlinie (in der Funktion dbs_check_cpu) implementiert wird. Wir müssen die von der Funktion verwendeten Variablen und die aufgerufenen Funktionen schrittweise analysieren, um die Besonderheiten des Algorithmus zu verstehen. Für die besten Ergebnisse benötigen wir das Ausführungsflussdiagramm und das Funktionsaufruf-Beziehungsdiagramm dieser komplexen Funktionen, was die intuitivste Ausdrucksweise darstellt.
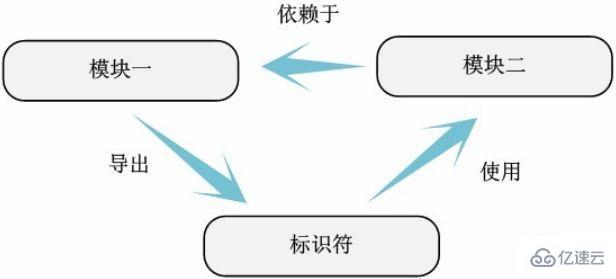
Durch die Kommentare in diesem Schritt können wir den gesamten Implementierungsmechanismus des zu analysierenden Codes grundsätzlich vollständig verstehen . Alle Analysearbeiten können als zu 80 % abgeschlossen betrachtet werden. Dieser Schritt ist besonders wichtig. Wir müssen versuchen, die Anmerkungsinformationen genau genug zu machen, um die Aufteilung der internen Module des zu analysierenden Codes besser zu verstehen. Obwohl der Linux-Kernel die Makrosyntax „module_init“ und „module_exit“ zum Deklarieren von Moduldateien verwendet, basiert die Aufteilung der Unterfunktionen innerhalb des Moduls auf einem vollständigen Verständnis der Funktionen des Moduls. Nur durch die korrekte Aufteilung des Moduls können wir herausfinden, welche externen Funktionen und Variablen das Modul bereitstellt (unter Verwendung der von EXPORT_SYMBOL_GPL oder EXPORT_SYMBOL exportierten Symbole). Erst dann können wir mit dem nächsten Schritt der Analyse der Identifikatorabhängigkeiten innerhalb des Moduls fortfahren.
Durch die Aufteilung der Codemodule im vierten Schritt können wir sie „einfach“ einzeln analysieren das Modul. Im Allgemeinen können wir mit den Moduleintritts- und -ausgangsfunktionen am Ende der Datei beginnen (die von „module_init“ und „module_exit“ deklarierten Funktionen befinden sich normalerweise am Ende der Datei), basierend auf den von ihnen aufgerufenen Funktionen (durch definierte Funktionen). Wir selbst oder andere Module) und die verwendeten Funktionen. Schlüsselvariablen (globale Variablen in dieser Datei oder externe Variablen anderer Module) zeichnen ein „Funktion-Variable-Funktion“-Abhängigkeitsdiagramm – wir nennen es ein Identifikator-Abhängigkeitsdiagramm.
Natürlich ist die Identifikator-Abhängigkeitsbeziehung innerhalb des Moduls keine einfache Baumstruktur, sondern in vielen Fällen eine komplexe Netzwerkbeziehung. Zu diesem Zeitpunkt spiegelt sich die Rolle unserer detaillierten Kommentare zum Code wider. Wir unterteilen das Modul basierend auf der Bedeutung der Funktion selbst in Unterfunktionen und extrahieren den Identifikator-Abhängigkeitsbaum jeder Unterfunktion.
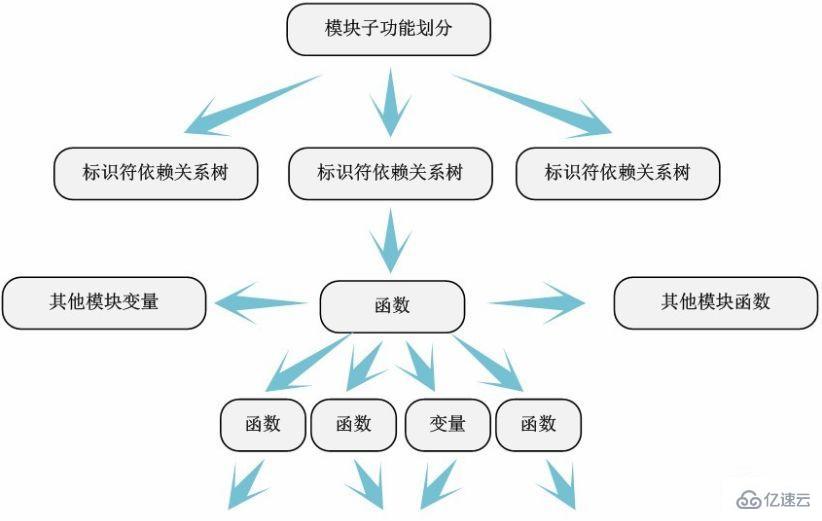
Durch die Analyse der Identifikatorabhängigkeit können die vom Modul definierten Funktionsaufrufe klar angezeigt werden Diese Funktionen , welche Variablen verwendet werden und welche Abhängigkeiten zwischen Modulunterfunktionen bestehen – welche Funktionen und Variablen gemeinsam genutzt werden usw. 3.6 Abhängigkeiten zwischen Modulen Wenn es geklärt ist, können die Abhängigkeiten zwischen Modulen leicht anhand der Variablen oder Funktionen anderer vom Modul verwendeter Module ermittelt werden.
cpufreq Die Modulabhängigkeitsbeziehung des Codes kann als folgende Beziehung ausgedrückt werden. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#3.7 Modularchitekturdiagramm#🎜🎜 ## 🎜🎜 ## 🎜 🎜#Durch das Abhängigkeitsdiagramm zwischen Modulen können der Status und die Funktion des Moduls im gesamten zu analysierenden Code klar ausgedrückt werden. Auf dieser Grundlage können wir die Module klassifizieren und die architektonische Beziehung des Codes klären.
Wie im Modulabhängigkeitsdiagramm von cpufreq gezeigt, können wir alle Frequenzmodulationen deutlich erkennen Strategiemodule hängen alle von den Kernmodulen cpufreq, cpufreq_stats und freq_table ab. Wenn wir die drei abhängigen Module in das Kernframework des Codes abstrahieren, basieren diese Frequenzmodulationsstrategiemodule auf diesem Framework und sind für die Interaktion mit der Benutzerschicht verantwortlich. Das Kernmodul cpufreq stellt Treiber und andere zugehörige Schnittstellen bereit, die für die Interaktion mit dem zugrunde liegenden System verantwortlich sind. Daher können wir das folgende Modularchitekturdiagramm erhalten.
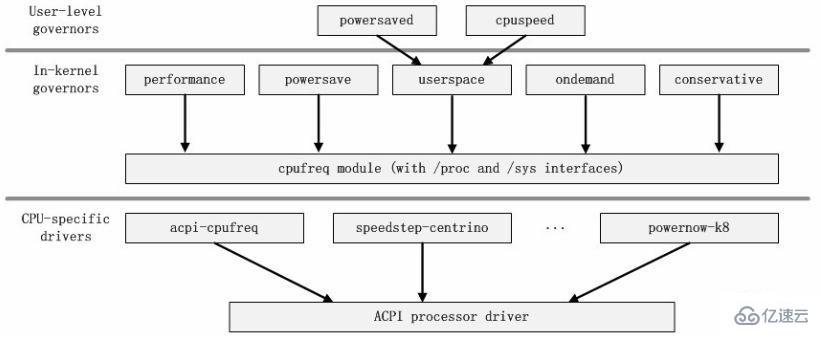
Natürlich ist das Architekturdiagramm kein anorganisches Zusammenfügen von Modulen. Wir müssen auch die Informationen kombinieren, die wir konsultieren, um die Bedeutung des Architekturdiagramms zu bereichern. Daher variieren die Details des Architekturdiagramms hier je nach Verständnis verschiedener Personen. Die Bedeutung des Hauptteils des Architekturdiagramms ist jedoch grundsätzlich dieselbe. Zu diesem Zeitpunkt haben wir die gesamte Analyse des zu analysierenden Kernelcodes abgeschlossen.
Das obige ist der detaillierte Inhalt vonIn welcher Datei befindet sich der Quellcode des Linux-Kernels?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



