



Das Schreiben von Code mit ChatGPT ist für viele Programmierer zu einer Routineaufgabe geworden.
Aber haben Sie jemals gedacht, dass ein Großteil des von ChatGPT generierten Codes einfach „genau aussieht“?
Eine aktuelle Studie der University of Illinois at Urbana-Champaign und der Nanjing University zeigt, dass:
Die Genauigkeit des von ChatGPT und GPT-4 generierten Codes mindestens 13 % niedriger ist als zuvor bewertet!

Einige Internetnutzer beklagten, dass zu viele ML-Papiere einige problematische oder begrenzte Benchmarks zur Bewertung von Modellen verwenden, um kurzzeitig „SOTA“ zu erreichen. Dadurch wird die ursprüngliche Form sichtbar, wenn die Bewertungsmethode geändert wird.

Einige Internetnutzer sagten, dies zeige auch, dass der von großen Modellen generierte Code immer noch einer manuellen Überwachung bedarf und „die beste Zeit für das Schreiben von KI-Code noch nicht gekommen ist“.

Was für eine neue Bewertungsmethode schlägt das Papier vor?
Diese neue Methode heißt EvalPlus und ist ein automatisiertes Code-Bewertungs-Framework.
Konkret werden diese Bewertungsmaßstäbe strenger, indem die Eingabevielfalt und die Genauigkeit der Problembeschreibung bestehender Bewertungsdatensätze verbessert werden.
Einerseits die Input-Vielfalt. EvalPlus wird zunächst ChatGPT verwenden, um einige Seed-Eingabebeispiele basierend auf den Standardantworten zu generieren (obwohl die Programmierfähigkeit von ChatGPT getestet werden muss, scheint es nicht inkonsistent zu sein, es zum Generieren von Seed-Eingaben zu verwenden).
Verwenden Sie dann EvalPlus, um diese zu verbessern Eingaben säen und ändern Es ist schwieriger, komplizierter und kniffliger.
Der andere Aspekt ist die Genauigkeit der Problembeschreibung. EvalPlus wird die Beschreibung der Codeanforderungen präziser gestalten und gleichzeitig die Eingabebedingungen einschränken, gleichzeitig aber auch die Problembeschreibungen in natürlicher Sprache ergänzen, um die Genauigkeitsanforderungen für die Modellausgabe zu verbessern.
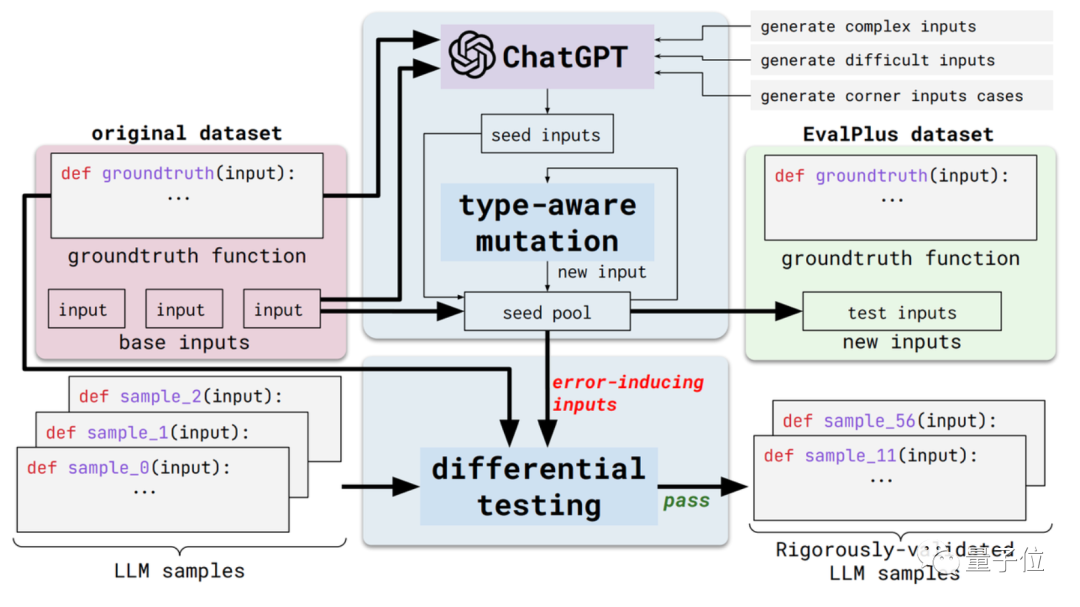
Hier wählt das Papier den HUMANEVAL-Datensatz als Demonstration.
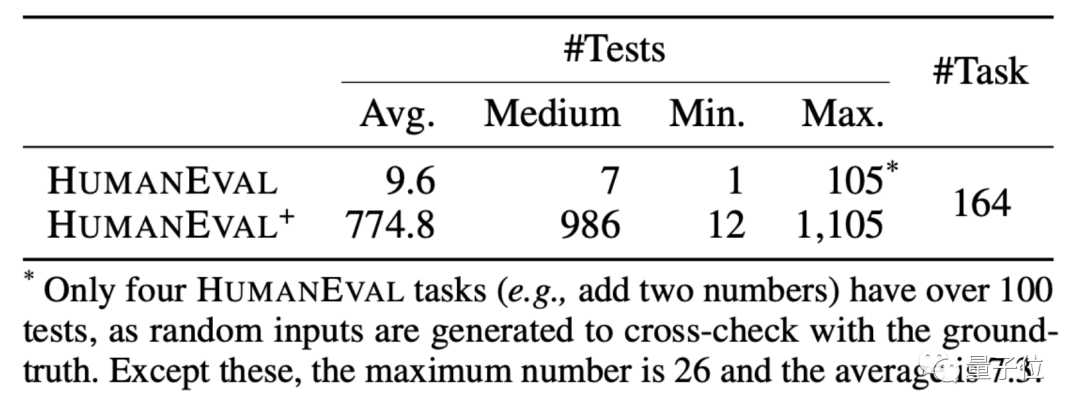
HUMANEVAL ist ein gemeinsam von OpenAI und Anthropic AI erstellter Codedatensatz. Er enthält 164 ursprüngliche Programmierfragen, die verschiedene Arten von Fragen umfassen, darunter Sprachverständnis, Algorithmen, Mathematik und Softwareinterviews.
EvalPlus wird Programmierprobleme klarer erscheinen lassen, indem es die Eingabetypen und Funktionsbeschreibungen solcher Datensätze verbessert, und die zum Testen verwendeten Eingaben werden „kniffliger“ oder schwieriger.
Nehmen Sie als Beispiel eine der Union-Set-Programmierfragen. Die KI muss einen Code schreiben, um die gemeinsamen Elemente in den beiden Datenlisten zu finden und diese Elemente zu sortieren.
EvalPlus testet damit die Genauigkeit des von ChatGPT geschriebenen Codes.
Nach der Durchführung eines einfachen Eingabetests haben wir festgestellt, dass ChatGPT genaue Antworten ausgeben kann. Aber wenn man die Eingabe ändert, findet man den Fehler in der ChatGPT-Version des Codes:

Es stimmt, dass die Testfragen für die KI schwieriger sind.

Basierend auf dieser Methode hat EvalPlus auch eine verbesserte Version des HUMANEVAL+-Datensatzes erstellt. Beim Hinzufügen von Eingaben wurden einige Programmierfragen mit problematischen Antworten in HUMANEVAL korrigiert.
Um wie viel wird sich also unter diesem „neuen Satz von Testfragen“ die Genauigkeit der großen Sprachmodelle tatsächlich verringern?
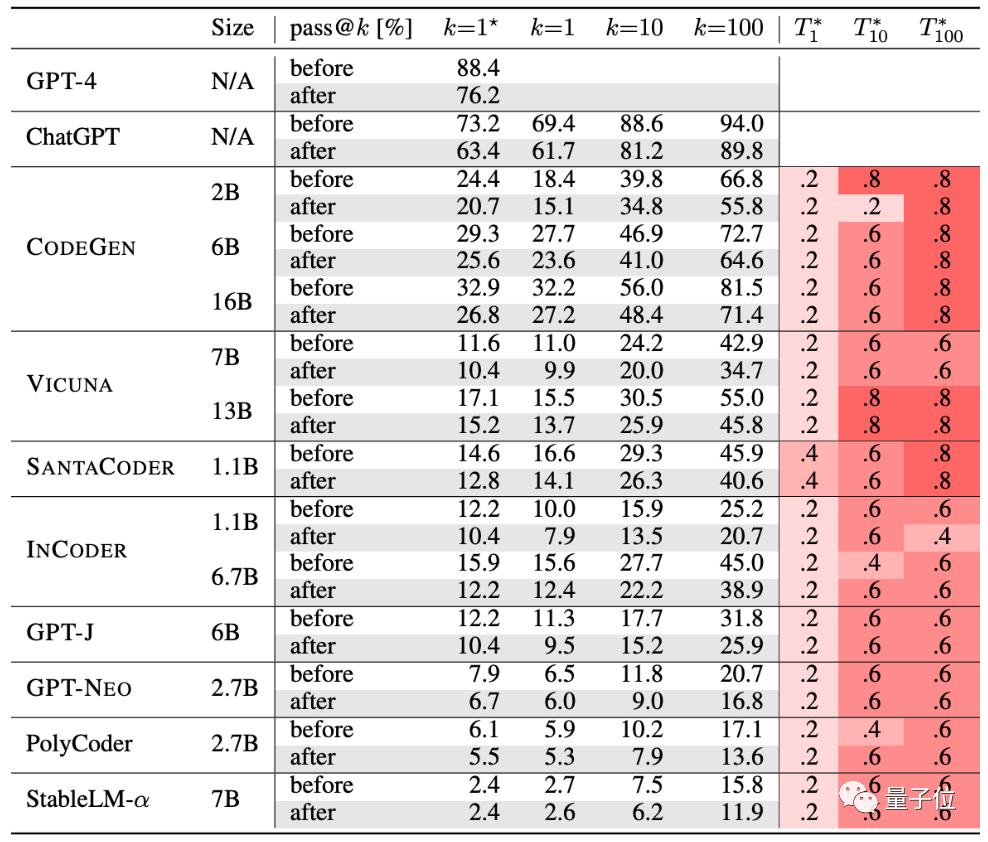
Die Autoren haben 10 derzeit beliebte KIs zur Codegenerierung getestet.
GPT-4, ChatGPT, CODEGEN, VICUNA, SANTACODER, INCODER, GPT-J, GPT-NEO, PolyCoder, StableLM-α.
Der Tabelle zufolge ist die Generierungsgenauigkeit dieser Gruppe von KIs nach strengen Tests zurückgegangen:
Die Genauigkeit wird hier durch eine Methode namens pass@k bewertet, wobei k die Anzahl von ist Programme, die es großen Modellen ermöglichen, Probleme zu generieren, n ist die Anzahl der zum Testen verwendeten Eingaben und c ist die Anzahl der korrekten Eingaben:
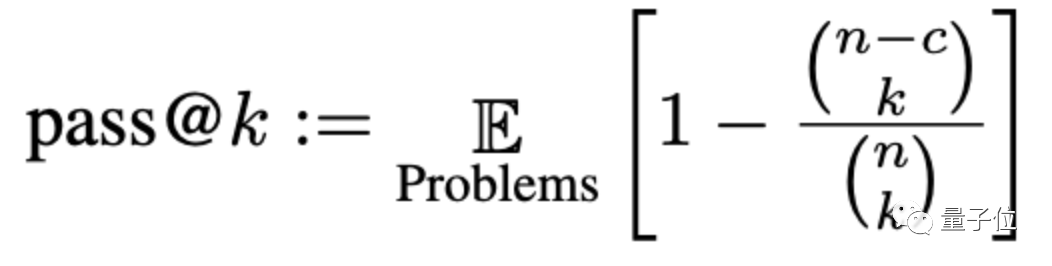
Gemäß diesem neuen Satz von Bewertungskriterien ist die durchschnittliche Genauigkeit großer Modelle Sie sank um 15 %, und das umfassender untersuchte CODEGEN-16B sank um mehr als 18 %.
Die Leistung des von ChatGPT und GPT-4 generierten Codes ist ebenfalls um mindestens 13 % gesunken.
Einige Internetnutzer sagten jedoch, es sei eine „bekannte Tatsache“, dass der von großen Modellen generierte Code nicht so gut sei, und es müsse untersucht werden, „warum der von großen Modellen geschriebene Code nicht verwendet werden kann“.
Das obige ist der detaillierte Inhalt vonDie Genauigkeit der ChatGPT-Programmierung ist um 13 % gesunken! Der neue Benchmark von UIUC und NTU lässt KI-Code in seiner wahren Form erscheinen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 ChatGPT-Registrierung
ChatGPT-Registrierung
 Inländische kostenlose ChatGPT-Enzyklopädie
Inländische kostenlose ChatGPT-Enzyklopädie
 So installieren Sie ChatGPT auf einem Mobiltelefon
So installieren Sie ChatGPT auf einem Mobiltelefon
 Kann Chatgpt in China verwendet werden?
Kann Chatgpt in China verwendet werden?
 So heben Sie Bargeld bei Yiouokex ab
So heben Sie Bargeld bei Yiouokex ab
 Lösung zur Verlangsamung der Zugriffsgeschwindigkeit bei der Anmietung eines US-Servers
Lösung zur Verlangsamung der Zugriffsgeschwindigkeit bei der Anmietung eines US-Servers
 Virtuelle Währungsumtauschplattform
Virtuelle Währungsumtauschplattform
 Einführung in den Eröffnungsort von Win8
Einführung in den Eröffnungsort von Win8








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



