



Los geht's!
Wir nutzen den Parameteranpassungsprozess beim maschinellen Lernen zum Üben. Es stehen drei Möglichkeiten zur Auswahl. Die erste Option ist die Verwendung von argparse, einem beliebten Python-Modul zum Parsen von Befehlszeilen. Die andere Möglichkeit besteht darin, eine JSON-Datei zu lesen, in die wir alle Hyperparameter einfügen können. Die dritte Möglichkeit besteht darin, YAML-Dateien zu verwenden. Neugierig, fangen wir an!
Im folgenden Code verwende ich Visual Studio Code, eine sehr effiziente integrierte Python-Entwicklungsumgebung. Das Schöne an diesem Tool ist, dass es jede Programmiersprache durch die Installation von Erweiterungen unterstützt, das Terminal integriert und die gleichzeitige Arbeit mit einer großen Anzahl von Python-Skripten und Jupyter-Notebooks ermöglicht.
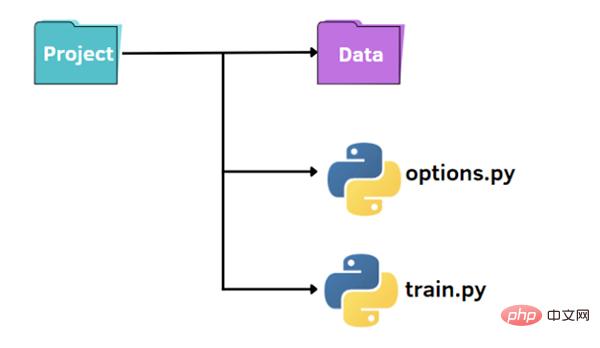
Wie im Bild oben gezeigt, haben wir eine Standardstruktur, um unser kleines Projekt zu organisieren:
Zuerst können wir eine Datei train.py in erstellen. Wir haben das grundlegende Verfahren zum Importieren der Daten, Trainieren Sie das Modell anhand der Trainingsdaten und werten Sie es anhand des Testsatzes aus:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('datahour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)Im Code importieren wir auch die Funktion train_options, die in der Datei options.py enthalten ist. Bei der letztgenannten Datei handelt es sich um eine Python-Datei, aus der wir die in train.py berücksichtigten Hyperparameter ändern können:
import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return optIn diesem Beispiel verwenden wir die argparse-Bibliothek, die beim Parsen von Befehlszeilenargumenten sehr beliebt ist. Zuerst initialisieren wir den Parser und können dann die Parameter hinzufügen, auf die wir zugreifen möchten.
Hier ist ein Beispiel für die Ausführung des Codes:
python train.py

Um die Standardwerte von Hyperparametern zu ändern, gibt es zwei Möglichkeiten. Die erste Möglichkeit besteht darin, in der Datei „options.py“ unterschiedliche Standardwerte festzulegen. Eine andere Möglichkeit besteht darin, den Hyperparameterwert über die Befehlszeile zu übergeben:
python train.py --n_estimators 200
Wir müssen den Namen des Hyperparameters, den wir ändern möchten, und den entsprechenden Wert angeben.
python train.py --n_estimators 200 --max_depth 7
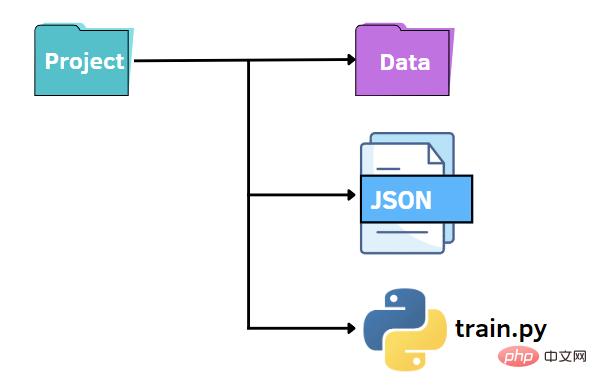
Wie zuvor können wir eine ähnliche Dateistruktur beibehalten. In diesem Fall ersetzen wir die Datei „options.py“ durch eine JSON-Datei. Mit anderen Worten: Wir wollen die Werte der Hyperparameter in einer JSON-Datei angeben und sie an die train.py-Datei übergeben. JSON-Dateien können eine schnelle und intuitive Alternative zur argparse-Bibliothek sein und Schlüssel-Wert-Paare zum Speichern von Daten nutzen. Als Nächstes erstellen wir eine Datei „options.json“, die die Daten enthält, die wir später an anderen Code übergeben müssen.
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}Wie Sie oben sehen können, ist es einem Python-Wörterbuch sehr ähnlich. Aber im Gegensatz zu einem Wörterbuch enthält es Daten im Text-/String-Format. Darüber hinaus gibt es einige gängige Datentypen mit leicht unterschiedlicher Syntax. Boolesche Werte sind beispielsweise falsch/wahr, während Python Falsch/Wahr erkennt. Weitere mögliche Werte in JSON sind Arrays, die mittels eckiger Klammern als Python-Listen dargestellt werden.
Das Schöne an der Arbeit mit JSON-Daten in Python ist, dass sie über die Lademethode in ein Python-Wörterbuch konvertiert werden können:
f = open("options.json", "rb")
parameters = json.load(f)Um auf ein bestimmtes Element zuzugreifen, müssen wir nur seinen Schlüsselnamen in eckigen Klammern angeben:
if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
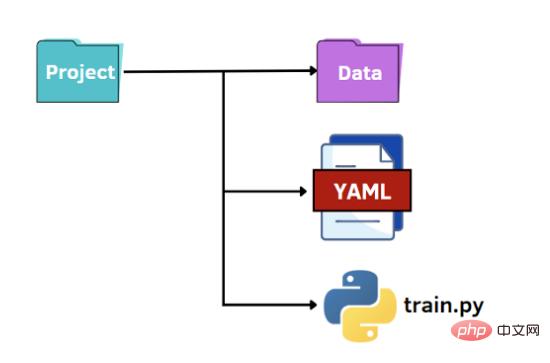
Die letzte Möglichkeit besteht darin, das Potenzial von YAML zu nutzen. Wie bei JSON-Dateien lesen wir die YAML-Datei im Python-Code als Wörterbuch, um auf die Werte der Hyperparameter zuzugreifen. YAML ist eine für Menschen lesbare Datendarstellungssprache, in der Hierarchien mit doppelten Leerzeichen anstelle von Klammern wie in JSON-Dateien dargestellt werden. Unten zeigen wir, was die Datei „options.yaml“ enthalten wird:
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
In train.py öffnen wir die Datei „options.yaml“, die immer mit der Load-Methode in ein Python-Wörterbuch konvertiert wird, dieses Mal aus der Yaml-Bibliothek importiert:
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)Wie zuvor können wir mithilfe der für ein Wörterbuch erforderlichen Syntax auf den Wert des Hyperparameters zugreifen.
Profile lassen sich sehr schnell kompilieren, wohingegen argparse das Schreiben einer Codezeile für jedes Argument erfordert, das wir hinzufügen möchten.
Daher sollten wir je nach Situation die am besten geeignete Methode wählen.
Wenn wir beispielsweise Kommentare zu Parametern hinzufügen müssen, ist JSON nicht geeignet, da es keine Kommentare zulässt, während YAML und argparse möglicherweise sehr gut geeignet sind.
Das obige ist der detaillierte Inhalt vonDrei Möglichkeiten zum Parsen von Parametern in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



