

 Technologie-Peripheriegeräte
KI
Sogar das jahrhundertealte Meme ist klar! Microsofts multimodales „Universum' bewältigt IQ-Tests mit nur 1,6 Milliarden Parametern
Technologie-Peripheriegeräte
KI
Sogar das jahrhundertealte Meme ist klar! Microsofts multimodales „Universum' bewältigt IQ-Tests mit nur 1,6 Milliarden Parametern
Sogar das jahrhundertealte Meme ist klar! Microsofts multimodales „Universum' bewältigt IQ-Tests mit nur 1,6 Milliarden Parametern

Ich kann mit der Menge großer Modelle nicht mithalten, ohne zu schlafen...
Nein, das Microsoft Asia Research Institute hat gerade ein multimodales großes Sprachmodell (MLLM) veröffentlicht – KOSMOS -1.

Adresse der Abschlussarbeit: https://arxiv.org/pdf/2302.14045.pdf
Der Titel der Abschlussarbeit „Sprache ist nicht alles, was Sie brauchen“ stammt von einem berühmten Sprichwort.
In dem Artikel steht ein Satz: „Die Grenzen meiner Sprache sind die Grenzen meiner Welt. – österreichischer Philosoph Ludwig Wittgenstein“

Dann kommt die Frage.. . ...
Machen Sie das Foto und fragen Sie KOSMOS-1 „Ist es eine Ente oder ein Kaninchen?“ Dieses Meme mit einer mehr als 100-jährigen Geschichte kann Google AI einfach nicht reparieren.
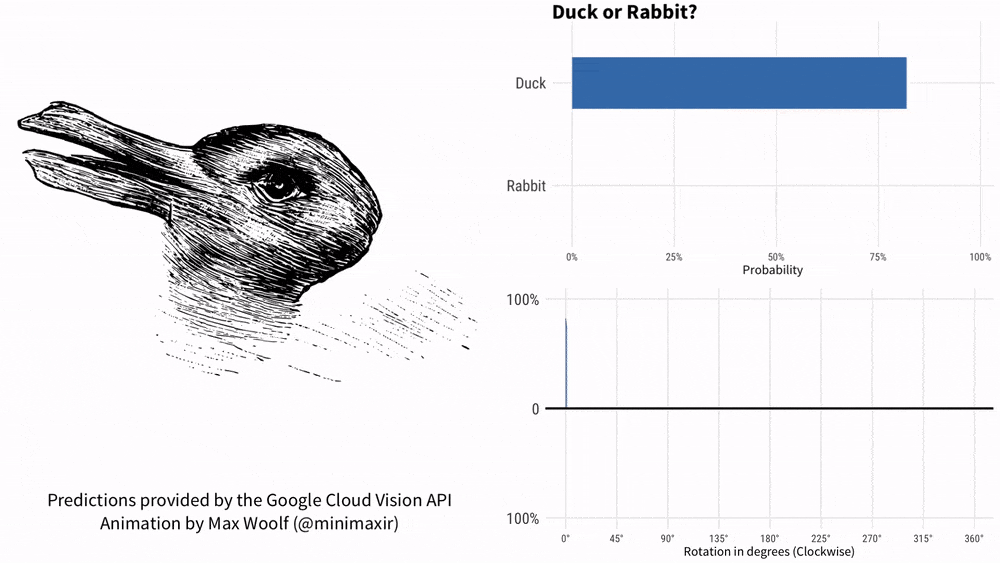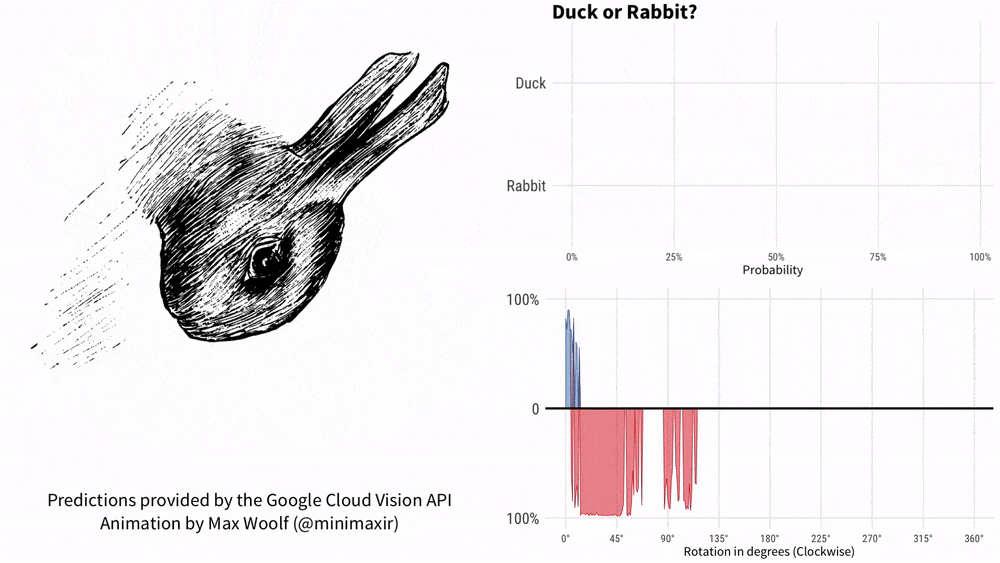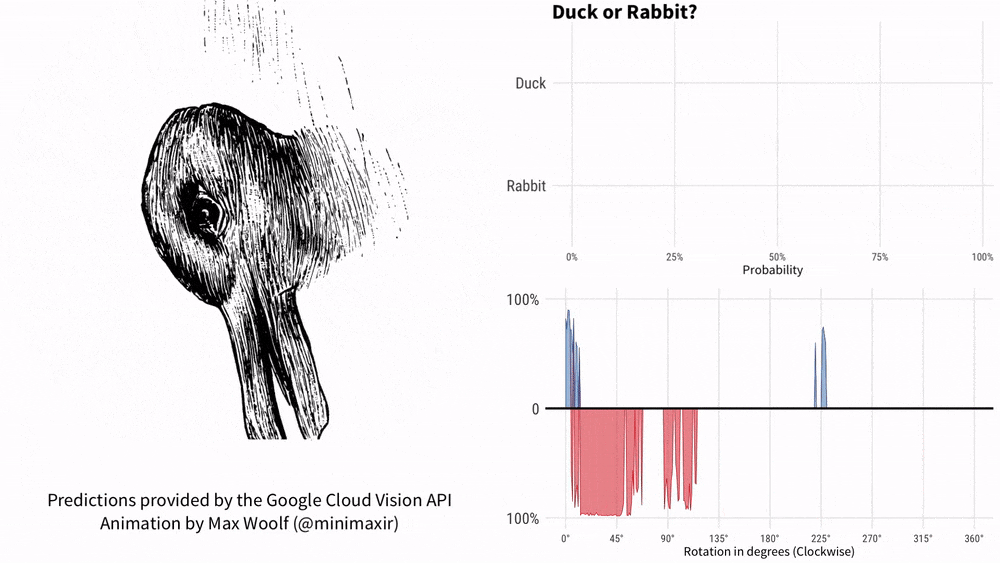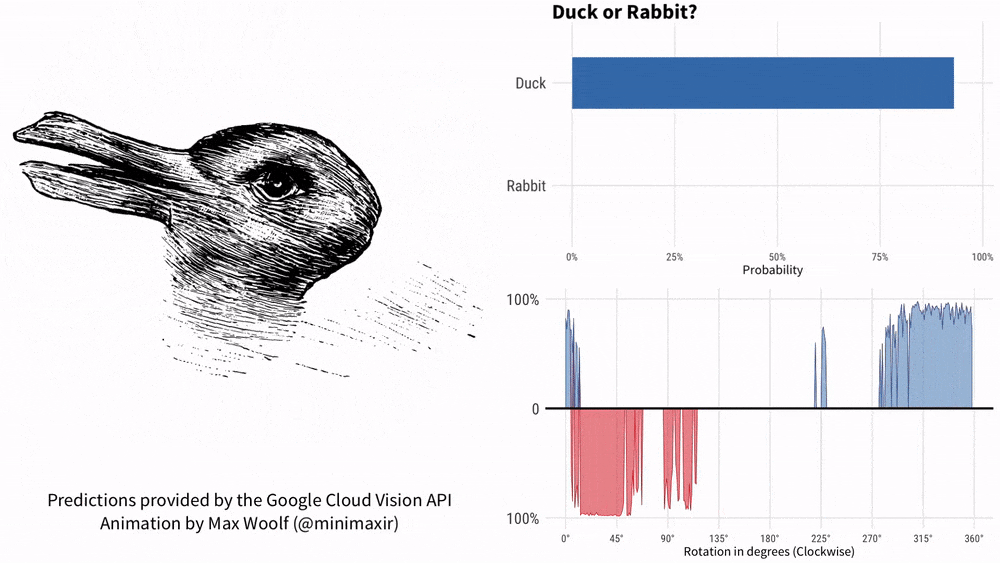
Im Jahr 1899 verwendete der amerikanische Psychologe Joseph Jastrow erstmals das „Enten-und-Kaninchen-Diagramm“, um zu zeigen, dass Wahrnehmung nicht nur das ist, was Menschen sehen, sondern auch eine geistige Aktivität.
Jetzt kann KOSMOS-1 dieses Wahrnehmungs- und Sprachmodell kombinieren.
-Was ist auf dem Bild?
– wie eine Ente.
- Wenn nicht eine Ente, was ist das dann?
-Sieht eher aus wie ein Kaninchen.
- Warum?
-Es hat Hasenohren.
Wie Sie fragen, ist KOSMOS-1 wirklich ein bisschen wie Microsofts Version von ChatGPT.

Darüber hinaus kann Kosmos-1 auch Bilder, Text, Bilder mit Text, OCR, Bildunterschriften und visuelle Qualitätssicherung verstehen.
Auch IQ-Tests sind kein Problem.
„Universum“ ist allmächtig
Kosmos kommt vom griechischen Wort Kosmos, was „Universum“ bedeutet.
Dem Papier zufolge ist das neueste Kosmos-1-Modell ein multimodales Sprachmodell im großen Maßstab.
Das Rückgrat ist ein auf Transformer basierendes kausales Sprachmodell. Neben Text können auch andere Modalitäten wie Vision und Audio in das Modell eingebettet werden.
Der Transformer-Decoder dient als universelle Schnittstelle für multimodale Eingaben, sodass er allgemeine Modalitäten wahrnehmen, Kontextlernen durchführen und Anweisungen befolgen kann.
Kosmos-1 erreicht beeindruckende Leistungen bei Sprach- und multimodalen Aufgaben ohne Feinabstimmung, einschließlich Bilderkennung mit Textanweisungen, visueller Beantwortung von Fragen und multimodalem Dialog.
Im Folgenden finden Sie einige von Kosmos-1 generierte Beispielstile.
Bildinterpretation, Fragen und Antworten zu Bildern, Antworten auf Webseitenfragen, einfache Zahlenformeln und Zahlenerkennung.

Also, auf welchen Datensätzen ist Kosmos-1 vorab trainiert?
Für Schulungen verwendete Datenbanken, einschließlich Textkorpora, Bild-Untertitel-Paare, Bild- und Text-Kreuzdatensätze.
Der Textkorpus stammt aus The Pile und Common Crawl (CC);
Die Quellen für Bildunterschriftenpaare sind Englisch LAION-2B, LAION-400M, COYO-700M und Conceptual Captions ;
Die Quelle des Textschnittpunktdatensatzes ist Common Crawl Snapshot.
Da die Datenbank nun verfügbar ist, besteht der nächste Schritt darin, das Modell vorab zu trainieren.
Die MLLM-Komponente verfügt über 24 Schichten, 2.048 versteckte Dimensionen, 8.192 FFNs und 32 Aufmerksamkeitsköpfe, was ungefähr 1,3 Milliarden Parameter ergibt.
Um die Stabilität der Optimierung sicherzustellen, wird die Magneto-Initialisierung für eine schnellere Konvergenz verwendet. Die Bilddarstellung wird von einem vorab trainierten CLIP ViT-L/14-Modell mit 1024 Feature-Dimensionen erhalten. Während des Trainingsprozesses werden Bilder auf eine Auflösung von 224 x 224 vorverarbeitet und die Parameter des CLIP-Modells werden bis auf die letzte Ebene eingefroren.
Die Gesamtzahl der Parameter von KOSMOS-1 beträgt etwa 1,6 Milliarden.
Um KOSMOS-1 besser mit den Anweisungen in Einklang zu bringen, wurden nur sprachliche Anweisungsanpassungen [LHV+23, HSLS22] vorgenommen, d. h. die Anweisungsdaten werden verwendet, um das Modell weiter zu trainieren. und die Anweisungsdaten sind nur einige Sprachdaten werden mit dem Trainingskorpus gemischt.
Der Optimierungsprozess wird gemäß der Sprachmodellierungsmethode durchgeführt, und die ausgewählten Befehlsdatensätze sind unnatürliche Anweisungen [HSLS22] und FLANv2 [LHV + 23].
Die Ergebnisse zeigen, dass die Verbesserung der Befehlsfolgefähigkeit auf alle Modi übertragen werden kann.
Kurz gesagt, MLLM kann vom modalübergreifenden Transfer profitieren, indem Wissen von der Sprache auf die Multimodalität übertragen wird und umgekehrt;
5 Hauptkategorien und 10 Aufgaben, die alle gemeistert werden
Ob ein Model Ob es gut funktioniert oder nicht, lässt sich feststellen, indem man es herausnimmt und herumläuft.
Das Forschungsteam führte Experimente aus mehreren Perspektiven durch, um die Leistung von KOSMOS-1 zu bewerten, darunter zehn Aufgaben in 5 Kategorien:
1 Sprachaufgaben (Sprachverständnis, Sprachgenerierung, Textklassifizierung ohne OCR )
2 Multimodaler Transfer (Common Sense Reasoning)
3 Nonverbales Denken (IQ-Test)
4 Wahrnehmungssprachliche Aufgaben (Bildbeschreibung, visuelle Frage und Antwort, Frage und Antwort auf der Webseite) )
5 Sehaufgaben (Zero-Shot-Bildklassifizierung, Zero-Shot-Bildklassifizierung mit Beschreibung)
# 🎜🎜#Textklassifizierung ohne OCR
Dies ist eine Art Textklassifizierung, die dies nicht tut verlassen sich auf die optische Zeichenerkennung (OCR), die sich auf Text- und Bildverständnisaufgaben konzentriert.
KOSMOS-1 weist bei HatefulMemes und dem Rendered SST-2-Testsatz eine höhere Genauigkeit auf als andere Modelle.
Obwohl Flamingo explizit OCR-Text in die Eingabeaufforderung einfügt, greift KOSMOS-1 nicht auf externe Tools oder Ressourcen zu, was KOSMOS demonstriert – 1 Intrinsische Fähigkeit, Text in gerenderten Bildern zu lesen und zu verstehen.
IQ. Test#🎜🎜 #
Der Raven Intelligence Test ist einer der am häufigsten verwendeten Tests zur Beurteilung der nonverbalen Sprache.
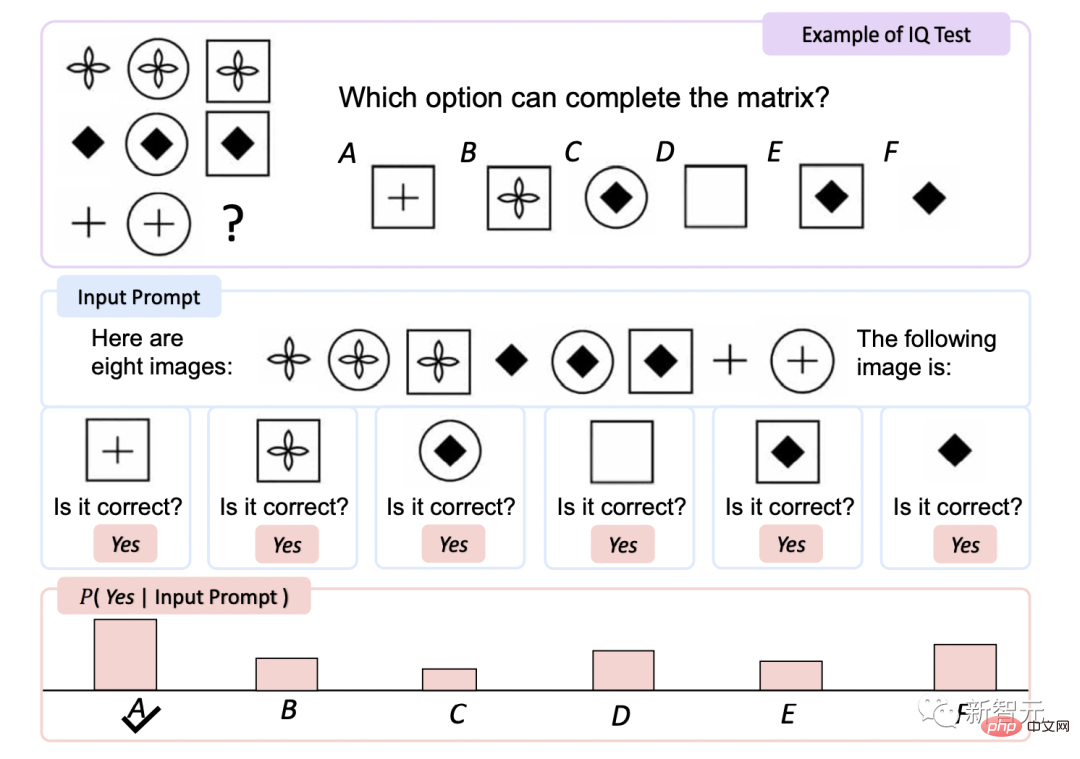
KOSMOS-1 wurde nicht durchgeführt Die Genauigkeit erhöhte sich im Vergleich zur Zufallsauswahl während der Feinabstimmung um 5,3 % und nach der Feinabstimmung um 9,3 %, was auf die Fähigkeit hindeutet, abstrakte Konzeptmuster in nichtsprachlichen Umgebungen wahrzunehmen.
Dies ist das erste Mal, dass ein Modell den Zero-Shot-Raven-Test abschließen konnte und damit beweist, dass MLLMs Zero-Shot-Raven-Tests durchführen können. Schusstests durch Kombination von Wahrnehmung mit Sprachmodellen Das Potenzial des nonverbalen Denkens. Bildunterschrift
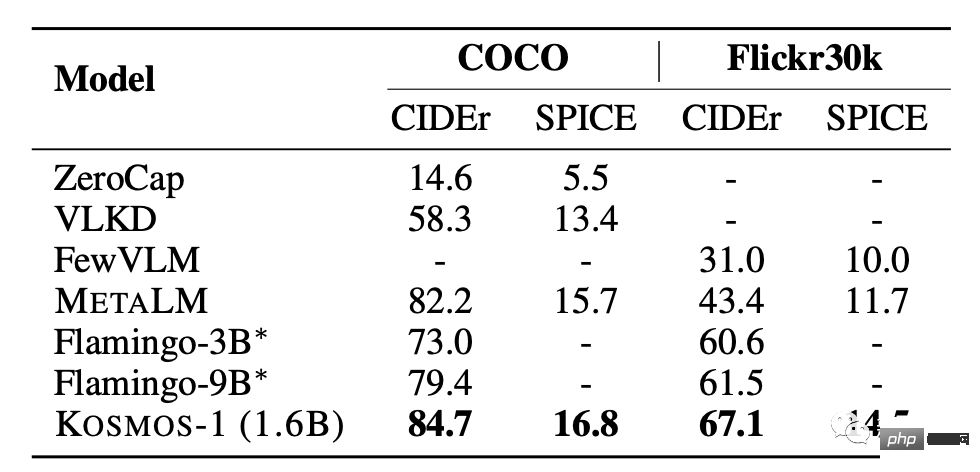
KOSMOS-1 weist im COCO- und Flickr30k-Test im Vergleich zu anderen Modellen eine hervorragende Leistung ohne Stichprobe auf , Es erzielt eine höhere Punktzahl, verwendet jedoch eine geringere Anzahl von Parametern. Beim Leistungstest mit wenigen Stichproben steigt die Punktzahl mit zunehmendem k-Wert.

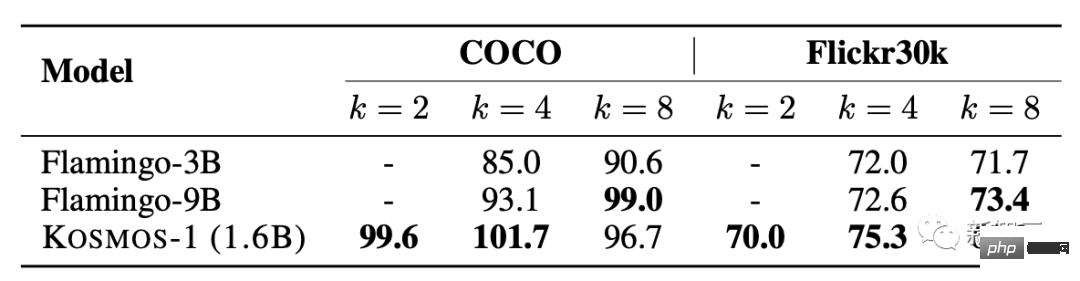
Null Probe Bildklassifizierung
Gegebenes Eingabebild, verbinden Sie das Bild mit der Eingabeaufforderung „Das Foto von“. Anschließend füttern Sie das Modell, um den Klassennamen des Bildes zu erhalten.
über ImageNet [DDS+ 09] Um das Modell sowohl unter eingeschränkten als auch unter uneingeschränkten Bedingungen zu bewerten, ist der Bildklassifizierungseffekt von KOSMOS-1 deutlich besser als der von GIT [WYH+22], was seine leistungsstarke Fähigkeit zur Erledigung visueller Aufgaben demonstriert. Gesunder Menschenverstand
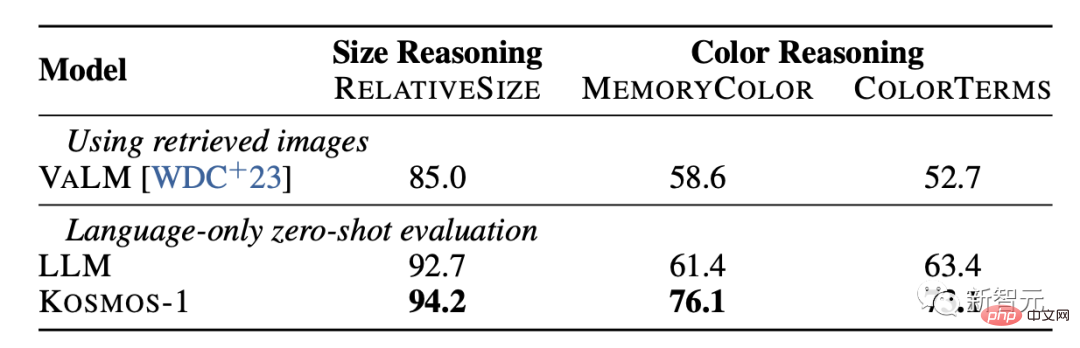
Aufgaben zum visuellen Denken mit gesundem Menschenverstand erfordern, dass Modelle die Eigenschaften von Alltagsgegenständen in der realen Welt verstehen, wie z. B. Farbe, Größe und Form. Diese Aufgaben sind anspruchsvoll, da sie möglicherweise mehr Informationen erfordern als diejenigen, die im Text zu finden sind.
Die Ergebnisse zeigen, dass die Denkfähigkeit von KOSMOS-1 hinsichtlich Größe und Farbe deutlich besser ist als die des LLM-Modells. Dies liegt vor allem daran, dass KOSMOS-1 über multimodale Transferfähigkeiten verfügt, die es ihm ermöglichen, visuelles Wissen auf Sprachaufgaben anzuwenden, ohne wie LLM auf Textwissen und Hinweise zum Denken angewiesen zu sein.
# 🎜 🎜# In Bezug auf Microsoft Kosmos-1 lobten Internetnutzer, dass ich mir in den nächsten 5 Jahren einen fortschrittlichen Roboter vorstellen kann, der im Internet surft und auf der Grundlage menschlicher Texteingabe ausschließlich mit visuellen Mitteln arbeitet. Was für interessante Zeiten.

Das obige ist der detaillierte Inhalt vonSogar das jahrhundertealte Meme ist klar! Microsofts multimodales „Universum' bewältigt IQ-Tests mit nur 1,6 Milliarden Parametern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert