


Künstliche Intelligenz ist in den letzten Jahren zu einem der am meisten diskutierten Themen geworden, und Dienste, die einst als reine Science-Fiction galten, werden dank der Entwicklung neuronaler Netze nun Realität. Von Konversationsagenten bis hin zur Generierung von Medieninhalten verändert künstliche Intelligenz die Art und Weise, wie wir mit Technologie interagieren. Insbesondere Modelle des maschinellen Lernens (ML) haben im Bereich der Verarbeitung natürlicher Sprache (NLP) erhebliche Fortschritte gemacht. Ein entscheidender Durchbruch ist die Einführung der „Selbstaufmerksamkeit“ und der Transformers-Architektur für die Sequenzverarbeitung, die die Lösung mehrerer Schlüsselprobleme ermöglicht, die zuvor auf diesem Gebiet vorherrschten.
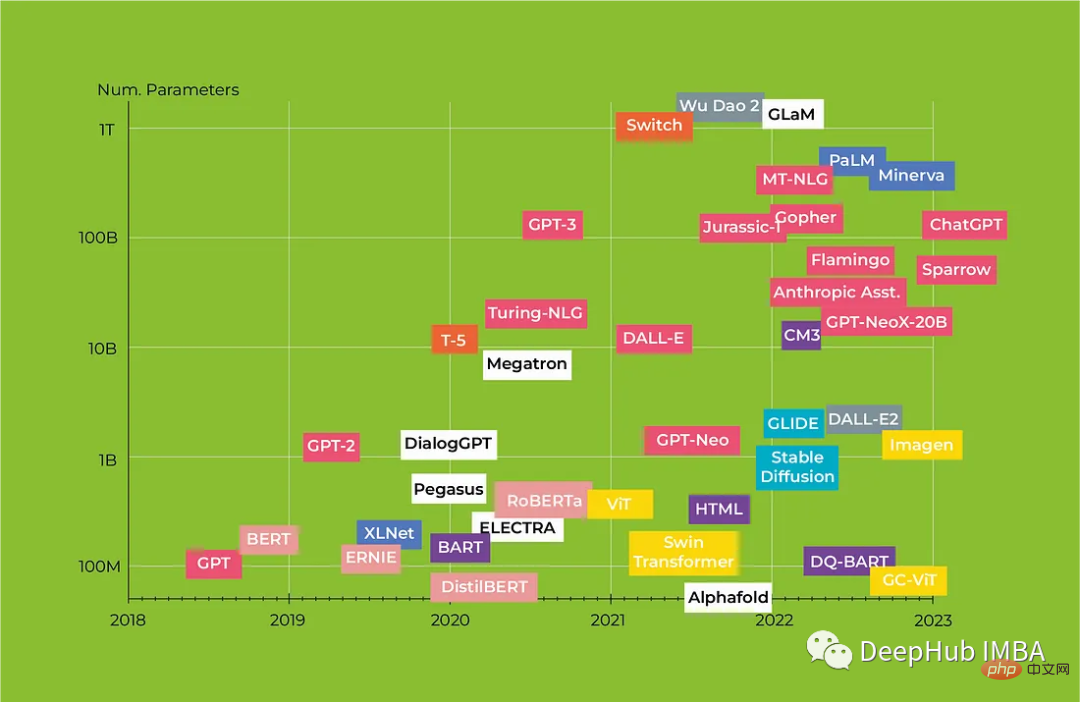
In diesem Artikel werfen wir einen Blick auf die revolutionäre Transformers-Architektur und wie sie NLP verändert. Wir werden auch einen umfassenden Überblick über die Transformers-Modelle von BERT bis Alpaca geben und uns dabei auf die Hauptmerkmale jedes Modells konzentrieren seine möglichen Anwendungen.
Der erste Teil ist ein auf dem Transformer-Encoder basierendes Modell, das für Vektorisierung, Klassifizierung, Sequenzkennzeichnung, QA (Frage und Antwort), NER (Named Entity Recognition) usw. verwendet wird.
Transformer-Encoder, Wortstück-Tokenisierung (30.000 Vokabeln). Die Eingabeeinbettung besteht aus drei Vektoren: einem Beschriftungsvektor, einem trainierbaren Positionsvektor und einem Fragmentvektor (entweder erster Text oder zweiter Text). Die Modelleingaben sind die CLS-Token-Einbettung, die Einbettung des ersten Texts und die Einbettung des zweiten Texts.
BERT hat zwei Trainingsaufgaben: Masked Language Modeling (MLM) und Next Sentence Prediction (NSP). Im MLM werden 15 % der Token maskiert, 80 % werden durch MASK-Token ersetzt, 10 % werden durch zufällige Token ersetzt und 10 % bleiben unverändert. Das Modell sagt die richtigen Token voraus und der Verlust wird nur für diese 15 % der blockierten Token berechnet. In NSP sagt das Modell voraus, ob der zweite Text auf den ersten Text folgt. Es werden Vorhersagen über den Ausgabevektor von CLS-Tokens getroffen.
Um das Training zu beschleunigen, werden zunächst 90 % des Trainings mit einer Sequenzlänge von 128 Token durchgeführt und dann werden die restlichen 10 % der Zeit damit verbracht, das Modell mit 512 Token zu trainieren, um effektivere Positionseinbettungen zu erhalten.
Eine verbesserte Version von BERT, die nur auf MLM trainiert wird (da NSP als weniger nützlich gilt) und die Trainingssequenz länger ist (512 Token). Mithilfe der dynamischen Maskierung (verschiedene Token werden maskiert, wenn dieselben Daten erneut verarbeitet werden) werden Trainingshyperparameter sorgfältig ausgewählt.
XLM hat zwei Trainingsaufgaben: MLM und Übersetzung. Die Übersetzung eines Textpaars ist im Wesentlichen dasselbe wie MLM, aber die Texte sind parallele Übersetzungen voneinander, mit zufälligen Masken und Segmenteinbettungen, die die Sprache kodieren.
4. Transformer-XL Carnegie Mellon University / 2019
Lange Texte werden in Segmente unterteilt und segmentweise abgearbeitet. Die Ausgabe des vorherigen Segments wird zwischengespeichert, und bei der Berechnung der Selbstaufmerksamkeit im aktuellen Segment werden die Schlüssel und Werte basierend auf der Ausgabe des aktuellen Segments und des vorherigen Segments (nur miteinander verkettet) berechnet. Auch der Gradient wird nur innerhalb des aktuellen Segments berechnet.
Diese Methode funktioniert nicht mit absoluten Positionen. Daher wird die Aufmerksamkeitsgewichtsformel im Modell neu parametrisiert. Der Codierungsvektor für die absolute Position wird durch eine feste Matrix ersetzt, die auf dem Sinus des Abstands zwischen Markerpositionen und einem trainierbaren Vektor basiert, der allen Positionen gemeinsam ist.
5. ERNIE Tsinghua University, Huawei / 2019
6. XLNet Carnegie Mellon University / 2019
XLNet basiert auf Transformer-XL, mit Ausnahme von PLM-Aufgaben (Replacement Language Modeling), bei denen es lernt, Token in kurzen Kontexten vorherzusagen, anstatt MASK direkt zu verwenden. Dadurch wird sichergestellt, dass Farbverläufe für alle Markierungen berechnet werden und keine speziellen Maskenmarkierungen erforderlich sind.
Die Token im Kontext sind verschlüsselt (zum Beispiel: Der i-te Token kann basierend auf den i-2- und i+1-ten Token vorhergesagt werden), aber ihre Positionen sind immer noch bekannt. Dies ist mit aktuellen Positionskodierungen (einschließlich Transformer-XL) nicht möglich. Beim Versuch, die Wahrscheinlichkeit eines Tokens in einem gegebenen Kontext vorherzusagen, sollte das Modell nicht das Token selbst kennen, sondern die Position des Tokens im Kontext. Um dieses Problem zu lösen, teilen sie die Selbstaufmerksamkeit in zwei Streams auf:
Wenn Sie während der Feinabstimmung den Abfragevektor ignorieren, funktioniert das Modell wie ein normaler Transformer-XL.
In der Praxis erfordert das Modell, dass der Kontext lang genug sein muss, damit das Modell richtig lernen kann. Es lernte mit der gleichen Datenmenge wie RoBERTa und erzielte ähnliche Ergebnisse, aber aufgrund der Komplexität der Implementierung wurde das Modell nicht so populär wie RoBERTa.
Vereinfachen Sie BERT ohne Qualitätseinbußen:
Das Modell ist auf MLM und Sentence Order Prediction (SOP) trainiert.
Eine weitere Möglichkeit, BERT zu optimieren, ist die Destillation:
Mehrsprachiges Vektorisierungsmodell basierend auf BERT. Es wird auf MLM und TLM trainiert (20 % der Marker sind maskiert) und dann fein abgestimmt. Es unterstützt über 100 Sprachen und enthält 500.000 getaggte Vokabeln.
Verwenden Sie die generative kontradiktorische Methode, um das BERT-Training zu beschleunigen:
Ein weiteres Modell, das den Inhalt und die Position des Markierungsvektors in zwei separate Vektoren trennt:
Zwei neue Gewichtsmatrizen K_pos und Q_pos für sie hinzugefügt.
wird verwendet
Der verwendete Tokenizer ist BPE auf Byte-Ebene (50K-Vokabular) und verwendet keine ähnlichen Teilzeichenfolgen wie („Hund“, „Hund!“, „Hund.“). Die maximale Sequenzlänge beträgt 1024. Die Layer-Ausgabe speichert alle zuvor generierten Tags zwischen. 2, T5 Google/2019 Ausgabevorhersagesequenz
< Relative Positionskodierung verwenden: Positionen werden durch lernbare Einbettungen kodiert, wobei jede „Einbettung“ nur ein Skalar ist, der bei der Berechnung der Aufmerksamkeitsgewichte den entsprechenden Logit hinzufügt.Matrix B wird auf allen Ebenen gemeinsam genutzt, ist jedoch für verschiedene Selbstaufmerksamkeitsköpfe unterschiedlich. Jede Schicht berücksichtigt 128 Abstände zwischen Token und Nullen, den Rest ausgenommen, was Rückschlüsse auf längere Sequenzen im Vergleich zu denen ermöglicht, die während des Trainings beobachtet wurden. Die Tokenisierung erfolgt mithilfe von Sentencepece (32K-Vokabular) mit einer maximalen Sequenzlänge von 512 während des Vortrainings. 3. BART Facebook / 2019
Ein weiterer vollständiger Transformator, der jedoch GeLU anstelle von ReLU verwendet. Trainieren Sie es, um Originaltext aus verrauschtem Text (AE-Entrauschen) mit den folgenden Rauschtypen vorherzusagen:Token-Maskierung
Token-Entfernung
Token-Auffüllen
Token-Reihenfolge in Sätzen umgekehrt
Dieses Modell ähnelt konzeptionell dem Switch Transformer, konzentriert sich jedoch mehr auf die Arbeit im Modus mit wenigen Aufnahmen als auf die Feinabstimmung. Modelle unterschiedlicher Größe verwenden 32 bis 256 Expertenebenen, K=2. Verwenden Sie die relative Positionskodierung von Transformer-XL. Bei der Verarbeitung von Token werden weniger als 10 % der Netzwerkparameter aktiviert.
8, LaMDA Google / 2021Ein GPT-ähnliches Modell. Das Modell ist ein Konversationsmodell, das auf kausalem LM vortrainiert und auf Generierungs- und Unterscheidungsaufgaben abgestimmt ist. Das Modell kann auch externe Systeme aufrufen (Suche, Übersetzung). 9. GPT-NeoX-20B EleutherAI / 2022Dieses Modell ähnelt GPT-J und verwendet ebenfalls eine Rotationspositionskodierung. Modellgewichte werden durch float16 dargestellt. Die maximale Sequenzlänge beträgt 2048. 10, BLOOM BigScience / 2022Dies ist das größte Open-Source-Modell in 46 Sprachen und 13 Programmiersprachen. Zum Trainieren des Modells wird ein großer aggregierter Datensatz namens ROOTS verwendet, der etwa 500 offene Datensätze umfasst. 11, PaLM Google / 2022Dies ist ein großes mehrsprachiges Decodermodell, das mit Adafactor trainiert wurde, Dropout während des Vortrainings deaktiviert und während der Feinabstimmung 0,1 verwendet. 12, LLaMA Meta/2023Ein Open-Source-GPT-ähnlicher LM in großem Maßstab für die wissenschaftliche Forschung, der zum Trainieren mehrerer Unterrichtsmodelle verwendet wurde. Das Modell verwendet Pre-LayerNorm, SwiGLU-Aktivierung und RoPE-Positionseinbettung. Da es Open Source ist, ist dies eines der Hauptmodelle für das Überholen in Kurven. Leitmodelle für TextDiese Modellerfassungen werden zur Korrektur von Modellausgaben (z. B. RLHF) verwendet, um die Antwortqualität während des Dialogs und der Aufgabenlösung zu verbessern. 1. InstructGPT OpenAI/2022Diese Arbeit passt GPT-3 an, um Anweisungen effizient zu befolgen. Das Modell basiert auf einem Datensatz, der aus Hinweisen und Antworten besteht, die Menschen aufgrund einer Reihe von Kriterien für gut halten. Basierend auf InstructGPT hat OpenAI ein Modell erstellt, das wir heute als ChatGPT kennen. 2, Flan-T5 Google / 2022Leitmodell passend für T5. Bei einigen Aufgaben übertraf der Flan-T5 11B den PaLM 62B ohne diese Feinabstimmung. Diese Modelle wurden als Open Source veröffentlicht. 3. Sparrow DeepMind / 2022Das Grundmodell wird durch die Feinabstimmung von Chinchilla auf ausgewählte hochwertige Gespräche erhalten, wobei die ersten 80 % der Ebenen eingefroren werden. Anschließend wurde das Modell mithilfe einer großen Eingabeaufforderung weiter trainiert, um es durch das Gespräch zu führen. Zusätzlich zu Chinchilla werden auch mehrere Belohnungsmodelle trainiert. Das Modell kann auf eine Suchmaschine zugreifen und Snippets mit bis zu 500 Zeichen abrufen, die zu Antworten werden können. Während der Inferenz wird das Belohnungsmodell zur Einstufung der Kandidaten verwendet. Kandidaten werden entweder vom Modell generiert oder aus der Suche gewonnen, und dann wird der beste Kandidat zur Antwort.Das Führungsmodell von LLaMA oben. Das Hauptaugenmerk liegt auf dem Prozess der Erstellung eines Datensatzes mit GPT-3:
Insgesamt wurden 52.000 einzigartige Triples auf LLaMA 7B generiert und verfeinert.
Dies ist eine Feinabstimmung von LLaMA auf Unterrichtsdaten, aber im Gegensatz zu Alpaca oben ist es nicht nur auf GPT feinabgestimmt. 3 usw. Feinabstimmung der von großen Modellen generierten Daten. Die Zusammensetzung des Datensatzes ist:
4, Imagen Google / 2022
Die Hauptidee hinter Imagen ist, dass eine Vergrößerung des Text-Encoders mehr Vorteile für das generative Modell bringen kann als eine Vergrößerung des DM. Daher wurde CLIP durch T5-XXL ersetzt.
Modelle zum Generieren von Text aus Bildern
1、CoCa Google / 2022
Das 288x288-Bild wird in 18x18-Blöcke geschnitten und der Encoder wandelt es in einen Vektor + einen gemeinsamen Aufmerksamkeitspool-Vektor basierend auf all diesen Vektoren um.
Die Gewichte der beiden Verluste sind:
Die Ähnlichkeit zwischen dem Aufmerksamkeitspoolvektor des Bildes und dem CLS-Tag-Vektor des Textes der Bildbeschreibung Paar. Autoregressiver Verlust der gesamten Decoder-Ausgabe (bedingt durch das Bild).Das Bild wird von ViT kodiert, der Ausgabevektor sowie Text-Tokens und Befehle werden in PaLM eingespeist und PaLM generiert den Ausgabetext.
PaLM-E wird für alle Aufgaben einschließlich VQA, Objekterkennung und Roboterbedienung verwendet.
Dies ist ein geschlossenes Modell mit wenigen bekannten Details. Vermutlich verfügt es über einen Decoder mit spärlicher Aufmerksamkeit und multimodalen Eingaben. Es verwendet autoregressives Training und Feinabstimmung von RLHF mit Sequenzlängen von 8K bis 32K.
Es wurde in menschlichen Untersuchungen mit null und wenigen Proben getestet und erreichte menschenähnliche Werte. Es kann bildbasierte Probleme (einschließlich mathematischer Probleme) sofort und Schritt für Schritt lösen, Bilder verstehen und interpretieren sowie Code analysieren und generieren. Auch für verschiedene Sprachen geeignet, auch für Minderheitensprachen.
Das Folgende ist eine kurze Schlussfolgerung. Sie können unvollständig oder einfach falsch sein und dienen nur als Referenz.
Nachdem automatische Grafikkarten nicht mehr abgebaut werden konnten, schwärmten verschiedene Großmodelle ein und die Basis der Modelle wuchs, aber die einfache Erhöhung der Schichten und das Wachstum der Datensätze wurden durch verschiedene bessere Technologien ersetzt, die dies ermöglichen Qualitätsverbesserungen (Nutzung externer Daten und Tools, verbesserte Netzwerkstrukturen und neue Feinabstimmungstechniken). Eine wachsende Zahl von Arbeiten zeigt jedoch, dass die Qualität der Trainingsdaten wichtiger ist als die Quantität: Durch die richtige Auswahl und Bildung von Datensätzen kann die Trainingszeit verkürzt und die Qualität der Ergebnisse verbessert werden.
OpenAI geht jetzt zu Closed Source, sie haben versucht, die Gewichte von GPT-2 nicht zu veröffentlichen, sind aber gescheitert. Aber GPT4 ist eine Blackbox. Der Trend der letzten Monate, die Feinabstimmungskosten und die Inferenzgeschwindigkeit von Open-Source-Modellen zu verbessern, hat den Wert großer privater Modelle stark verringert, da auch Produkte von Open-Source-Modellen schnell aufholen Giganten in der Qualität, die das Überholen in Kurven wieder ermöglichen.
Die Zusammenfassung der endgültigen Open-Source-Modelle lautet wie folgt:
Die oben genannten Informationen dienen nur als Referenz.
Das obige ist der detaillierte Inhalt vonTransformers Review: Von BERT zu GPT4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



