


Transformer kann als NLP-Modellarchitektur vor dem Training effektiv auf großen, unbeschrifteten Daten lernen. Untersuchungen haben gezeigt, dass Transformer seit BERT die Kernarchitektur von NLP-Aufgaben ist.
Neuere Arbeiten haben gezeigt, dass Zustandsraummodelle (SSM) eine günstige konkurrierende Architektur für die Modellierung von Langstreckensequenzen sind. SSM erreicht modernste Ergebnisse bei der Spracherzeugung und bei Long Range Arena-Benchmarks, sogar besser als die Transformer-Architektur. Zusätzlich zur Verbesserung der Genauigkeit weist die auf SSM basierende Routingschicht mit zunehmender Sequenzlänge keine quadratische Komplexität auf.
In diesem Artikel schlagen Forscher der Cornell University, DeepMind und anderen Institutionen Bidirektionales Gating SSM (BiGS) für aufmerksamkeitsfreies Vortraining vor. Es kombiniert hauptsächlich SSM-Routing eine Architektur, die auf multiplikativem Gating basiert. Die Studie ergab, dass SSM allein beim Vortraining für NLP schlecht abschneidet, bei Integration in eine multiplikative Gated-Architektur jedoch die nachgelagerte Genauigkeit verbessert wird.
Experimente zeigen, dass BiGS die Leistung des BERT-Modells erreichen kann, wenn es mit denselben Daten unter kontrollierten Einstellungen trainiert wird. Durch zusätzliches Vortraining bei längeren Instanzen behält das Modell auch die lineare Zeit bei, wenn die Eingabesequenz auf 4096 skaliert wird. Die Analyse zeigt, dass multiplikatives Gating notwendig ist und einige spezifische Probleme von SSM-Modellen bei Texteingaben variabler Länge behebt.

Papieradresse: https://arxiv.org/pdf/2212.10544 .pdf
SSM verbindet den kontinuierlichen Eingang u (t) mit dem Ausgang y (t) durch die folgende Differentialgleichung: # 🎜🎜#
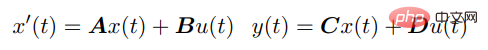
Für diskrete Sequenzen werden die SSM-Parameter diskretisiert und der Prozess kann wie folgt angenähert werden: #🎜🎜 Diese Gleichung kann als lineares RNN interpretiert werden, wobei x_k ein verborgener Zustand ist. y kann auch mithilfe von Faltung berechnet werden:
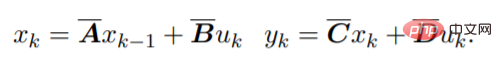 Gu et al. demonstrierten eine effektive Methode Methode entwickelten sie eine Methode zur Parametrisierung von A, genannt HiPPO, die zu einer stabilen und effizienten Architektur namens S4 führte. Dadurch bleibt die Fähigkeit von SSM erhalten, Langzeitsequenzen zu modellieren, und es ist gleichzeitig effizienter als das RNN-Training. Kürzlich haben Forscher eine vereinfachte diagonalisierte Version von S4 vorgeschlagen, die mit einer einfacheren Approximation der ursprünglichen Parameter ähnliche Ergebnisse erzielt. Auf hoher Ebene bietet SSM-basiertes Routing eine Alternative zur Modellierung von Sequenzen in neuronalen Netzen ohne den Aufmerksamkeitsaufwand für sekundäre Berechnungen.
Gu et al. demonstrierten eine effektive Methode Methode entwickelten sie eine Methode zur Parametrisierung von A, genannt HiPPO, die zu einer stabilen und effizienten Architektur namens S4 führte. Dadurch bleibt die Fähigkeit von SSM erhalten, Langzeitsequenzen zu modellieren, und es ist gleichzeitig effizienter als das RNN-Training. Kürzlich haben Forscher eine vereinfachte diagonalisierte Version von S4 vorgeschlagen, die mit einer einfacheren Approximation der ursprünglichen Parameter ähnliche Ergebnisse erzielt. Auf hoher Ebene bietet SSM-basiertes Routing eine Alternative zur Modellierung von Sequenzen in neuronalen Netzen ohne den Aufmerksamkeitsaufwand für sekundäre Berechnungen.
Modellarchitektur vor dem Training
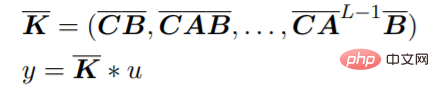
SSM kann vorab Aufmerksamkeit trainieren? Um diese Frage zu beantworten, betrachtet diese Studie zwei verschiedene Architekturen, die gestapelte Architektur (STACK) und die multiplikative Gated-Architektur (GATED), wie in Abbildung 1 dargestellt.
Die gestapelte Architektur mit Selbstaufmerksamkeit entspricht dem BERT/Transformer-Modell, und die Gated-Architektur ist eine bidirektionale Adaption der Gated-Unit, die ebenfalls kürzlich entwickelt wurde Wird für unidirektionales SSM verwendet. Zwei Sequenzblöcke (d. h. Vorwärts- und Rückwärts-SSM) mit multiplikativem Gating sind in einer Feedforward-Schicht eingebettet. Für einen fairen Vergleich wird die Größe der geschlossenen Architektur mit der der gestapelten Architektur vergleichbar gehalten. Abbildung 1: Modellvariablen. STACK ist eine Standard-Transformator-Architektur und GATED basiert auf Gate-Steuereinheiten. Für die Routing-Komponente (gestrichelte Linie) berücksichtigt die Studie sowohl bidirektionales SSM (in der Abbildung dargestellt) als auch standardmäßige Selbstaufmerksamkeit. Gated(X) steht für elementweise Multiplikation.
Vortraining
Tabelle 1 zeigt die Hauptergebnisse verschiedener vorab trainierter Modelle beim GLUE-Benchmark. BiGS reproduziert die Genauigkeit von BERT bei der Token-Erweiterung. Dieses Ergebnis zeigt, dass SSM mit einem solchen Rechenbudget die Genauigkeit des vorab trainierten Transformatormodells reproduzieren kann. Diese Ergebnisse sind deutlich besser als bei anderen nicht auf Aufmerksamkeit basierenden vorab trainierten Modellen. Um diese Genauigkeit zu erreichen, ist multiplikatives Gating erforderlich. Ohne Gating sind die Ergebnisse von gestapeltem SSM deutlich schlechter. Um zu untersuchen, ob dieser Vorteil hauptsächlich auf die Verwendung von Gating zurückzuführen ist, haben wir ein aufmerksamkeitsbasiertes Modell mithilfe der GATE-Architektur trainiert. Die Ergebnisse zeigen jedoch, dass das Modell tatsächlich weniger effektiv ist als BERT.
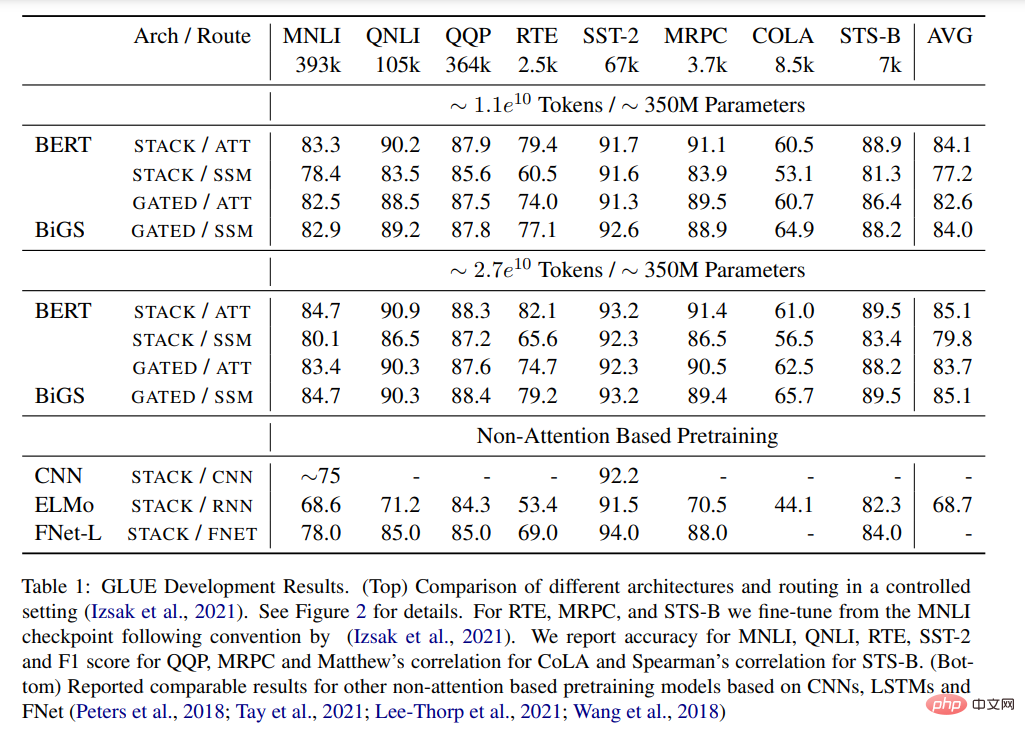
Tabelle 1: GLUE-Ergebnisse. (Oben) Vergleich verschiedener Architekturen und Routing-unter-Kontroll-Einstellungen. Einzelheiten finden Sie in Abbildung 2. (Unten) berichtete über vergleichbare Ergebnisse für andere vorab trainierte Nicht-Aufmerksamkeits-Modelle basierend auf CNN, LSTM und FNet.
Long-Form Task
Tabelle 2 Die Ergebnisse zeigen, dass SSM mit Longformer EncoderDecoder (LED) und BART verglichen werden kann, die Ergebnisse zeigen jedoch, dass es auch bei Remote-Aufgaben eine gute Leistung erbringt Noch besser. Im Vergleich zu den beiden anderen Methoden verfügt SSM über viel weniger Daten vor dem Training. Auch wenn SSM diese Längen nicht annähern muss, ist die lange Form dennoch wichtig.
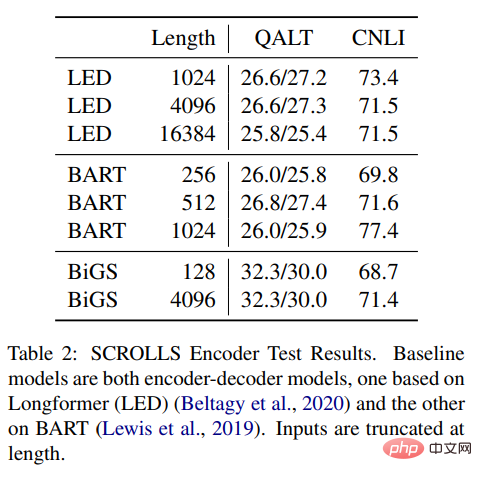
Tabelle 2: SCROLLS-Encoder-Testergebnisse. Die Basismodelle sind beide Encoder-Decoder-Modelle, eines basiert auf Longformer (LED) und das andere basiert auf BART. Die Eingabelänge wird gekürzt.
Weitere Informationen finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonDas Vortraining erfordert keine Aufmerksamkeit und die Skalierung auf 4096 Token ist kein Problem, was mit BERT vergleichbar ist.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie HTML-Dateien
So öffnen Sie HTML-Dateien
 Tutorial zur Linux-Systeminstallation
Tutorial zur Linux-Systeminstallation
 Analyse der ICP-Münzaussichten
Analyse der ICP-Münzaussichten
 Thunder VIP-Patch
Thunder VIP-Patch
 Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
 So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 Virtuelle Währungsumtauschplattform
Virtuelle Währungsumtauschplattform








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



