


这次要处理的excel有两个sheet,要根据其中一个sheet的数据来计算另外一个sheet的值。造成问题的点在于,要计算值的sheet里不仅仅有数值,还有公式。我们来看一下:
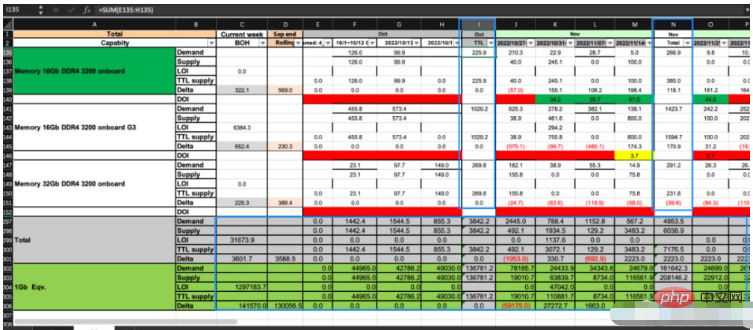
如上图所示,这个excel一共有两个sheet:CP和DS,我们要按照一定的业务规则,根据CP中的数据计算DS对应单元格的数据。图中蓝色方框框出来的是带公式的,而其他区域是数值。
我们来看看,如果我们按照之前说的处理逻辑,把excel一次性批量读取到dataframe处理,然后再一次性批量写回去有啥问题。这部分代码如下:
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "data/DS_format.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
#计算过程省略......
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()如上代码存在的问题在于,pd.read_excel()方法从excel里读取数据到dataframe的时候,对于有公式的单元格,会直接读取公式计算的结果(如果没有结果则返回Nan),而我们写入excel的时候是直接把dataframe一次性批量写回的,这样之前带公式的单元格,被写回的就是计算出来的值或Nan,而丢掉了公式。
好了,问题出现了,我们该如何解决呢?这里会想到两个思路:
dataframe写回excel的时候,不要一次性批量写回,而是通过行和列的迭代,只写回计算的数据,有公式的单元格不动;
读取excel的时候,有没有办法做到对于有公式的单元格,读取公式,而不是读取公式计算的结果;
我确实按照上面两个思路分别尝试了一下,我们一起来看一下。
如下代码尝试遍历dataframe然后按单元格写入对应的值,有公式的单元格不动
#根据ds_df来写excel,只写该写的单元格
for row_idx,row in ds_df.iterrows():
total_capabity_val = row[('Total','Capabity')].strip()
total_capabity1_val = row[('Total','Capabity.1')].strip()
#Total和1Gb Eqv.所在的行不写
if total_capabity_val!= 'Total' and total_capabity_val != '1Gb Eqv.':
#给Delta和LOI赋值
if total_capabity1_val == 'LOI' or total_capabity1_val == 'Delta':
ds_worksheet.range((row_idx + 3 ,3)).value = row[('Current week','BOH')]
print(f"ds_sheet的第{row_idx + 3}行第3列被设置为{row[('Current week','BOH')]}")
#给Demand和Supply赋值
if total_capabity1_val == 'Demand' or total_capabity1_val == 'Supply':
cp_datetime_columns = cp_df.columns[53:]
for col_idx in range(4,len(ds_df.columns)):
ds_datetime = ds_df.columns.get_level_values(1)[col_idx]
ds_month = ds_df.columns.get_level_values(0)[col_idx]
if type(ds_datetime) == str and ds_datetime != 'TTL' and ds_datetime != 'Total' and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',f'{ds_datetime}')]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',f'{ds_datetime}')]}")
elif type(ds_datetime) == datetime.datetime and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',ds_datetime)]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',ds_datetime)]}")如上的代码确实解决了问题,也即有公式的单元格的公式被保留了。但是,根据我们文章开头提到的Python处理excel的忠告,这个代码是有严重性能问题的,因为它通过api频繁操作excel的单元格,导致写入非常慢,在我的老迈Mac本上一共跑了40分钟,简直不可接受,故该方案只能放弃。
这个方案是希望做到读取excel有公式值的单元格的时候,能保留公式值。这只能从各个Python的excel库的API来寻找有无对应的方法了。Pandas的read_excel()方法我仔细看了一下没有对应的参数可以支持。Openpyxl我倒是找到了一个API可以支持,如下:
import openpyxl ds_format_workbook = openpyxl.load_workbook(fpath,data_only=False) ds_wooksheet = ds_format_workbook['DS'] ds_df = pd.DataFrame(ds_wooksheet.values)
关键是这里的data_only参数,为True则返回数据,为False的情况下可以保留公式值
本以为找到了对应解决方案正一顿窃喜,但当我看到通过openpyxl读取到dataframe中的数据结构的时候,才被破了一盆冷水。因为我的excel表的表头是比较复杂的两级的表头,表头中还存在合并和拆分单元格的情况,这样的表头被openpyxl读取到dataframe后,没有按照pandas的多级索引进行处理,而是简单的被处理成数字索引0123...
但我对dataframe的计算会依赖多级索引,因此openpyxl的这种处理方式导致我后面的计算无法处理。
openpyxl不行,再看看xlwings呢?通过对xlwings API文档的一通寻找,还真给我找到了,如下所示:
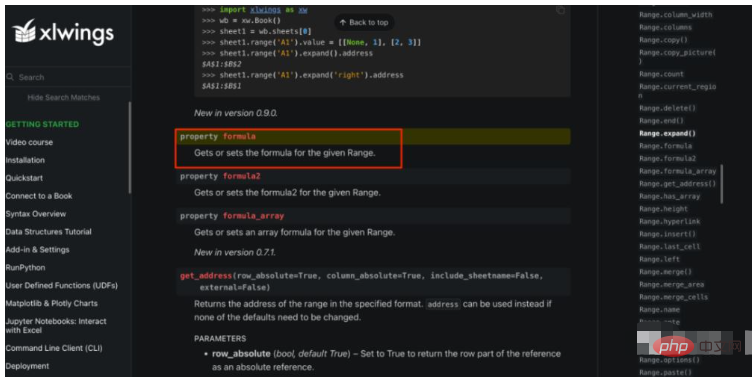
Range类提供了一个Property叫formula,可以获取和设置formula。
看到这个我简直如获至宝,赶紧代码操练起来。也许出于惯性,又或许是被之前按行列单元格操作excel的效率搞怕了,我直接先想到的方案还是一次性批量搞定,也即一次性读取excel所有的公式,然后再一次性写回去,所以我一开始的代码是这样的:
#使用xlwings来读取formula app = xw.App(visible=False,add_book=False) ds_format_workbook = app.books.open(fpath) ds_worksheet = ds_format_workbook.sheets["DS"] #先把所有公式一次性读取并保存下来 formulas = ds_worksheet.used_range.formula #中间计算过程省略... #一次性把所有公式写回去 ds_worksheet.used_range.formula = formulas
可是我想错了,ds_worksheet.used_range.formula让我误解只会返回excel中的有公式的单元格的公式,但其实它返回的是所有的单元格,只是对有公式的单元格保留了公式。所以,当我重新写回公式的时候,会覆盖掉我通过dataframe计算完并写入excel的其他的值。
既然这样的话,那我只能对有公式的单元格分别处理而不是一次性处理了,所以代码得这样写:
#使用xlwings来读取formula
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
#保留excel中的formula
#找到DS中Total所在的行,Total之后的行都是formula
row = ds_df.loc[ds_df[('Total','Capabity')]=='Total ']
total_row_index = row.index.values[0]
#获取对应excel的行号(dataframe把两层表头当做索引,从数据行开始计数,而且从0开始计数。excel从表头就开始计数,而且从1开始计数)
excel_total_row_idx = int(total_row_index+2)
#获取excel最后一行的索引
excel_last_row_idx = ds_worksheet.used_range.rows.count
#保留按日期计算的各列的formula
I_col_formula = ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula
N_col_formula = ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula
T_col_formula = ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula
U_col_formula = ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula
Z_col_formula = ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula
AE_col_formula = ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula
AK_col_formula = ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula
AL_col_formula = ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula
#保留Total行开始一直到末尾所有行的formula
total_to_last_formula = ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula
#中间计算过程省略...
#保存结果到excel
#直接把ds_df完整赋值给excel,会导致excel原有的公式被值覆盖
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
#用之前保留的formulas,重置公式
ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula = I_col_formula
ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula = N_col_formula
ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula = T_col_formula
ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula = U_col_formula
ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula = Z_col_formula
ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula = AE_col_formula
ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula = AK_col_formula
ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula = AL_col_formula
ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula = total_to_last_formula
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()经测试,如上代码完美地解决我的需求,而且性能上也完全没问题。
以上是Python如何处理Excel文件?的详细内容。更多信息请关注PHP中文网其他相关文章!
 Python-Entwicklungstools
Python-Entwicklungstools
 Python in ausführbare Datei gepackt
Python in ausführbare Datei gepackt
 was Python kann
was Python kann
 Vergleichen Sie die Ähnlichkeiten und Unterschiede zwischen zwei Datenspalten in Excel
Vergleichen Sie die Ähnlichkeiten und Unterschiede zwischen zwei Datenspalten in Excel
 Excel-Duplikatfilter-Farbmarkierung
Excel-Duplikatfilter-Farbmarkierung
 So verwenden Sie das Format in Python
So verwenden Sie das Format in Python
 So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
 Excel-Tabellen-Schrägstrich in zwei Teile geteilt
Excel-Tabellen-Schrägstrich in zwei Teile geteilt

























