


Zweck des Experiments.
Machen Sie sich mit der grundlegenden Datenstruktur von Python sowie der Eingabe und Ausgabe von Dateien vertraut.
Experimentelle Daten
Verwenden Sie die Bewertungsdaten und Bewertungsaufgaben der xx Machine Learning Conference in XXXX. Die Daten umfassen Trainingssätze und Testsätze. Die Bewertungsaufgabe besteht darin, vorherzusagen, ob die Beziehung im Testsatz positiv ist Negativbeispiel durch die angegebenen Trainingsdaten, was am Ende jeder Probe 1 oder 0 ergibt.
Die Daten werden wie folgt beschrieben: Die erste Spalte ist der Beziehungstyp, die zweite und dritte Spalte sind die Namen der Personen, die vierte Spalte ist der Titel, die fünfte Spalte ist, ob es sich bei der Beziehung um ein positives oder negatives Beispiel handelt. 1 ist ein positives Beispiel, 0 ist ein negatives Beispiel. Die sechste Spalte stellt den Trainingssatz dar.
| Ereignis | Charakter 1 | Charakter 2 | Titel | Beziehung (0 oder 1) | Trainingssatz |
|---|
Der Testsatz ist im Wesentlichen ähnlich wie Beim Trainingssatz besteht der einzige Unterschied darin, dass es in der fünften Spalte keine Rolle spielt, ob es sich um ein positives oder ein negatives Beispiel handelt.
| Beziehung | Charakter 1 | Charakter 2 | Ereignis |
|---|
Experimenteller Inhalt
Verarbeiten Sie die Trainingssatzdaten, lassen Sie nur die ersten fünf Spalten übrig und der Ausgabetext heißt exp1_1.txt.
Kategorie 19 Beziehungstypen basierend auf den im ersten Schritt erhaltenen Daten. Der generierte Text wird im Ordner exp1_train gespeichert. Entsprechend der Reihenfolge, in der die Beziehungskategorien angezeigt werden, werden die Daten der ersten Beziehungskategorie in 1 gespeichert. txt. Die zweite Beziehungskategorie wird in 2.txt bis 19.txt gespeichert.
Der Testsatz klassifiziert jede Stichprobe entsprechend der Beziehungskategorie in der Reihenfolge der 19 Kategorien des Trainingssatzes, dh die Daten desselben Beziehungstyps werden in eine Textdatei eingefügt, und Testdateien von 19 Kategorien werden ebenfalls in eine Textdatei eingefügt Das Format bleibt das gleiche wie bei der Testdatei. Die im Ordner exp1_test gespeicherten Dateien jeder Kategorie heißen weiterhin 1_test.txt, 2_test.txt ... Gleichzeitig wird die Position jeder Probe im ursprünglichen Testsatz aufgezeichnet und entspricht einer der 19 Testdateien um eins. Beispielsweise wird in der Indexdatei aufgezeichnet, welche Zeile sich jedes Beispiel der ersten Art von „gemunkelter Zwietracht“ im Originaltext befindet und in den Dateien index1.txt, index2.txt... gespeichert.
Ideen zur Problemlösung
1 .Die erste Frage besteht darin, unser Wissen über Dateioperationen und Listen zu testen. Nach der Verarbeitung wird eine TXT-Datei erstellt Implementierung:
rrree2. Die zweite Frage untersucht weiterhin Dateioperationen. Basierend auf den in Frage 1 generierten Dateien müssen Ereignisse anhand derselben Art von Ereignissen klassifiziert werden. Werfen wir einen Blick auf die spezifische
-Code-Implementierung
import os
# 创建一个列表用来存储新的内容
list = []
with open("task1.trainSentence.new", "r",encoding='xxx') as file_input: # 打开.new文件,xxx根据自己的编码格式填写
with open("exp1_1.txt", "w", encoding='xxx') as file_output: # 打开exp1_1.txt,xxx根据自己的编码格式填写文件如果没有就创建一个
for Line in file_input: # 遍历每一行的文件
arr = Line.split('\t') # 以\t为分隔符读取
if arr[0] not in list: # if the word is not in the list
list.append(arr[0]) # add the word to the list
file_output.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\n") # write the line to the file
file_input.close() #关闭.new文件
file_output.close() #关闭创建的txt文件3. Wir können die 19 Kategorien des Trainingssatzes entsprechend der Beziehung zwischen den Zeichen weiter klassifizieren, die Beziehung finden und einfügen Speichern Sie Inhalte mit derselben Beziehung in einem Ordner und erstellen Sie einen neuen, wenn dieser anders ist.
import os
file_1 = open("exp1_1.txt", encoding='xxx') # 打开文件,xxx根据自己的编码格式填写
os.mkdir("exp1_train") # 创建目录
os.chdir("exp1_train") # 修改进程的工作目录(使用该目录)
a = file.readline() # 按行读取exp1_1.txt文件
arr = a.split("\t") # 按\t间隔符作为分割
b = 1 #设置分组文件的序列
file_2 = open("{}.txt".format(b), "w", encoding="xxx") # 打开文件,xxx根据自己的编码格式填写
for line in file_1: # 按行读取文件
arr_1 = line.split("\t") # 按\t间隔符作为分割
if arr[0] != arr_1[0]: # 如果读取文件的第一列内容与存入新文件的第一列类型不同
file_2.close() # 关掉该文件
b += 1 # 文件序列加一
f_2 = open("{}.txt".format(b), "w", encoding="xxx") # 创建新文件,以另一种类型分类,xxx根据自己的编码格式填写
arr = line.split("\t") # 按\t间隔符作为分割
f_2.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"t"+arr[4]+"\t""\n") # 将相同类型的文件写入
f_1.close() # 关闭题目一创建的exp1_1.txt文件
f_2.close() # 关闭创建的最后一个类型的文件Zweck des Experiments
Machen Sie sich mit der grundlegenden Datenstruktur von Python sowie der Eingabe und Ausgabe von Dateien vertraut.
Experimentelle Daten
Der xx Tianchi-Wettbewerb in xxxx ist auch die Daten der x. Big Data Challenge chinesischer Universitäten. Die Daten umfassen zwei Tabellen, nämlich die Benutzerverhaltenstabelle mars_tianchi_user_actions.csv und die Songkünstlertabelle mars_tianchi_songs.csv. Im Rahmen des Wettbewerbs werden gesammelte Song-Künstlerdaten sowie Aufzeichnungen zum Benutzerverhalten dieser Künstler innerhalb von 6 Monaten (20150301-20150831) geöffnet. Die Teilnehmer müssen die Wiedergabedaten des Künstlers für die nächsten 2 Monate, also 60 Tage (20150901-20151030), vorhersagen.

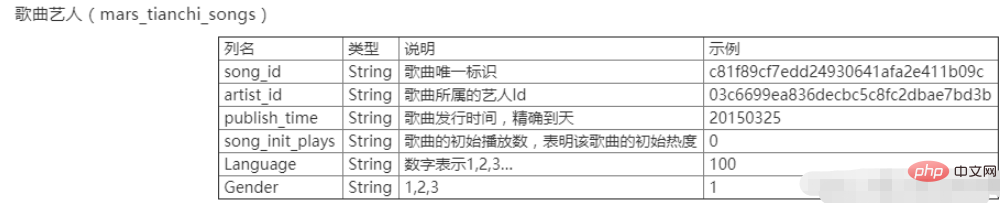

Experimenteller Inhalt
Verarbeiten Sie die Song-Künstlerdaten mars_tianchi_songs und zählen Sie die Anzahl der Künstler und die Anzahl der Songs für jeden Künstler. Das Ausgabedateiformat ist exp2_1.csv. Die erste Spalte ist die ID des Künstlers und die zweite Spalte ist die Anzahl der Songs des Künstlers. Die letzte Zeile gibt die Anzahl der Künstler aus.
Führen Sie die Benutzerverhaltenstabelle und die Song-Künstler-Tabelle in einer großen Tabelle zusammen und verwenden Sie dabei die Song-ID als Zuordnung. Die Namen jeder Spalte sind die erste bis fünfte Spalte, die mit den Spaltennamen der Benutzerverhaltenstabelle übereinstimmen, und die sechste bis zehnte Spalte sind die Spaltennamen der zweiten bis sechsten Spalte in der Song-Interpreten-Tabelle. Der Name der Ausgabedatei lautet exp2_2.csv.
Laut Künstlerstatistik ist die Wiedergabelautstärke aller Songs jedes Künstlers jeden Tag, die Ausgabedatei lautet exp2_3.csv, und jede Spalte ist mit der Künstler-ID, dem Datum Ds und der gesamten Songwiedergabelautstärke benannt. Hinweis: Hier wird nur die Anzahl der Songwiedergaben gezählt, nicht die Anzahl der Downloads und Sammlungen.
Ideen zur Problemlösung: (Verwendung der Pandas-Bibliothek)
1.
(1) Verwenden Sie .drop_duplicates(), um doppelte Werte zu löschen
(2) Verwenden Sie .loc[:,‘artist_id’] .value_counts() Finden Sie heraus, wie oft der Sänger wiederholt, d nicht wiederholt
import os
with open("exp1_1.txt", encoding='xxx') as file_in1: # 打开文件,xxx根据自己的编码格式填写
i = 1 # 类型序列
arr2 = {} # 创建字典
for line in file_in1: # 按行遍历
arr3 = line[0:2] # 读取关系
if arr3 not in arr2.keys():
arr2[arr3] = i
i += 1 # 类型+1
file_in = open("task1.test.new") # 打开文件task1.test.new
os.mkdir("exp1_test") # 创建目录
os.chdir("exp1_test") # 修改进程的工作目录(使用该目录)
for line in file_in:
arr = line[0:2]
with open("{}_test.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
file_out.write(line)
i = 1
file_in.seek(0)
os.mkdir("exp1_index")
os.chdir("exp1_index")
for line in file_in:
arr = line[0:2]
with open("index{}.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
line = line[0:-1]
file_out.write(line + '\t' + "{}".format(i) + "\n")
i += 1Verwenden Sie merge(), um die beiden Tabellen zusammenzuführen
import pandas as pd data = pd.read_csv(r"C:\mars_tianchi_songs.csv") # 读取数据 Newdata = data.drop_duplicates(subset=['artist_id']) # 删除重复值 artist_sum = Newdata['artist_id'].count() #artistChongFu_count = data.duplicated(subset=['artist_id']).count() artistChongFu_count = data.loc[:,'artist_id'].value_counts() 重复次数,即每个歌手的歌曲数目 songChongFu_count = data.loc[:,'songs_id'].value_counts() # 没有重复(歌手) artistChongFu_count.loc['artist_sum'] = artist_sum # 没有重复(歌曲)artistChongFu_count.to_csv('exp2_1.csv') # 输出文件格式为exp2_1.csv
Verwenden Sie groupby()[].sum() für wiederholte Addition
import pandas as pd import os data = pd.read_csv(r"C:\mars_tianchi_songs.csv") data_two = pd.read_csv(r"C:\mars_tianchi_user_actions.csv") num=pd.merge(data_two, data) num.to_csv('exp2_2.csv')
Das obige ist der detaillierte Inhalt vonWie manipulieren Sie Textdaten mit Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



