



Viele Content-Produktionsprojekte erfordern die Umwandlung einfacher Skizzen in realistische Bilder, was eine Bild-zu-Bild-Übersetzung beinhaltet, bei der tiefe generative Modelle verwendet werden, um bedingte Verteilungen natürlicher Bilder anhand einer Eingabe zu erlernen .
Das Grundkonzept der Bild-zu-Bild-Konvertierung besteht darin, vorab trainierte neuronale Netze zu nutzen, um natürliche Bildmannigfaltigkeiten zu erfassen. Die Bildtransformation ähnelt dem Durchqueren der Mannigfaltigkeit und dem Auffinden möglicher semantischer Eingabepunkte. Das System trainiert das synthetische Netzwerk vorab mithilfe vieler Bilder, um eine zuverlässige Ausgabe aller Stichproben seines latenten Raums zu liefern. Durch das vorab trainierte synthetische Netzwerk passt das nachgelagerte Training die Benutzereingaben an die latente Darstellung des Modells an.
Im Laufe der Jahre haben wir gesehen, dass viele aufgabenspezifische Methoden das SOTA-Niveau erreichen, aber aktuelle Lösungen haben immer noch Schwierigkeiten, hochauflösende Bilder für den realen Einsatz zu erstellen.

In einem aktuellen Artikel glauben Forscher der Hong Kong University of Science and Technology und Microsoft Research Asia, dass für die Bild-zu-Bild-Konvertierung vorab Training Es ist alles, was Sie brauchen. Bisherige Methoden erfordern einen speziellen Architekturentwurf und das Training eines einzelnen Transformationsmodells von Grund auf, was es schwierig macht, komplexe Szenen mit hoher Qualität zu generieren, insbesondere wenn gepaarte Trainingsdaten nicht ausreichen.
Daher behandeln die Forscher jedes Bild-zu-Bild-Übersetzungsproblem als nachgelagerte Aufgabe und führen ein einfaches allgemeines Framework ein, das ein vorab trainiertes Diffusionsmodell verwendet, um sich an verschiedene Bild-zu-Bild-Übersetzungen anzupassen. Konvertieren. Sie nannten das vorgeschlagene vorab trainierte Bild-zu-Bild-Übersetzungsmodell PITI (vortrainingsbasierte Bild-zu-Bild-Übersetzung). Darüber hinaus schlugen die Forscher auch vor, kontradiktorisches Training zu verwenden, um die Textursynthese im Diffusionsmodelltraining zu verbessern, und es mit normalisierter geführter Probenahme zu kombinieren, um die Generierungsqualität zu verbessern.
Abschließend führten die Forscher umfangreiche empirische Vergleiche zu verschiedenen Aufgaben mit anspruchsvollen Benchmarks wie ADE20K, COCO-Stuff und DIODE durch und zeigten, dass PITI-synthetisierte Bilder einen beispiellosen Realismus und eine beispiellose Wiedergabetreue aufweisen.

Der Autor hat kein spezifisches GAN verwendet, das leistungsstärkste GAN auf diesem Gebiet, sondern verwendet stattdessen ein Diffusionsmodell, um eine Vielzahl von Bildern zu synthetisieren. Zweitens sollte es Bilder aus zwei Arten latenter Codes generieren: einem, der die visuelle Semantik beschreibt, und einem anderen, der sich an Bildschwankungen anpasst. Semantische, niedrigdimensionale latente Daten sind für nachgelagerte Aufgaben von entscheidender Bedeutung. Andernfalls wäre es unmöglich, den modalen Input in einen komplexen latenten Raum umzuwandeln. Vor diesem Hintergrund verwendeten sie GLIDE, ein datengesteuertes Modell, das verschiedene Bilder generieren kann, als vorab trainierten generativen Prior. Da GLIDE latenten Text verwendet, ermöglicht es einen semantischen latenten Raum.
Diffusions- und Score-basierte Methoden demonstrieren die Generierungsqualität über Benchmarks hinweg. Im klassenbedingten ImageNet konkurrieren diese Modelle hinsichtlich der visuellen Qualität und der Stichprobenvielfalt mit GAN-basierten Methoden. Kürzlich haben Diffusionsmodelle, die mit großen Text-Bild-Paarungen trainiert wurden, überraschende Fähigkeiten gezeigt. Ein gut trainiertes Diffusionsmodell kann eine allgemeine generative Vorstufe für die Synthese liefern.
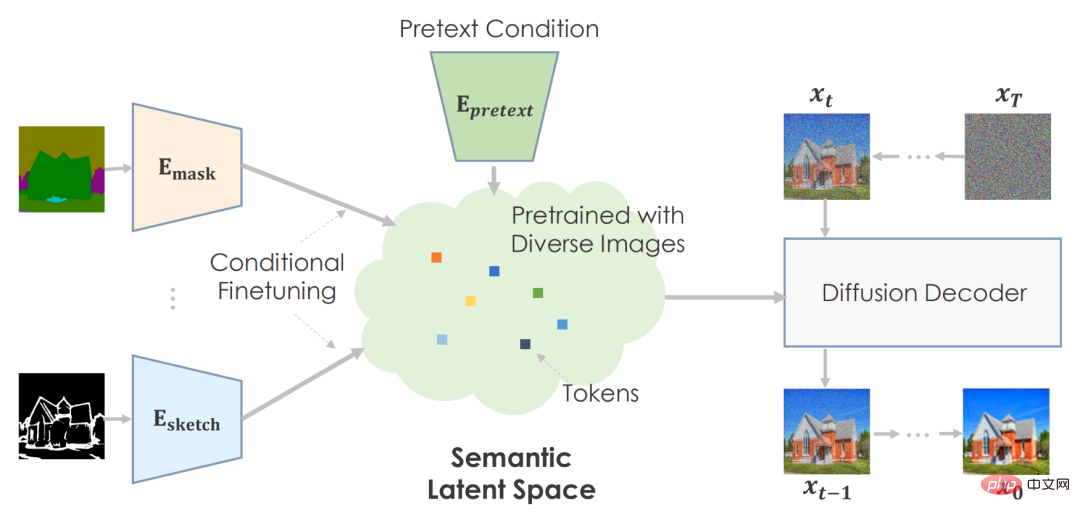
Der Autor kann die Vorwandaufgabe verwenden, um eine große Datenmenge vorab zu trainieren und eine sehr effektive zu entwickeln Aussagekräftige latente Räume zur Vorhersage von Bildstatistiken.
Für nachgelagerte Aufgaben optimieren sie den semantischen Raum bedingt, um aufgabenspezifische Umgebungen abzubilden. Die Maschine erstellt glaubwürdige Bilder basierend auf vorab trainierten Informationen.
Der Autor empfiehlt, semantische Eingaben zu verwenden, um das Diffusionsmodell vorab zu trainieren. Sie verwenden textkonditioniertes, bildtrainiertes GLIDE-Modell. Das Transformer-Netzwerk codiert Texteingaben und gibt Token für das Diffusionsmodell aus. Wie geplant ist es sinnvoll, den Text in den Raum einzubetten.

Das Bild oben ist das Werk des Autors. Vorab trainierte Modelle verbessern die Bildqualität und -vielfalt im Vergleich zu völlig neuen Techniken. Da der COCO-Datensatz über zahlreiche Kategorien und Kombinationen verfügt, kann der grundlegende Ansatz keine schönen Ergebnisse mit einer überzeugenden Architektur liefern. Ihre Methode kann für schwierige Szenen reichhaltige Details mit präziser Semantik erzeugen. Bilder veranschaulichen die Vielseitigkeit ihres Ansatzes.
Tabelle 1 zeigt, dass die Leistung der in dieser Studie vorgeschlagenen Methode immer besser ist als die anderer Modelle. Im Vergleich zum führenden OASIS erzielt PITI erhebliche Verbesserungen im FID bei der Maske-zu-Bild-Synthese. Darüber hinaus zeigt die Methode auch eine gute Leistung bei Skizze-zu-Bild- und Geometrie-zu-Bild-Syntheseaufgaben.
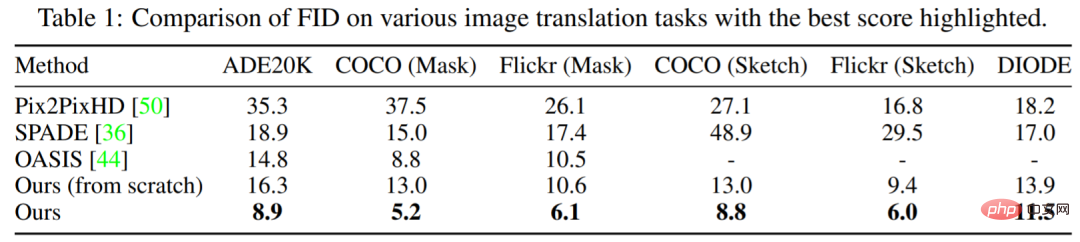
Abbildung 3 zeigt die Visualisierungsergebnisse dieser Studie zu verschiedenen Aufgaben. Experimente zeigen, dass das vorab trainierte Modell im Vergleich zur Trainingsmethode von Grund auf die Qualität und Vielfalt der generierten Bilder deutlich verbessert. Die in dieser Studie verwendeten Methoden können selbst bei anspruchsvollen Generierungsaufgaben lebendige Details und korrekte Semantik erzeugen.

Diese Studie führte auch eine Benutzerstudie zur Masken-zu-Bild-Synthese bei COCO-Stuff auf Amazon Mechanical Turk mit 3000 Stimmen von 20 Teilnehmern durch. Den Teilnehmern wurden jeweils zwei Bilder vorgelegt und sie wurden gebeten, darüber abzustimmen, welches realistischer war. Wie in Tabelle 2 gezeigt, übertrifft die vorgeschlagene Methode das Modell von Grund auf und andere Basislinien bei weitem.

Die bedingte Bildsynthese erstellt hochwertige Bilder, die den Bedingungen entsprechen. Die Bereiche Computer Vision und Grafik nutzen es, um Informationen zu erstellen und zu manipulieren. Umfangreiches Vortraining verbessert die Bildklassifizierung, Objekterkennung und semantische Segmentierung. Unbekannt ist, ob eine groß angelegte Vorschulung für allgemeine Erzeugungsaufgaben von Vorteil ist.
Energieverbrauch und CO2-Emissionen sind zentrale Themen beim Image-Pre-Training. Das Vortraining ist energieintensiv, aber nur einmal erforderlich. Durch die bedingte Feinabstimmung können nachgelagerte Aufgaben dasselbe vorab trainierte Modell verwenden. Durch das Vortraining können generative Modelle mit weniger Trainingsdaten trainiert werden, wodurch die Bildsynthese verbessert wird, wenn die Daten aufgrund von Datenschutzproblemen oder hohen Annotationskosten begrenzt sind.
Das obige ist der detaillierte Inhalt vonHKUST & MSRA Research: Was die Bild-zu-Bild-Konvertierung betrifft, ist die Feinabstimmung alles, was Sie brauchen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
 IP ändern
IP ändern
 So beheben Sie die Zeitüberschreitung des Vorgangs
So beheben Sie die Zeitüberschreitung des Vorgangs
 Hongmeng-System
Hongmeng-System
 Welche Sprache wird im Allgemeinen zum Schreiben von vscode verwendet?
Welche Sprache wird im Allgemeinen zum Schreiben von vscode verwendet?
 Von welcher Marke ist das Nubia-Handy?
Von welcher Marke ist das Nubia-Handy?
 So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
 msvcp140.dll
msvcp140.dll








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



