


Mit der Popularität des Konzepts der digitalen Menschen und der kontinuierlichen Weiterentwicklung der Generationstechnologie ist es kein Problem mehr, die Charaktere auf dem Foto entsprechend der Audioeingabe zu bewegen.
Allerdings gibt es immer noch viele Probleme beim „Generieren von Avatar-Videos für sprechende Charaktere anhand von Gesichtsbildern und einem Stück Sprachaudio“, wie z. B. Die Kopfbewegung ist nicht korrekt. Probleme wie Natürlichkeit, verzerrte Gesichtsausdrücke und übermäßige Gesichtsunterschiede zwischen den Charakteren in Videos und Bildern .
Kürzlich haben Forscher der Xi'an Jiaotong-Universität und andere das SadTalker-Modell vorgeschlagen, das auf einem dreidimensionalen Sportfeld lernt Generieren Sie 3DMM aus Audio-3D-Bewegungskoeffizienten (Kopfhaltung, Ausdruck) und verwenden Sie einen neuen 3D-Gesichtsrenderer, um Kopfbewegungen zu generieren.

Papierlink: https://arxiv.org /pdf/2211.12194.pdf
Projekthomepage: https://sadtalker.github.io/#🎜🎜 #
Der Ton kann Englisch, Chinesisch, Lied sein, und die Zeichen im Video können auch Blinkfrequenz steuern !
Um realistische Bewegungskoeffizienten zu lernen, haben die Forscher den Zusammenhang zwischen Audio und verschiedenen Arten von Bewegungskoeffizienten explizit separat modelliert: Durch Destillationskoeffizienten und 3D-gerenderte Gesichter lernen Sie genaue Gesichtsausdrücke von Audio; Design PoseVAE bis hin zu bedingtem VAE, um verschiedene Arten von Kopfbewegungen zu synthetisieren.
Schließlich werden die generierten dreidimensionalen Bewegungskoeffizienten dem unbeaufsichtigten dreidimensionalen Schlüsselpunktraum des Gesichtsrenderings zugeordnet und das endgültige Video synthetisiert.
Abschließend wurde in Experimenten gezeigt, dass diese Methode hinsichtlich Bewegungssynchronisation und Videoqualität Spitzenleistungen erzielt.
Das Plug-in für Stable-Diffusion-Webui wurde ebenfalls veröffentlicht!
Foto+Audio=VideoViele Bereiche wie digitale menschliche Schöpfung und Videokonferenzen müssen Sprachaudio verwenden, um statische Fotos zu animieren , aber derzeit ist dies immer noch eine sehr anspruchsvolle Aufgabe.
Frühere Arbeiten konzentrierten sich hauptsächlich auf die Erzeugung von „Lippenbewegungen“, da die Beziehung zwischen Lippenbewegungen und Sprache am stärksten ist, und andere Arbeiten versuchen auch, andere verwandte Videos zu generieren von Gesichtern in Bewegung (z. B. Kopfhaltungen), obwohl die Qualität der resultierenden Videos immer noch sehr unnatürlich ist und durch bevorzugte Posen, Unschärfe, Identitätsveränderung und Gesichtsverzerrung eingeschränkt wird.
Eine weitere beliebte Methode ist die latentbasierte Gesichtsanimation, die sich hauptsächlich auf bestimmte Bewegungskategorien in konversationsorientierten Gesichtsanimationen konzentriert, da es auch schwierig ist, qualitativ hochwertige Videos zu synthetisieren Obwohl das 3D-Gesichtsmodell stark entkoppelte Darstellungen enthält, die zum unabhängigen Erlernen der Bewegungsbahnen verschiedener Positionen im Gesicht verwendet werden können, werden dennoch ungenaue Ausdrücke und unnatürliche Bewegungsabläufe erzeugt.
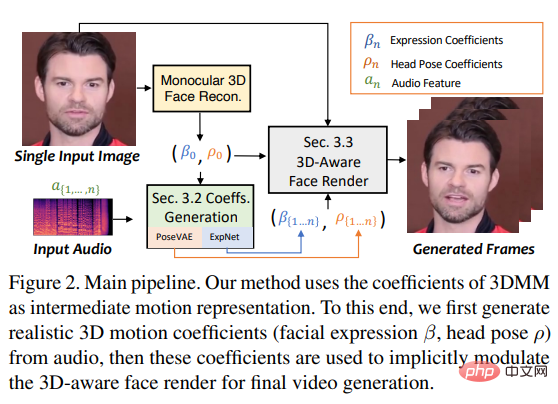
Basierend auf den oben genannten Beobachtungen schlugen die Forscher SadTalker (Stylized Audio-Driven Talking-head) vor, eine stilisierte audiogesteuerte Videoerzeugung durch ein implizites dreidimensionales Koeffizientenmodulationssystem. Um dieses Ziel zu erreichen, betrachteten die Forscher den Bewegungskoeffizienten des 3DMM als Zwischendarstellung und unterteilten die Aufgabe in zwei Hauptteile (Ausdrücke und Gesten), mit dem Ziel, realistischere Bewegungskoeffizienten (wie Kopfhaltungen, Lippenbewegungen usw.) zu erzeugen Augenzwinkern) aus Audio und lernen Sie jede Bewegung einzeln, um Unsicherheit zu reduzieren.
Führt schließlich das Quellbild durch eine 3D-fähige Gesichtsdarstellung, die von face-vid2vid inspiriert wurde.
3D-Gesicht
Da reale Videos in einer dreidimensionalen Umgebung gedreht werden, sind dreidimensionale Informationen von entscheidender Bedeutung, um die Authentizität der generierten Videos zu verbessern. Bisherige Arbeiten berücksichtigten jedoch selten den dreidimensionalen Raum, da nur einer Es ist schwierig, die ursprüngliche 3D-Spärlichkeit eines flachen Bildes zu erhalten, und es ist schwierig, hochwertige Gesichtsrenderer zu entwerfen. Inspiriert durch neuere Einzelbildtiefen-3D-Rekonstruktionsmethoden nutzten die Forscher den Raum vorhergesagter dreidimensionaler Deformationsmodelle (3DMMs) als Zwischendarstellungen.
In 3DMM kann die dreidimensionale Gesichtsform S wie folgt entkoppelt werden:
#🎜🎜 #
wobei S die durchschnittliche Form des dreidimensionalen Gesichts ist, Uid und Uexp die regulären Formen der Identität und des Ausdrucks des LSFM-morphbaren Modells sind und die Koeffizienten α (80 Dimensionen) und β ( 64 Dimensionen) beschreiben die Identität bzw. den Ausdruck des Charakters. Um die Vielfalt der Körperhaltungen aufrechtzuerhalten, stellen die Koeffizienten r und t eine identitätsunabhängige Koeffizientengenerierung dar modelliert als {β, r, t}.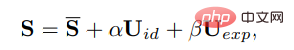
Das heißt, die Kopfhaltung ρ = [r, t] und der Ausdruckskoeffizient β werden separat vom gesteuerten Audio gelernt und dann implizit unter Verwendung dieser Bewegungskoeffizienten moduliert Für die endgültige Videokomposition wurde Gesichts-Rendering verwendet.
Bewegungssparsamkeit durch Audio erzeugen
Dreidimensionale Bewegungskoeffizienten Kopfhaltungen und -ausdrücke einschließen, wobei Kopfhaltungen globale Bewegungen sind, während Ausdrücke relativ lokal sind, so dass das vollständige Erlernen aller Koeffizienten eine große Unsicherheit für das Netzwerk mit sich bringt, da die Beziehung zwischen Kopfhaltungen und Audio relativ schwach ist und Lippenbewegungen stark ausgeprägt sind korreliert mit Audio.
So verwendet SadTalker die folgenden PoseVAE und ExpNet, um die Bewegung der Kopfhaltung bzw. des Ausdrucks zu erzeugen.
ExpNet
Lernen Sie eine Methode, die aus Audio generiert werden kann Ein universelles Modell des „genauen Ausdruckskoeffizienten“ ist aus zwei Gründen sehr schwierig:
1) Audio-to-Expression ist für verschiedene Zeichen nicht eins zu eins genau Mapping-Aufgabe;
2) Es gibt einige audiobezogene Aktionen im Ausdruckskoeffizienten, die sich auf die Genauigkeit der Vorhersage auswirken.
Das Designziel von ExpNet besteht darin, diese Unsicherheiten zu reduzieren; was das Problem der Charakteridentität betrifft, so haben die Forscher zunächst A Der Ausdruckskoeffizient des Rahmens verknüpft die Ausdrucksbewegung mit einer bestimmten Person.
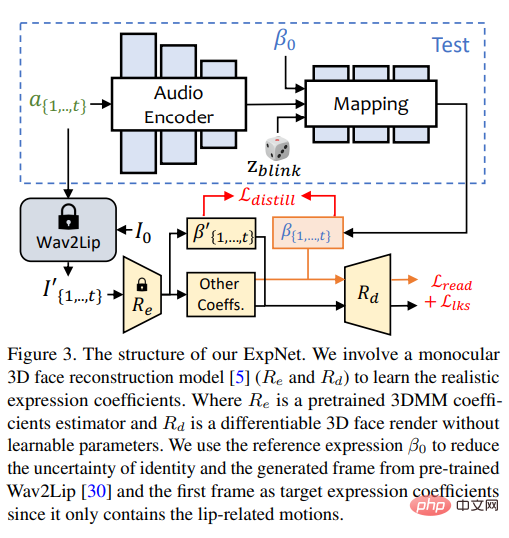
Um das Bewegungsgewicht anderer Gesichtskomponenten in natürlichen Gesprächen zu reduzieren, werden nur Lippenbewegungskoeffizienten (nur Lippenbewegung) als Koeffizientenziel verwendet.
Andere subtile Gesichtsbewegungen (z. B. Augenzwinkern) usw. können durch den zusätzlichen Verlust von Orientierungspunkten im gerenderten Bild verursacht werden.
PoseVAE Zum Erlernen realistischer, identitätsbewusster stilisierter Kopfbewegungen in sprechenden Videos.
Im Training wird ein Encoder-Decoder-basiertes Strukturpaar verwendet. Festes n Frames werden für das Pose-VAE-Training verwendet, bei dem sowohl der Encoder als auch der Decoder zweischichtige MLPs sind. Die Eingabe enthält eine kontinuierliche T-Frame-Kopfpose, die in eine Gaußsche Verteilung eingebettet ist, aus der das Netzwerk abgetastet wird Verteilung Lernen Sie, T-Frame-Posen zu generieren.
Es ist zu beachten, dass PoseVAE die Pose nicht direkt generiert, sondern den Rest der bedingten Pose des ersten Frames lernt, wodurch diese Methode auch die bedingte Pose unter der Bedingung des ersten Frames generieren kann Rahmen im Test. Längere, stabilere, kontinuierlichere Kopfbewegung.
Laut CVAE werden PoseVAE auch entsprechende Audiofunktionen und Stilkennungen als Bedingungen für Rhythmusbewusstsein und Identitätsstil hinzugefügt.
Das Modell verwendet die KL-Divergenz, um die Verteilung der erzeugten Bewegung zu messen; es verwendet den mittleren quadratischen Verlust und den gegnerischen Verlust, um die Qualität der Erzeugung sicherzustellen.
3D-fähige Gesichtsdarstellung
bei der Generierung echter Drei- Nach den dimensionalen Bewegungskoeffizienten renderten die Forscher das endgültige Video mithilfe eines sorgfältig entwickelten 3D-Bildanimators.
Die kürzlich vorgeschlagene Bildanimationsmethode face-vid2vid kann implizit 3D-Informationen aus einem einzelnen Bild lernen, diese Methode erfordert jedoch ein echtes Video als aktionstreibendes Signal Das in diesem Artikel vorgeschlagene Rendering kann durch 3DMM-Koeffizienten gesteuert werden.
Forscher schlagen MappingNet vor, um die Beziehung zwischen expliziten 3DMM-Bewegungskoeffizienten (Kopfhaltung und Ausdruck) und impliziten unbeaufsichtigten 3D-Schlüsselpunkten zu lernen.
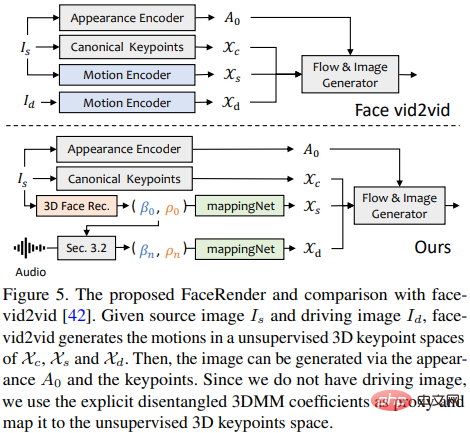
mappingNet besteht aus mehreren eindimensionalen Faltungsschichten und verwendet den Zeitkoeffizienten des Zeitfensters zur Glättung Der Unterschied besteht wie bei der PIRenderer-Verarbeitung darin, dass die Forscher herausgefunden haben, dass die gesichtsausgerichteten Bewegungskoeffizienten in PIRenderer die Natürlichkeit der von audiogesteuerten Videos erzeugten Bewegungen stark beeinflussen, sodass MappingNet nur die Koeffizienten von Gesichtsausdrücken und Kopfhaltungen verwendet.
Die Trainingsphase besteht aus zwei Schritten: Befolgen Sie zunächst das Originalpapier und trainieren Sie face-vid2vid auf selbstüberwachte Weise. Anschließend wird der Appearance-Encoder, der kanonische Schlüsselpunktschätzer, eingefroren und Nach allen Parametern des Bildgenerators wird MappingNet zur Feinabstimmung auf die 3DMM-Koeffizienten des Ground-Truth-Videos in rekonstruierter Weise trainiert.
Verwendet L1-Verlust für überwachtes Training im Bereich unbeaufsichtigter Schlüsselpunkte und liefert das endgültig generierte Video gemäß seiner ursprünglichen Implementierung.
Um die Überlegenheit dieser Methode zu beweisen, wählten die Forscher Frechet Inception Distance (FID) und Cumulative Probability Blur Detection (CPBD)-Index zur Bewertung der Bildqualität, wobei FID hauptsächlich die Authentizität der generierten Frames und CPBD die Klarheit der generierten Frames bewertet.
Um den Grad der Identitätserhaltung zu bewerten, wird ArcFace verwendet, um die Identitätseinbettung des Bildes zu extrahieren und anschließend die Kosinusähnlichkeit der Identitätseinbettung (CSIM) zu berechnen zwischen dem Quellbild und dem generierten Frame.
Um die Lippensynchronisation und die Mundform zu bewerten, bewerteten die Forscher den Wahrnehmungsunterschied der Mundform zu Wav2Lip, einschließlich Distanzwert (LSE-D) und Konfidenzwert (LSE- C).
Bei der Auswertung der Kopfbewegung wird die Diversität der generierten Kopfbewegungen anhand der Standardabweichung der von Hopenet aus den generierten Frames extrahierten Kopfbewegungsmerkmalseinbettungen berechnet. Berechnen Sie den Beat Align Score, um die Konsistenz von Audio und erzeugten Kopfbewegungen zu bewerten.
Unter den Vergleichsmethoden wurden mehrere fortschrittlichste Methoden zur Generierung sprechender Avatare ausgewählt, darunter MakeItTalk, Audio2Head und Methoden zur Audio-to-Expression-Generierung (Wav2Lip, PC-AVS). , bewertet anhand öffentlicher Prüfpunktgewichte.
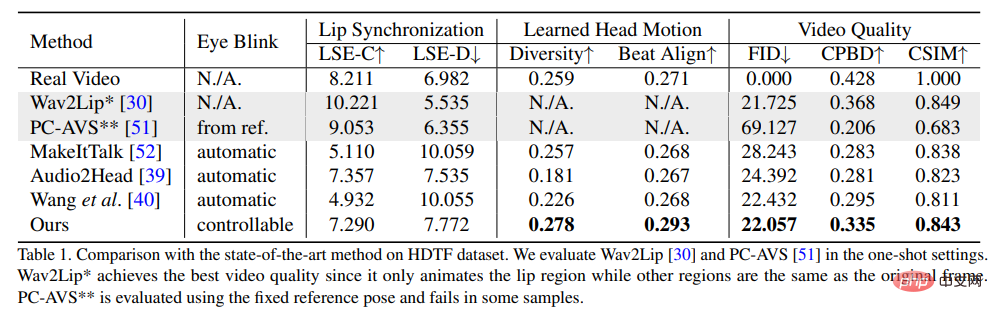
Aus den experimentellen Ergebnissen ist ersichtlich, dass die in der vorgeschlagene Methode Der Artikel kann zeigen, dass dies zu einer insgesamt besseren Videoqualität und einer besseren Kopfhaltungsvielfalt führt und gleichzeitig hinsichtlich der Lippensynchronisationsmetriken eine vergleichbare Leistung wie andere Methoden zur Generierung vollständig sprechender Köpfe zeigt.
Die Forscher glauben, dass diese Lippensynchronisationsmetriken so empfindlich auf Audio reagieren, dass unnatürliche Lippenbewegungen möglicherweise bessere Ergebnisse erzielen, aber der Artikel legt nahe, dass die Methode ähnliche Ergebnisse wie bei echten Videos erzielte , was auch die Vorteile dieser Methode zeigt.

Wie aus den visuellen Ergebnissen verschiedener Methoden hervorgeht, ist die visuelle Qualität dieser Methode sehr ähnlich zum ursprünglichen Zielvideo und ist auch den erwarteten unterschiedlichen Kopfhaltungen sehr ähnlich.
Im Vergleich zu anderen Methoden erzeugt Wav2Lip unscharfe Halbgesichter; PC-AVS und Audio2Head haben Schwierigkeiten, die Identität des Quellbildes beizubehalten; Gesicht; MakeItTalk und Audio2Head erzeugen aufgrund der 2D-Verzerrung verzerrte Gesichtsvideos.
Das obige ist der detaillierte Inhalt vonBilder + Audios verwandeln sich in Sekundenschnelle in Videos! Der Open-Source-SadTalker der Xi'an Jiaotong University: übernatürliche Kopf- und Lippenbewegungen, zweisprachig in Chinesisch und Englisch und kann auch singen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So fügen Sie Audio in ppt ein
So fügen Sie Audio in ppt ein
 So ändern Sie den Text im Bild
So ändern Sie den Text im Bild
 Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
 Java-basierte Methoden und Praktiken zur Audioverarbeitung
Java-basierte Methoden und Praktiken zur Audioverarbeitung
 So lassen Sie PPT-Bilder einzeln erscheinen
So lassen Sie PPT-Bilder einzeln erscheinen
 So erstellen Sie ein rundes Bild in ppt
So erstellen Sie ein rundes Bild in ppt
 So verwenden Sie debug.exe
So verwenden Sie debug.exe
 Keyword-Optimierungssoftware von Baidu
Keyword-Optimierungssoftware von Baidu








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



