


Moderne Computer verwenden Binär (Bit, Bit) als grundlegende Informationseinheit. 1 Byte entspricht beispielsweise 8 Bits, aber in Wirklichkeit besteht es aus 3 Bytes Computer Beim Speichern wird es im Binärformat dargestellt. Die entsprechenden ASCII-Codes von big sind jeweils 98, 105 und 103, und die entsprechenden Binärzahlen sind 01100010, 01101001 bzw. 01100111. big字符串是由 3 个字节组成,但实际在计算机存储时将其用二进制表示,big分别对应的 ASCII 码分别是 98、105、103,对应的二进制分别是 01100010、01101001 和 01100111。
许多开发语言都提供了操作位的功能,合理地使用位能够有效地提高内存使用率和开发效率。
Bit-map 的基本思想就是用一个 bit 位来标记某个元素对应的 value,而 key 即是该元素。由于采用了 bit 为单位来存储数据,因此在存储空间方面,可以大大节省。
在 Java 中,int 占 4 字节,1 字节 = 8位(1 byte = 8 bit),如果我们用这个 32 个 bit 位的每一位的值来表示一个数的话是不是就可以表示 32 个数字,也就是说 32 个数字只需要一个 int 所占的空间大小就可以了,那就可以缩小空间 32 倍。
1 Byte = 8 Bit,1 KB = 1024 Byte,1 MB = 1024 KB,1GB = 1024 MB
假设网站有 1 亿用户,每天独立访问的用户有 5 千万,如果每天用集合类型和 BitMap 分别存储活跃用户:
1.假如用户 id 是 int 型,4 字节,32 位,则集合类型占据的空间为 50 000 000 * 4/1024/1024 = 200M;
2.如果按位存储,5 千万个数就是 5 千万位,占据的空间为 50 000 000/8/1024/1024 = 6M。
那么如何用 BitMap 来表示一个数呢?
上面说了用 bit 位来标记某个元素对应的 value,而 key 即是该元素,我们可以把 BitMap 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1(0 表示这个数不存在,1 表示存在),数组的下标在 BitMap 中叫做偏移量。比如我们需要表示{1,3,5,7}这四个数,如下:
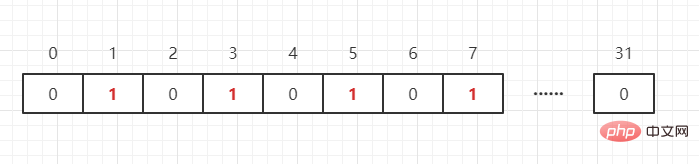
那如果还存在一个数 65 呢?只需要开int[N/32+1]个 int 数组就可以存储完这些数据(其中 N 表示这群数据中的最大值),即:
int[0]:可以表示 0~31
int[1]:可以表示 32~63
int[2]:可以表示 64~95
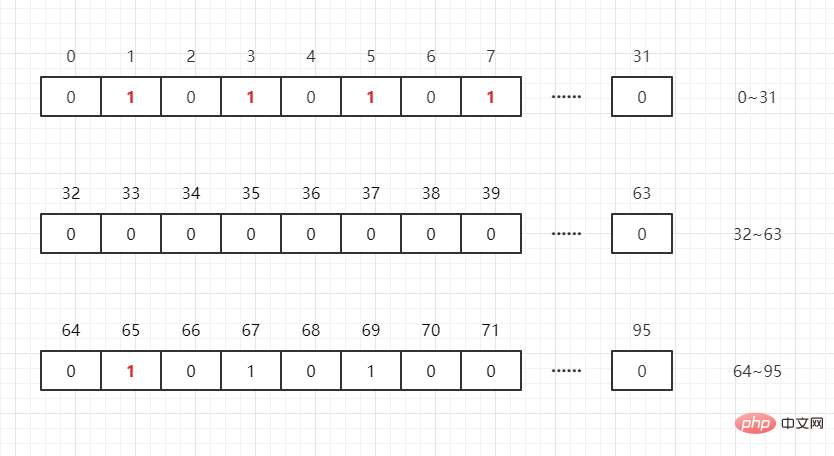
假设我们要判断任意整数是否在列表中,则 M/32 就得到下标,M%32就知道它在此下标的哪个位置,如:
65/32 = 2,65%32=1,即 65 在int[2]
1 Byte = 8 Bit, 1 KB = 1024 Byte, 1 MB = 1024 KB, 1 GB = 1024 MBGehen Sie davon aus, dass die Website täglich 100 Millionen Benutzer hat und 50 Millionen einzelne Benutzer sie besuchen . Wenn der Sammlungstyp und BitMap verwendet werden, um aktive Benutzer jeden Tag separat zu speichern: 1 Wenn die Benutzer-ID vom Typ int ist, 4 Bytes, 32 Bits, beträgt der vom Sammlungstyp belegte Speicherplatz 50.000.000 * 4/1024 /1024 = 200M; 2. Bei Speicherung in Bits sind 50 Millionen Bits und der belegte Speicherplatz beträgt 50.000.000/8/1024/1024 = 6M. Wie kann man also mit BitMap eine Zahl darstellen? Wie oben erwähnt, werden Bitbits verwendet, um den Wert zu markieren, der einem Element entspricht, und der Schlüssel ist das Element. Wir können uns BitMap als
Array
in Einheiten von Bits vorstellen. Jede Einheit des Arrays kann nur 0 und speichern 1 (0 bedeutet, dass die Zahl nicht existiert, 1 bedeutet, dass sie existiert), der Index des Arrays wird in BitMap als Offset bezeichnet. Beispielsweise müssen wir die vier Zahlen{1,3,5,7} wie folgt darstellen:
 Was ist, wenn noch die Zahl 65 vorhanden ist? Sie müssen nur
Was ist, wenn noch die Zahl 65 vorhanden ist? Sie müssen nur int[N/32+1] int-Arrays öffnen, um diese Daten zu speichern (wobei N den Maximalwert in dieser Datengruppe darstellt), das heißt:
int[ 0 ]: Kann 0~31 darstellenint[1]: Kann 32~63 darstellenint[2]: Kann 64~95 darstellen
Angenommen, wir wollen urteilen Unabhängig davon, ob sich eine Ganzzahl in der Liste befindet, erhält M/32 den Index und M%32 weiß, wo er sich im Index befindet, z. B.: 65/32 = 2, 65%32=1, d. h. 65 ist das erste Bit in int[2]. Bloom-Filter🎜🎜Im Wesentlichen handelt es sich beim Bloom-Filter um eine Datenstruktur, eine relativ clevere probabilistische Datenstruktur, die sich durch effizientes Einfügen und Abfragen auszeichnet und verwendet werden kann, um Ihnen mitzuteilen, dass „etwas nicht existieren darf oder existieren könnte“. 🎜🎜Im Vergleich zu herkömmlichen Datenstrukturen wie Liste, Menge, Karte usw. ist es effizienter und nimmt weniger Platz ein. Der Nachteil besteht jedoch darin, dass die zurückgegebenen Ergebnisse probabilistisch und nicht genau sind. 🎜🎜Tatsächlich werden Bloom-Filter häufig im 🎜Webseiten-Blacklist-System🎜, 🎜Spam-Filtersystem🎜, 🎜Crawler-URL-Gewichtsbestimmungssystem🎜 usw. verwendet. Googles berühmte verteilte Datenbank Bigtable verwendet Bloom-Filter für die Suche, um die Anzahl zu reduzieren Die IO-Festplatte sucht nach nicht vorhandenen Zeilen oder Spalten. Google Chrome verwendet Bloom-Filter, um sichere Browsing-Dienste zu beschleunigen. 🎜🎜 Bloom-Filter werden auch in vielen Schlüsselwertsystemen verwendet, um den Abfrageprozess zu beschleunigen, z. B. Hbase, Accumulo, Leveldb. Im Allgemeinen wird der Wert auf der Festplatte gespeichert, und der Zugriff auf die Festplatte nimmt viel Zeit in Anspruch. Mithilfe des Bloom-Filters kann der Prozessor schnell feststellen, ob der einem bestimmten Schlüssel entsprechende Wert vorhanden ist, sodass viele unnötige Festplatten-E/A-Vorgänge vermieden werden können. 🎜🎜Ordnen Sie ein Element über eine Hash-Funktion einem Punkt in einem Bit-Array (Bit-Array) zu. Auf diese Weise müssen wir nur sehen, ob der Punkt 1 ist, um zu wissen, ob er in der Menge enthalten ist. Dies ist die Grundidee des Bloom-Filters. 🎜🎜Anwendungsszenarien🎜🎜1. Derzeit gibt es 1 Milliarde natürliche Zahlen, die in Unordnung angeordnet sind und sortiert werden müssen. Die Einschränkungen werden auf 32-Bit-Maschinen implementiert und das Speicherlimit beträgt 2G. Wie wird es gemacht? 🎜🎜2. Wie kann man schnell herausfinden, ob die URL-Adresse auf der Blacklist steht? (Jede URL umfasst durchschnittlich 64 Byte)🎜🎜3. Müssen Sie das Anmeldeverhalten der Benutzer analysieren, um die Benutzeraktivität zu bestimmen? 🎜🎜4. Webcrawler – wie kann man feststellen, ob eine URL gecrawlt wurde? 🎜🎜5. Benutzerattribute schnell finden (Blacklist, Whitelist usw.)? 🎜🎜6. Daten werden auf der Festplatte gespeichert. Wie kann eine große Anzahl ungültiger E/A vermieden werden? 🎜🎜7. Bestimmen Sie, ob ein Element in Milliarden von Daten vorhanden ist? 🎜🎜8. Cache-Penetration. 🎜Im Allgemeinen ist es in Ordnung, die Webseiten-URL für die Suche in der Datenbank zu speichern oder eine Hash-Tabelle für die Suche zu erstellen.
Wenn die Datenmenge klein ist, ist es richtig, so zu denken: Sie können den Wert tatsächlich dem Schlüssel von HashMap zuordnen und dann das Ergebnis innerhalb einer Zeitkomplexität von O(1) zurückgeben ist äußerst effizient. Die Implementierung von HashMap weist jedoch auch Nachteile auf, z. B. einen hohen Anteil an Speicherkapazität. In Anbetracht der vorhandenen Auslastungsfaktoren kann der Speicherplatz beispielsweise nicht vollständig genutzt werden mehr als 16 Zeichen und sehr geringe Wiederholbarkeit), Wert=Ganzzahl, wie viel Platz wird es einnehmen? 1,2G.
Tatsächlich benötigen 10 Millionen int-Typen bei Verwendung von Bitmap nur 40 MB (10 000 000 * 4/1024/1024 = 40 MB), was 3 % entspricht. 10 Millionen Ganzzahlen erfordern 161 MB Die richtigen Leerzeichen machen 13,3 % aus.
Es ist ersichtlich, dass Sie sich die von HashMap belegte Speichergröße vorstellen können, sobald Ihre Werte viele sind, beispielsweise Hunderte von Millionen.
Aber wenn das gesamte Webseiten-Blacklist-System 10 Milliarden Webseiten-URLs enthält, ist die Suche in der Datenbank sehr zeitaufwändig, und wenn jeder URL-Speicherplatz 64 B groß ist, sind 640 GB Speicher erforderlich, was schwierig ist Ein allgemeiner Server erfüllt diese Anforderung.
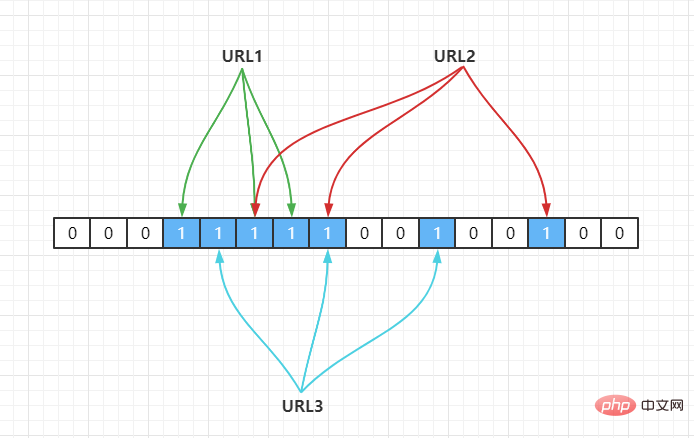
Angenommen, wir haben eine Menge A und es gibt n Elemente in A. Unter Verwendung von k Hash-Hash -Funktionen wird jedes Element in A auf verschiedene Positionen in einem Array B mit einer Länge von einem Bit abgebildet. Diese Positionen sind alle auf 1 gesetzt. Wenn das zu prüfende Element durch diese k Hash-Funktionen abgebildet wird und festgestellt wird, dass die Binärzahlen an seinen k Positionen alle 1 sind, gehört dieses Element wahrscheinlich zur Menge A. Andernfalls # 🎜🎜# darf nicht zu Set A gehören. Zum Beispiel haben wir 3 URLs {URL1,URL2,URL3} und ordnen sie über eine Hash-Funktion wie folgt einem Array der Länge 16 zu: #🎜🎜 #
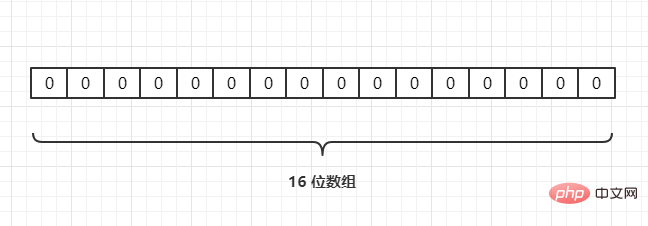 #🎜 🎜#
#🎜 🎜# Wenn die aktuelle Hash-Funktion Hash2() ist, wird sie dem Array durch eine Hash-Operation zugeordnet, vorausgesetzt Hash2(URL1) = 3, Hash2 (URL2) = 6, Hash2(URL3) = 6, wie folgt: {URL1,URL2,URL3},通过一个hash 函数把它们映射到一个长度为 16 的数组上,如下:
若当前哈希函数为 Hash2(),通过哈希运算映射到数组中,假设Hash2(URL1) = 3,Hash2(URL2) = 6,Hash2(URL3) = 6,如下:
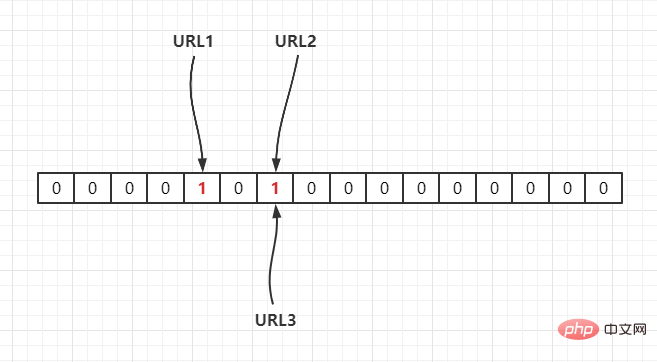
因此,如果我们需要判断URL1是否在这个集合中,则通过Hash(1)计算出其下标,并得到其值若为 1 则说明存在。
由于 Hash 存在哈希冲突,如上面URL2,URL3都定位到一个位置上,假设 Hash 函数是良好的,如果我们的数组长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素,显然空间利用率就变低了,也就是没法做到空间有效(space-efficient)。
解决方法也简单,就是使用多个 Hash 算法,如果它们有一个说元素不在集合中,那肯定就不在,如下:
Hash2(URL1) = 3,Hash3(URL1) = 5,Hash4(URL1) = 6 Hash2(URL2) = 5,Hash3(URL2) = 8,Hash4(URL2) = 14 Hash2(URL3) = 4,Hash3(URL3) = 7,Hash4(URL3) = 10
上面的做法同样存在问题,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断这个值存在。比如此时来一个不存在的 URL1000,经过哈希计算后,发现 bit 位为下:
Hash2(URL1000) = 7,Hash3(URL1000) = 8,Hash4(URL1000) = 14
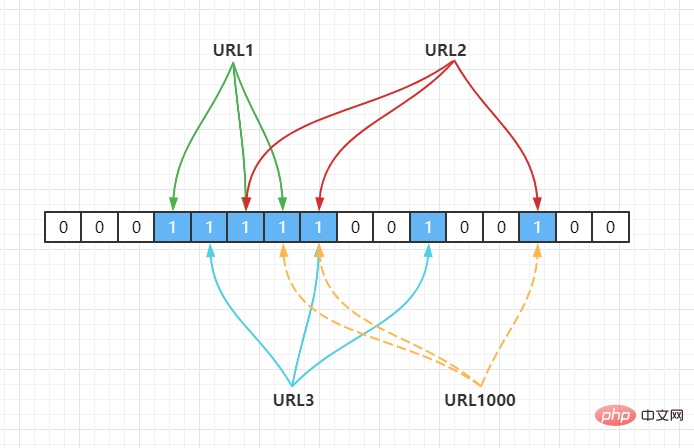
但是上面这些 bit 位已经被URL1,URL2,URL3置为 1 了,此时程序就会判断 URL1000

Wenn wir also feststellen müssen, ob URL1 Ob Es befindet sich in dieser Menge. Berechnen Sie seinen Index über Hash(1) und erhalten Sie seinen Wert. Wenn er 1 ist, bedeutet dies, dass er existiert.
URL2, URL3 alle an derselben Position, vorausgesetzt, die Hash-Funktion ist gut, wenn unsere Array-Länge beträgt m Punkte. Wenn wir die Konfliktrate beispielsweise auf 1% reduzieren möchten, kann diese Hash-Tabelle nur m/100-Elemente aufnehmen, was sich offensichtlich verringert die Raumnutzung, das heißt, es kann nicht platzsparend
public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
}# 🎜🎜#Fehleinschätzungsphänomen
URL1000 vorhanden ist, wird nach der Hash-Berechnung festgestellt, dass das Bit wie folgt lautet: 
URL1 ,URL2,URL3 ist auf 1 gesetzt und das Programm stellt fest, dass der Wert URL1000 vorhanden ist. Dies ist das Fehleinschätzungsphänomen des Bloom-Filters. Daher
Was der Bloom-Filter als existent ansieht, darf nicht existieren.Der Bloom-Filter kann einen Satz genau darstellen und genau bestimmen, ob sich ein bestimmtes Element in diesem Satz befindet. Die Genauigkeit wird durch das spezifische Design des Benutzers bestimmt. Der Vorteil des Bloom-Filters besteht jedoch darin, dass
auf sehr wenig Platz eine höhere Genauigkeit #🎜🎜# erreicht werden kann. #🎜🎜##🎜🎜#Die Implementierung von #🎜🎜##🎜🎜#Redis‘ Bitmap#🎜🎜##🎜🎜# basiert auf den zugehörigen Anweisungen der Redis‘ Bitmap-Datenstruktur. #🎜🎜##🎜🎜#RedisBloom#🎜🎜##🎜🎜# Bloom-Filter können mithilfe von Bitmap-Operationen in Redis implementiert werden, bis die Redis 4.0-Version Plug-In-Funktionen bereitstellt und der Bloom-Filter offiziell von Redis bereitgestellt wird Der Filter hat gerade Der Bloom-Filter wird offiziell als Plug-in auf den Redis-Server geladen. Die offizielle Website empfiehlt einen RedisBloom als Modul des Redis-Bloom-Filters. #🎜🎜##🎜🎜#Guavas BloomFilter#🎜🎜##🎜🎜#Als das Guava-Projekt Version 11.0 veröffentlichte, war eine der neu hinzugefügten Funktionen die BloomFilter-Klasse. #🎜🎜##🎜🎜#Redisson#🎜🎜##🎜🎜#Redisson implementiert einen Bloom-Filter basierend auf Bitmap. #🎜🎜#public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
}缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,如果从存储层查不到数据则不写入缓存层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。
因此我们可以用布隆过滤器来解决,在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。
例如:一个推荐系统有 4 亿个用户 id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户 id 不存在,那么就不会访问存储层,在一定程度保护了存储层。
注:布隆过滤器可能会误判,放过部分请求,当不影响整体,所以目前该方案是处理此类问题最佳方案
Das obige ist der detaillierte Inhalt vonSo implementieren Sie den Bloom-Filter in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



