


In den letzten Jahren wurden Diagramme häufig zur Darstellung und Verarbeitung komplexer Daten in vielen Bereichen verwendet, beispielsweise in der medizinischen Versorgung, im Transportwesen, in der Bioinformatik und in Empfehlungssystemen. Die Graph-Machine-Learning-Technologie ist ein leistungsstarkes Werkzeug zum Erhalten umfangreicher Informationen, die in komplexen Daten verborgen sind, und hat bei Aufgaben wie der Knotenklassifizierung und der Linkvorhersage eine starke Leistung gezeigt.
Obwohl die Technologie des maschinellen Lernens von Graphen erhebliche Fortschritte gemacht hat, erfordern die meisten von ihnen, dass Diagrammdaten zentral auf einem einzigen Computer gespeichert werden. Da jedoch der Schwerpunkt auf Datensicherheit und Benutzerschutz liegt, ist die zentrale Speicherung von Daten unsicher und undurchführbar geworden. Diagrammdaten sind oft über mehrere Datenquellen (Datensilos) verteilt und aus Datenschutz- und Sicherheitsgründen ist es nicht möglich, die erforderlichen Diagrammdaten von verschiedenen Orten zu sammeln.
Zum Beispiel möchte ein Drittunternehmen für einige Finanzinstitute Graph-Machine-Learning-Modelle trainieren, um ihnen dabei zu helfen, potenzielle Finanzkriminalität und betrügerische Kunden zu erkennen. Jedes Finanzinstitut verfügt über private Kundendaten, wie zum Beispiel demografische Daten und Transaktionsaufzeichnungen. Die Kunden jedes Finanzinstituts bilden ein Kundendiagramm, in dem Kanten Transaktionsdatensätze darstellen. Aufgrund strenger Datenschutzrichtlinien und des geschäftlichen Wettbewerbs können die privaten Kundendaten jeder Organisation nicht direkt an Drittunternehmen oder andere Organisationen weitergegeben werden. Gleichzeitig kann es auch Beziehungen zwischen Institutionen geben, die als Strukturinformationen zwischen Institutionen angesehen werden können. Die größte Herausforderung besteht daher darin, Graph-Machine-Learning-Modelle für die Aufdeckung von Finanzkriminalität auf der Grundlage von Privatkundengraphen und behördenübergreifenden Strukturinformationen zu trainieren, ohne direkten Zugriff auf die Privatkundendaten jeder Institution.
Federated Learning (FL) ist eine verteilte Lösung für maschinelles Lernen, die das Problem von Dateninseln durch kollaboratives Training löst. Es ermöglicht Teilnehmern (also Kunden), gemeinsam maschinelle Lernmodelle zu trainieren, ohne ihre privaten Daten weiterzugeben. Daher wird die Kombination von FL mit maschinellem Graphenlernen eine vielversprechende Lösung für die oben genannten Probleme.
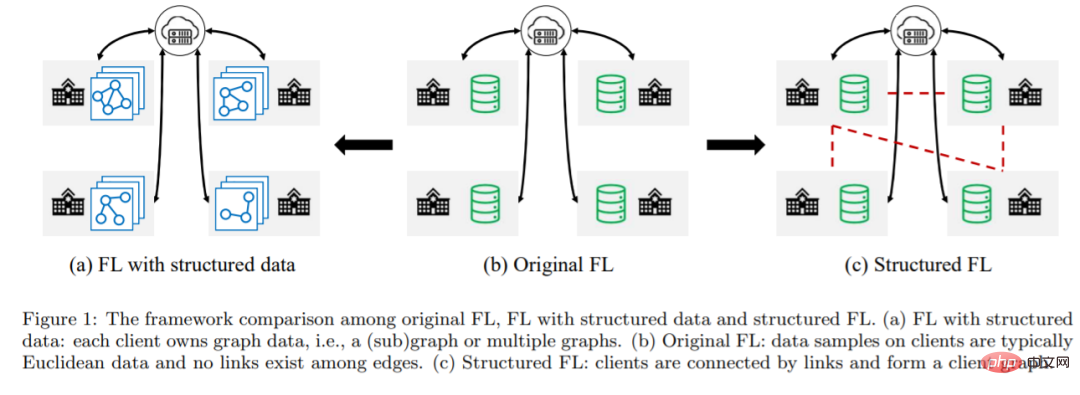
In diesem Artikel schlagen Forscher der University of Virginia Federated Graph Machine Learning (FGML) vor. Im Allgemeinen kann FGML basierend auf der Ebene der Strukturinformationen in zwei Einstellungen unterteilt werden: Die erste ist FL mit strukturierten Daten. In FL mit strukturierten Daten trainieren Kunden gemeinsam Diagramm-Machine-Learning-Modelle basierend auf ihren Diagrammdaten, während Diagrammdaten lokal gespeichert werden . Der zweite Typ ist strukturiertes FL. Bei strukturiertem FL gibt es strukturelle Informationen zwischen Clients, die ein Client-Diagramm bilden. Client-Graphen können genutzt werden, um effizientere gemeinsame Optimierungsmethoden zu entwerfen.

Papieradresse: https://arxiv.org /pdf/2207.11812.pdf
Während FGML eine vielversprechende Blaupause bietet, gibt es noch einige Herausforderungen:
#🎜🎜 #1. Mandantenübergreifende Informationen fehlen. In FL mit strukturierten Daten besteht ein häufiges Szenario darin, dass jeder Client-Computer über einen Untergraphen des globalen Diagramms verfügt und einige Knoten möglicherweise enge Nachbarn haben, die zu anderen Clients gehören. Aus Datenschutzgründen können Knoten nur Features ihrer unmittelbaren Nachbarn innerhalb des Clients aggregieren, aber nicht auf Features zugreifen, die sich auf anderen Clients befinden, was zu einer Unterrepräsentation von Knoten führt.
2. Datenschutzverlust der Diagrammstruktur. Im herkömmlichen FL ist es Kunden nicht gestattet, die Merkmale und Bezeichnungen ihrer Datenproben offenzulegen. In FL mit strukturierten Daten sollte auch der Datenschutz struktureller Informationen berücksichtigt werden. Strukturinformationen können direkt über eine gemeinsame Adjazenzmatrix oder indirekt über die Einbettung von Übertragungsknoten offengelegt werden.
3. Mandantenübergreifende Datenheterogenität. Im Gegensatz zu herkömmlichem FL, bei dem die Datenheterogenität von Nicht-IID-Datenstichproben herrührt, enthalten Diagrammdaten in FGML umfangreiche Strukturinformationen. Gleichzeitig wirkt sich auch die Diagrammstruktur verschiedener Kunden auf die Leistung des Diagrammmodells für maschinelles Lernen aus.
4. Strategie zur Verwendung von Parametern. In strukturierter FL ermöglicht der Client-Graph den Clients, Informationen von ihren benachbarten Clients zu erhalten. Bei strukturiertem FL müssen wirksame Strategien entwickelt werden, um Nachbarinformationen, die von einem zentralen Server koordiniert oder vollständig dezentralisiert werden, vollständig auszunutzen.
Um die oben genannten Herausforderungen zu bewältigen, haben Forscher eine Vielzahl von Algorithmen entwickelt. Verschiedene Algorithmen konzentrieren sich derzeit hauptsächlich auf Herausforderungen und Methoden in Standard-FL, wobei nur wenige Versuche unternommen werden, spezifische Probleme und Techniken in FGML anzugehen. Jemand hat einen Übersichtsartikel zur Klassifizierung von FGML veröffentlicht, die wichtigsten Techniken in FGML jedoch nicht zusammengefasst. Einige Übersichtsartikel decken nur eine begrenzte Anzahl relevanter Artikel in FL ab und stellen die aktuell vorhandene Technologie sehr kurz vor.
In dem heute vorgestellten Artikel stellt der Autor zunächst die Konzepte zweier Problemdesigns in FGML vor. Anschließend werden die neuesten technologischen Fortschritte unter jedem Shezhi besprochen und auch die praktischen Anwendungen von FGML vorgestellt. und fasst zugängliche Diagrammdatensätze und Plattformen zusammen, die für FGML-Anwendungen verfügbar sind. Abschließend nennt der Autor einige vielversprechende Forschungsrichtungen. Zu den Hauptbeiträgen des Artikels gehören:
Taxonomie der FGML-Technologie: Der Artikel gibt eine Taxonomie von FGML basierend auf verschiedenen Problemen und fasst die wichtigsten Herausforderungen in jedem Umfeld zusammen.
Umfassende Technologieübersicht: Der Artikel bietet einen umfassenden Überblick über die vorhandene Technologie in FGML. Im Vergleich zu anderen vorhandenen Übersichtsartikeln untersuchen die Autoren nicht nur ein breiteres Spektrum verwandter Arbeiten, sondern liefern auch eine detailliertere technische Analyse, anstatt nur die Schritte jeder Methode aufzulisten.
Praktische Anwendung: Der Artikel fasst erstmals die praktische Anwendung von FGML zusammen. Die Autoren ordnen sie nach Anwendungsbereichen und stellen verwandte Arbeiten in jedem Bereich vor.
Datensätze und Plattformen: Der Artikel stellt die vorhandenen Datensätze und Plattformen in FGML vor und ist für Ingenieure und Forscher, die Algorithmen entwickeln und Anwendungen in FGML bereitstellen möchten, sehr hilfreich.
Zukünftige Richtungen: Der Artikel weist nicht nur auf die Einschränkungen bestehender Methoden hin, sondern gibt auch die zukünftige Entwicklungsrichtung von FGML an.
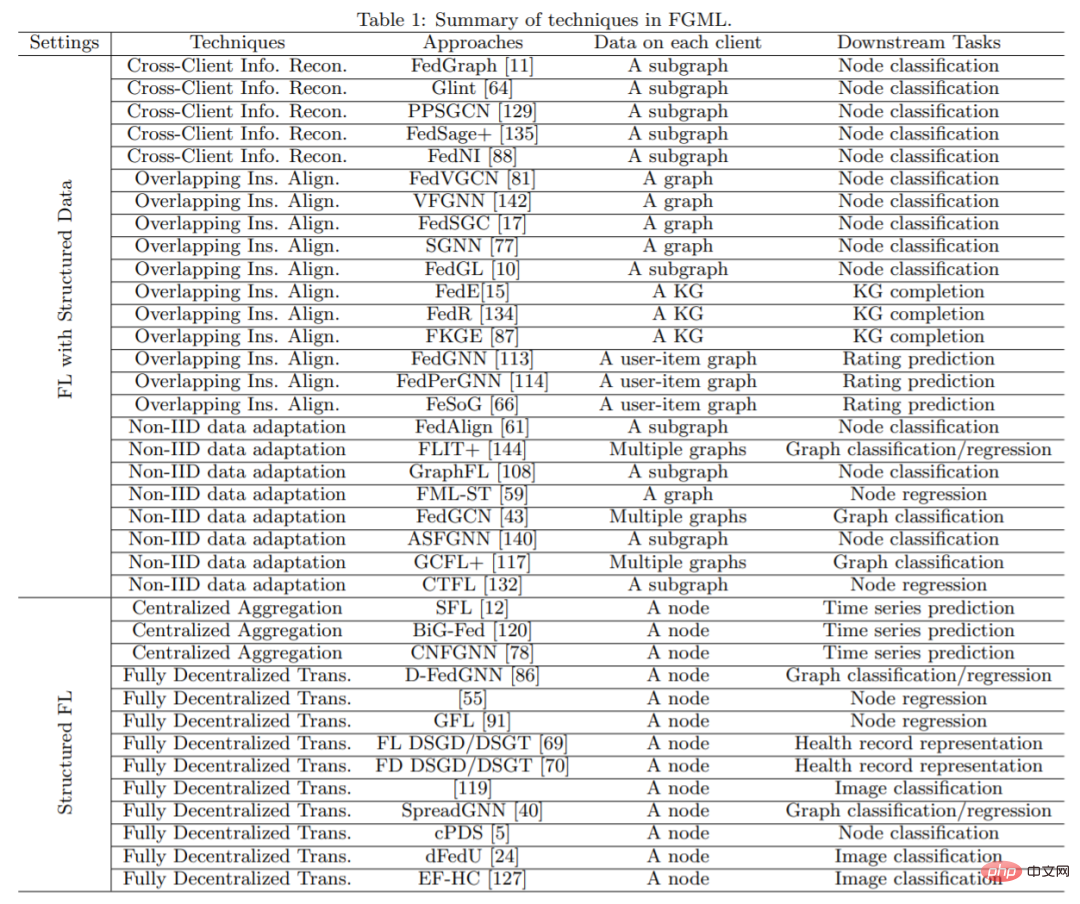
FGML-Technologieübersicht#🎜 🎜 # Hier ist eine Einführung in die Hauptstruktur des Artikels.
Abschnitt 2 stellt kurz Definitionen des maschinellen Lernens mit Graphen sowie Konzepte und Herausforderungen in beiden Umgebungen in FGML vor.
In den Abschnitten 3 und 4 werden die gängigen Technologien in beiden Umgebungen untersucht. Abschnitt 5 untersucht weiter reale Anwendungen von FGML. Abschnitt 6 stellt den Open Graph Dataset und zwei Plattformen für FGML vor, die in verwandten FGML-Artikeln verwendet werden. Mögliche zukünftige Richtungen finden Sie in Abschnitt 7.
Abschließend fasst Abschnitt 8 den vollständigen Text zusammen. Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonÜberblick über den aktuellen Stand der Federated-Learning-Technologie und ihrer Anwendungen in der Bildverarbeitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Tastenkombination zum schnellen Herunterfahren
Tastenkombination zum schnellen Herunterfahren
 Einführung in die Implementierungsmethoden für Java-Spezialeffekte
Einführung in die Implementierungsmethoden für Java-Spezialeffekte
 Ripple-Handelsplattform
Ripple-Handelsplattform
 So legen Sie ein Passwort in Windows fest
So legen Sie ein Passwort in Windows fest
 Warum fällt Localstorage so schnell aus?
Warum fällt Localstorage so schnell aus?
 Die Funktion des Net-User-Befehls
Die Funktion des Net-User-Befehls
 Laptop-Leistung
Laptop-Leistung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



