



Welche Bibliothek würden Sie für die Datenvisualisierung in Python verwenden?
Heute werde ich mit Ihnen ein leistungsstarkes Mitglied der Python-Datenvisualisierungsbibliothek Altair teilen!
Es ist sehr einfach, benutzerfreundlich und basiert auf der leistungsstarken Vega-Lite-JSON-Spezifikation. Wir benötigen nur kurzen Code, um schöne und effektive Visualisierungen zu generieren.
Mit Altair können wir mehr Energie und Zeit auf das Verständnis der Daten selbst und ihrer Bedeutung konzentrieren und werden vom komplexen Datenvisualisierungsprozess befreit.
Einfach ausgedrückt ist Altair eine visuelle Grammatik und eine deklarative Sprache zum Erstellen, Speichern und Teilen interaktiver visueller Designs. Sie kann das JSON-Format verwenden, um das visuelle Erscheinungsbild und den Interaktionsprozess zu beschreiben und netzwerkbasierte Bilder zu generieren.
Werfen wir einen Blick auf die mit Altair erstellten Visualisierungseffekte!
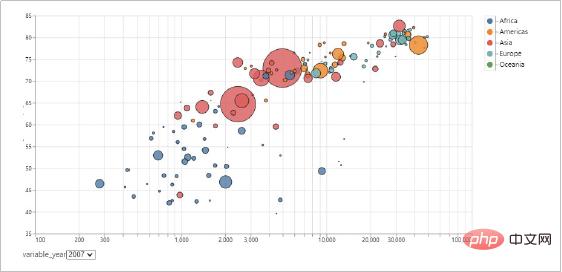 Vorteile von Altair
Vorteile von Altair
Im Allgemeinen umfassen die Eigenschaften von Altair die folgenden Aspekte.
Deklarative Python-API basierend auf grafischer Syntax.import altair as alt import pandas as pd data = pd.read_excel( "Index_Chart_Altair.xlsx", sheet_name="Sales", parse_dates=["Year"] ) alt.Chart( data )
Schnelltest – Erstellen Sie ein Balkendiagramm
Andererseits ist aus Sicht der statistischen Stichprobe die Variable die Grundgesamtheit und die Daten die Stichprobe. Zur Untersuchung und Analyse der Grundgesamtheit müssen Stichproben verwendet werden. Statistische Diagramme können erstellt werden, indem verschiedene Variablentypen miteinander kombiniert werden, um ein intuitiveres Verständnis der Daten zu ermöglichen.
Unterteilt nach der Kombination verschiedener Variablentypen kann die Kombination von Variablentypen in die folgenden Typen unterteilt werden.
Nominale Variable + quantitative Variable.Hier erklären wir eine der nominalen Variablen + quantitativen Variablen.
Wenn Sie quantitative Variablen der x-Achse zuordnen, nominale Variablen der y-Achse zuordnen und weiterhin Spalten als Kodierungsstil (Markierungsstil) der Daten verwenden, können Sie ein Balkendiagramm zeichnen. Balkendiagramme können Längenänderungen besser nutzen, um die Gewinnlücke aus Warenverkäufen zu vergleichen, wie in der Abbildung unten dargestellt.
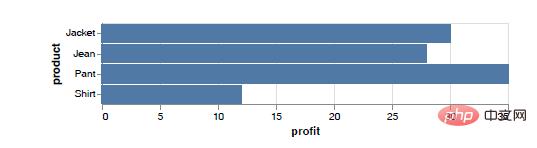 Verglichen mit dem Implementierungscode des Säulendiagramms sind die Änderungen im Implementierungscode des Balkendiagramms wie folgt.
Verglichen mit dem Implementierungscode des Säulendiagramms sind die Änderungen im Implementierungscode des Balkendiagramms wie folgt.
chart = alt.Chart(df).mark_bar().encode(x="profit:Q",y="product:N")
Komplexe Grafiken sind auch sehr einfach
我们可以使用面积图描述西雅图从2012 年到2015 年的每个月的平均降雨量统计情况。接下来,进一步拆分平均降雨量,以年份为分区标准,使用阶梯图将具体年份的每月平均降雨量分区展示,如下图所示。
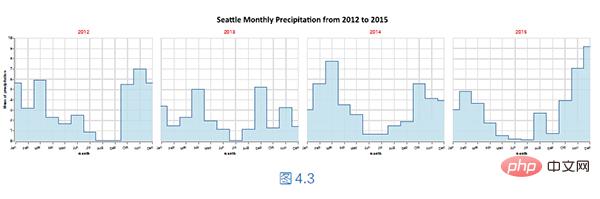
核心的实现代码如下所示。
…
chart = alt.Chart(df).mark_area(
color="lightblue",
interpolate="step",
line=True,
opacity=0.8
).encode(
alt.X("month(date):T",
axis=alt.Axis(format="%b",
formatType="time",
labelAngle=-15,
labelBaseline="top",
labelPadding=5,
title="month")),
y="mean(precipitation):Q",
facet=alt.Facet("year(date):Q",
columns=4,
header=alt.Header(
labelColor="red",
labelFontSize=15,
title="Seattle Monthly Precipitation from 2012 to 2015",
titleFont="Calibri",
titleFontSize=25,
titlePadding=15)
)
0)
…在类alt.X()中,使用month 提取时间型变量date 的月份,映射在位置通道x轴上,使用汇总函数mean()计算平均降雨量,使用折线作为编码数据的标记样式。
在实例方法encode()中,使用子区通道facet 设置分区,使用year 提取时间型变量date 的年份,作为拆分从2012 年到2015 年每个月的平均降雨量的分区标准,从而将每年的不同月份的平均降雨量分别显示在对应的子区上。使用关键字参数columns设置子区的列数,使用关键字参数header 设置子区序号和子区标题的相关文本内容。
具体而言,使用Header 架构包装器设置文本内容,也就是使用类alt.Header()的关键字参数完成文本内容的设置任务,关键字参数的含义如下所示。
Das obige ist der detaillierte Inhalt vonWelche sind die am häufigsten verwendeten Python-Datenvisualisierungsbibliotheken?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



