


Dieser Artikel wird mit Genehmigung von AI New Media Qubit (öffentliche Konto-ID: QbitAI) nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
Im Juni 2020 veröffentlichte OpenAI GPT-3 mit seinen Hunderten von Milliarden Parametern und seinen erstaunlichen Sprachverarbeitungsfunktionen. Da GPT-3 jedoch nicht für den Inlandsmarkt geöffnet ist, können wir nur zurückblicken und seufzen, wenn im Ausland eine Reihe kommerzieller Unternehmen gegründet werden, die Textgenerierungsdienste anbieten.
Im August dieses Jahres veröffentlichte das in London ansässige Open-Source-Unternehmen Stability AI das Vincent-Graphmodell Stable Diffusion und stellte die Gewichte und Open Source zur Verfügung Code des Modells kostenlos zur Verfügung zu stellen, was schnell das explosive Wachstum von KI-Malanwendungen auf der ganzen Welt auslöste.
Man kann sagen, dass Open Source in der zweiten Hälfte dieses Jahres eine direkte Katalysatorrolle beim AIGC-Boom gespielt hat.
Und wenn große Modelle zu einem Spiel werden, an dem jeder teilnehmen kann, profitiert nicht nur AIGC.
#🎜🎜 # Vor vier Jahren kam ein Sprachmodell namens BERT heraus, das die Spielregeln von KI-Modellen mit 300 Millionen Parametern veränderte.
Heute ist das Volumen der KI-Modelle auf Billionen angestiegen, aber auch das „Monopol“ großer Modelle hat immer mehr an Bedeutung gewonnen :
Große Unternehmen, große Rechenleistung, starke Algorithmen und große Modelle, zusammen bilden sie eine Barriere zwischen gewöhnlichen Entwicklern und kleinen und kleinen Mittelstand Eine Mauer, die für Unternehmen nur schwer zu durchbrechen ist.
Technische Barrieren sowie Schulung und Nutzung Große Modelle Die erforderlichen Rechenressourcen und Infrastruktur behindern unseren Weg von der „Verfeinerung“ großer Modelle zur „Nutzung“ großer Modelle. Daher ist Open Source dringend erforderlich. Viele große Modellentwickler sind sich einig, mehr Menschen die Teilnahme am Spiel großer Modelle durch Open Source zu ermöglichen und große Modelle von einer aufstrebenden KI-Technologie in eine robuste Infrastruktur umzuwandeln.
Unter diesem Konsens hat die Alibaba Damo Academy vor nicht allzu langer Zeit auf der Yunqi-Konferenz die chinesische Modell-Open-Source-Community ins Leben gerufen.“ ModelScope hat in der KI-Community große Aufmerksamkeit erregt. Derzeit haben einige inländische Institutionen damit begonnen, Modelle zur Community beizusteuern oder eigene Open-Source-Modellsysteme zu etablieren.
Derzeit ist der ausländische Großmodell-Open-Source-Ökobau dem inländischen voraus. Stability AI wurde als Privatunternehmen gegründet, verfügt aber über eigene Open-Source-Gene und verfügt über eine eigene riesige Entwicklergemeinschaft und ein stabiles Gewinnmodell, obwohl es Open Source ist.
BLOOM wurde im Juli dieses Jahres veröffentlicht, verfügt über 176 Milliarden Parameter und ist derzeit das größte Open-Source-Sprachmodell, das dahinter steht ist noch perfekter, es entspricht dem Open-Source-Geist und zeigt die Dynamik des Wettbewerbs mit Technologiegiganten von Kopf bis Fuß. BigScience ist eine offene Kooperationsorganisation unter der Leitung von Huggingface und keine offiziell gegründete Organisation. Die Geburt von BLOOM ist das Ergebnis von mehr als 1.000 Forschern aus mehr als 70 Ländern, die 117 Tage lang auf Supercomputern trainierten.
Darüber hinaus sind Technologieriesen nicht unbeteiligt an der Open Source großer Modelle. Im Mai dieses Jahres hat Meta das große Modell OPT mit 175 Milliarden Parametern offengelegt und nicht nur die Nutzung von OPT für nichtkommerzielle Zwecke ermöglicht, sondern auch seinen Code und 100 Seiten Protokolle veröffentlicht, die den Trainingsprozess aufzeichnen dass die Open Source sehr gründlich ist.
Das Forschungsteam wies in der Zusammenfassung des OPT-Artikels unverblümt darauf hin: „In Anbetracht der Rechenkosten, ohne große finanzielle Mittel, Diese Modelle sind schwer zu replizieren. Bei den wenigen Modellen, die über die API verfügbar sind, sind die vollständigen Modellgewichte nicht zugänglich, was ihre Untersuchung erschwert. Auch der vollständige Name des Modells „Open Pre-trained Transformers“ zeigt Metas Open-Source-Haltung. Man kann sagen, dass dies eine Anspielung auf das von OpenAI veröffentlichte GPT-3 ist, das nicht „offen“ ist (nur kostenpflichtige API-Dienste bereitstellt), und auf das im April dieses Jahres von Google eingeführte 540-Milliarden-Parameter-Großmodell PaLM (nicht Open Source). .
Unter den großen Unternehmen, die schon immer ein starkes Monopolgefühl hatten, ist Metas Open-Source-Schritt ein Hauch frischer Luft. Percy Liang, damaliger Direktor des Fundamental Model Research Center an der Stanford University, kommentierte: „Dies ist ein aufregender Schritt zur Erschließung neuer Möglichkeiten für die Forschung. Generell können wir davon ausgehen, dass eine größere Offenheit es Forschern ermöglichen wird, Probleme und tiefere Fragen zu lösen.“ . "
Percy Liangs Worte beantworten auch auf akademischer Ebene, warum große Modelle Open-Source-Frage sein müssen.
Die Entstehung origineller Errungenschaften erfordert Open Source als Grundlage.
Ein Forschungs- und Entwicklungsteam trainiert ein großes Modell. Wenn es bei der Veröffentlichung eines Artikels auf einer Top-Konferenz aufhört, erhalten andere Forscher nur die verschiedenen „Muskelshow“-Nummern im Artikel, ohne weitere Details zu sehen Modelltrainingstechnologien können nur mit Zeitaufwand reproduziert werden und sind möglicherweise nicht erfolgreich. Reproduzierbarkeit ist eine Garantie für die Zuverlässigkeit und Glaubwürdigkeit wissenschaftlicher Forschungsergebnisse. Mit offenen Modellen, Codes und Datensätzen können wissenschaftliche Forscher zeitnah mit den neuesten Forschungsergebnissen Schritt halten und auf den Schultern von Giganten stehen, die zum Greifen nah sind Ein Star. Früchte aus höheren Regionen können viel Zeit und Kosten sparen und technologische Innovationen beschleunigen.
Der Mangel an Originalität bei der Arbeit mit großen Modellen in China spiegelt sich hauptsächlich im blinden Streben nach Modellgröße wider, aber es gibt wenig Innovation in der zugrunde liegenden Architektur Dies ist ein häufiges Phänomen unter engagierten Branchenexperten im großen Modellforschungskonsens.
Assoziierter Professor Liu Zhiyuan vom Institut für Informatik der Tsinghua-Universität wies gegenüber AI Technology Review darauf hin: Es gibt einige relativ innovative Arbeiten zur Architektur großer Modelle in China, die jedoch im Wesentlichen auf Transformer There basieren In China mangelt es immer noch an Tools wie Transformer. Diese grundlegende Architektur sowie Modelle wie BERT und GPT-3 können zu großen Veränderungen in diesem Bereich führen.
Dr. Zhang Jiaxing, Chefwissenschaftler des IDEA Research Institute (Guangdong-Hong Kong-Macao Greater Bay Area Digital Economy Research Institute), sagte gegenüber AI Technology Review auch, dass von Dutzenden Milliarden über Hunderte von Milliarden bis hin zu Billionen Wir haben Durchbrüche in verschiedenen Systemen und in der Technik erzielt. Nachdem wir uns der Herausforderung gestellt haben, sollten wir über eine neue Modellstruktur nachdenken, anstatt das Modell einfach zu vergrößern.
Andererseits sind für den technischen Fortschritt großer Modelle eine Reihe von Modellbewertungsstandards erforderlich, und die Generierung von Standards erfordert Offenheit und Transparenz. In einigen neueren Untersuchungen wird versucht, verschiedene Bewertungsindikatoren für viele große Modelle vorzuschlagen, einige hervorragende Modelle werden jedoch aufgrund der Unzugänglichkeit ausgeschlossen. Beispielsweise verfügt das unter seiner Pathways-Architektur trainierte große Modell PaLM über hervorragende Sprachverständnisfähigkeiten Ein Witz, und das große Sprachmodell Chinchilla von DeepMind ist kein Open Source.
Aber ob es nun an den hervorragenden Fähigkeiten des Modells selbst oder am Status dieser großen Hersteller liegt, sie sollten bei solch fairen Wettbewerbsbedingungen nicht fehlen.
Eine bedauerliche Tatsache ist, dass eine aktuelle Studie von Percy Liang und seinen Kollegen gezeigt hat, dass es im Vergleich zu Nicht-Open-Source-Modellen bei vielen Kernszenarien gewisse Leistungslücken aktueller Open-Source-Modelle gibt. Große Open-Source-Modelle wie OPT-175B, BLOOM-176B und GLM-130B von der Tsinghua-Universität verloren in verschiedenen Aufgaben fast vollständig gegen nicht-Open-Source-große Modelle, darunter InstructGPT von OpenAI, TNLG-530B von Microsoft/NVIDIA usw. (wie gezeigt). unten).
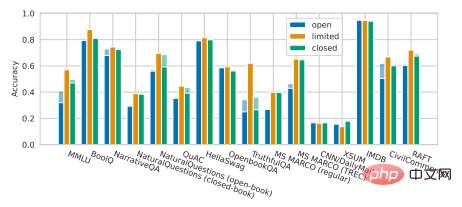
Illustration: Percy Liang et al. Ganzheitliche Bewertung von Sprachmodellen
Um diese peinliche Situation zu lösen, muss jede Führungskraft ihre eigenen hochwertigen großen Modelle, so ein großes, als Open Source bereitstellen Nur mit den allgemeinen Fortschritten im Modellierungsbereich können wir schneller zur nächsten Ebene gelangen.
Für die industrielle Umsetzung großer Modelle ist Open Source der einzige Weg.
Wenn wir die Veröffentlichung von GPT-3 als Ausgangspunkt nehmen, sind große Modelle nach mehr als zwei Jahren der gegenseitigen Verfolgung in Bezug auf Forschungs- und Entwicklungstechnologie ausgereifter geworden, aber Weltweit befindet sich die Entwicklung großer Modelle noch in einem frühen Stadium. Obwohl die von großen inländischen Herstellern entwickelten großen Modelle über interne Geschäftsimplementierungsszenarien verfügen, verfügen sie insgesamt noch nicht über ausgereifte Kommerzialisierungsmodelle.
Wenn die Implementierung groß angelegter Modelle an Fahrt gewinnt, kann eine gute Arbeit in Open Source den Grundstein für eine groß angelegte Implementierungsökologie in der Zukunft legen.
Die Natur großer Modelle bestimmt den Bedarf an Open Source für die Implementierung. Zhou Jingren, stellvertretender Direktor der Alibaba Damo Academy, sagte gegenüber AI Technology Review: „Große Modelle sind Abstraktionen und Verfeinerungen menschlicher Wissenssysteme, daher sind die Szenarien, auf die sie angewendet werden können, und der Wert, den sie generieren, enorm. Nur durch Open Source, groß.“ Das Anwendungspotenzial kann von vielen kreativen Entwicklern ausgeschöpft werden.
Das ist etwas, was das API-Modell, das die internen technischen Details des großen Modells abschließt, nicht leisten kann. Zuallererst ist dieses Modell für Modellbenutzer mit geringen Entwicklungskapazitäten geeignet. Für sie ist der Erfolg oder Misserfolg einer großen Modellimplementierung gleichbedeutend damit, dass sie vollständig in den Händen der Forschungs- und Entwicklungseinrichtung liegen.
Nehmen Sie als Beispiel OpenAI, den größten Gewinner, der kostenpflichtige API-Dienste für große Modelle bereitstellt. Laut OpenAI-Statistiken verwenden derzeit weltweit mehr als 300 Anwendungen die GPT-3-Technologie, aber diese Tatsache ist eine Voraussetzung auf OpenAI Die Forschungs- und Entwicklungsstärke ist stark genug, und GPT-3 ist auch leistungsstark genug. Wenn das Modell selbst eine schlechte Leistung erbringt, sind solche Entwickler hilflos.
Noch wichtiger ist, dass die Funktionen, die große Modelle über offene APIs bereitstellen können, begrenzt sind, was die Bewältigung komplexer und vielfältiger Anwendungsanforderungen erschwert. Derzeit gibt es nur wenige kreative Apps auf dem Markt, aber insgesamt befinden sie sich noch im „Spielzeug“-Stadium und sind weit davon entfernt, das Stadium der groß angelegten Industrialisierung zu erreichen.
„Der generierte Wert ist nicht so groß und die Kosten können nicht ausgeglichen werden, daher sind die Anwendungsszenarien, die auf der GPT-3-API basieren, sehr begrenzt. Viele Leute in der Branche erkennen diesen Ansatz tatsächlich nicht.“ sagte Jiaxing. Tatsächlich entscheiden sich ausländische Unternehmen wie copy.ai und Jasper für das Geschäft mit KI-gestütztem Schreiben. Der Benutzermarkt ist relativ groß, sodass sie einen relativ großen kommerziellen Wert generieren können, während mehr Anwendungen nur in kleinem Maßstab erfolgen.
Im Gegensatz dazu geht es bei Open Source darum, „Menschen das Fischen beizubringen“.
Im Open-Source-Modell verlassen sich Unternehmen auf den Open-Source-Code, um Schulungen und Sekundärentwicklungen durchzuführen, die ihren eigenen Geschäftsanforderungen auf dem vorhandenen Grundgerüst entsprechen. Dadurch können die Vielseitigkeitsvorteile großer Modelle voll ausgeschöpft werden und die Freigabe weitreichender Funktionen über das aktuelle Niveau hinaus wird schließlich zur tatsächlichen Implementierung großer Modelltechnologien in der Branche führen.
Als derzeit deutlich sichtbarer Weg zur Kommerzialisierung großer Modelle hat der Start von AIGC den Erfolg des Open-Source-Modells großer Modelle bestätigt Quelle großer Modelle Offenheit ist im In- und Ausland immer noch eine Minderheit. Lan Zhenzhong, Leiter des Deep Learning Laboratory der West Lake University, sagte einmal gegenüber AI Technology Review, dass es zwar viele Ergebnisse zu großen Modellen gebe, es aber nur sehr wenige offene Quellen und nur begrenzten Zugang für normale Forscher gebe, was sehr bedauerlich sei.
Beitrag, Beteiligung und Zusammenarbeit Mit diesen Schlüsselwörtern als Kern kann eine große Anzahl begeisterter Entwickler zusammengebracht werden, um gemeinsam ein potenziell transformatives großes Modellprojekt zu erstellen, sodass große Modelle schneller von Experiment zu Experiment übergehen können . Raum für die Industrie.
Über die Bedeutung von Open Source für große Modelle herrscht Konsens, doch auf dem Weg zu Open Source gibt es noch ein großes Hindernis: Rechenleistung.
Das ist auch die größte Herausforderung bei der aktuellen Umsetzung großer Modelle. Obwohl Meta über Open-Source-OPT verfügt, scheint es bisher keine großen Auswirkungen auf den Anwendungsmarkt gehabt zu haben. Letztlich sind die Kosten für die Rechenleistung für kleine Entwickler immer noch unerträglich, ganz zu schweigen von der Feinabstimmung großer Modelle , allein das Denken ist sehr schwierig.
Aus diesem Grund haben sich viele Forschungs- und Entwicklungseinrichtungen im Zuge der Überlegungen zur Parameteranpassung der Idee zugewandt, Leichtbaumodelle herzustellen und die Parameter des Modells zwischen Hunderten von Millionen und Milliarden zu steuern. Das von Lanzhou Technology eingeführte „Mencius“-Modell und die vom IDEA Research Institute als Open Source bereitgestellte Modellreihe „Fengshen Bang“ sind beide inländische Vertreter dieser Route. Sie teilen die verschiedenen Fähigkeiten sehr großer Modelle in Modelle mit relativ kleineren Parametern auf und haben bewiesen, dass sie in der Lage sind, bei einzelnen Aufgaben Hunderte Milliarden Modelle zu übertreffen.
Aber es besteht kein Zweifel, dass der Weg zu großen Modellen hier nicht enden wird. Viele Branchenexperten haben gegenüber AI Technology Review erklärt, dass es bei den Parametern großer Modelle noch Raum für Verbesserungen gibt und dass jemand weiter forschen muss mehr. Großformatiges Modell. Wir müssen uns also dem Dilemma großer Open-Source-Modelle stellen. Was sind also die Lösungen?
Betrachten wir es zunächst aus der Perspektive der Rechenleistung selbst. Der Aufbau großer Rechnercluster und Rechenzentren wird in Zukunft definitiv ein Trend sein, denn die Rechenressourcen am Ende können den Bedarf nicht decken. Aber jetzt hat sich das Mooresche Gesetz verlangsamt, und in der Branche mangelt es nicht an Argumenten dafür, dass das Mooresche Gesetz zu Ende geht Durst.
„Jetzt kann eine Karte (in Bezug auf die Argumentation) eine Milliarde Modelle ausführen. Gemäß der aktuellen Wachstumsrate der Rechenleistung, wenn eine Karte hundert Milliarden Modelle ausführen kann, wird die Rechenleistung dies tun.“ „Es kann zehn Jahre dauern, bis es besser wird“, erklärte Zhang Jiaxing.
Ich kann es kaum erwarten, bis das große Modell auf den Markt kommt.
Eine andere Richtung besteht darin, viel Aufhebens um Trainingstechnologie zu machen, um die Inferenzgeschwindigkeit großer Modelle zu beschleunigen, die Kosten für Rechenleistung zu senken und den Energieverbrauch zu senken, um die Benutzerfreundlichkeit großer Modelle zu verbessern.
Zum Beispiel erfordert Metas OPT (im Vergleich zu GPT-3) nur 16 NVIDIA v100-GPUs, um die komplette Modellcodebasis zu trainieren und bereitzustellen, was einem Siebtel von GPT-3 entspricht. Kürzlich haben die Tsinghua-Universität und Zhipu AI gemeinsam das zweisprachige große Modell GLM-130B durch schnelle Inferenzmethoden geöffnet und das Modell so weit komprimiert, dass es für eigenständige Inferenz auf einem A100 (40G*8) verwendet werden kann V100 (32G*8)-Server.
Natürlich macht es Sinn, hart in diese Richtung zu arbeiten. Der offensichtliche Grund, warum große Hersteller nicht bereit sind, große Modelle als Open Source anzubieten, sind die hohen Schulungskosten. Experten haben zuvor geschätzt, dass Zehntausende Nvidia v100-GPUs zum Trainieren von GPT-3 verwendet wurden, mit Gesamtkosten von bis zu 27,6 Millionen US-Dollar. Wenn eine Person ein PaLM trainieren möchte, wird es 9 bis 17 Millionen US-Dollar kosten. Wenn die Schulungskosten großer Modelle gesenkt werden können, steigt natürlich auch ihre Bereitschaft zur Open Source.
Aber letztlich kann dies aus technischer Sicht nur die Einschränkungen der Rechenressourcen lindern, ist aber nicht die ultimative Lösung. Obwohl viele große Modelle mit Hunderten von Milliarden und Billionen Ebenen begonnen haben, ihre Vorteile des „geringer Energieverbrauchs“ zu bewerben, ist die Rechenleistungsgrenze immer noch zu hoch.
Am Ende müssen wir noch zum großen Modell selbst zurückkehren, um einen Durchbruchspunkt zu finden. Eine sehr vielversprechende Richtung ist das spärliche dynamische Großmodell.
Spärliche große Modelle zeichnen sich durch eine sehr große Kapazität aus, es werden jedoch nur bestimmte Teile für eine bestimmte Aufgabe, Probe oder ein bestimmtes Etikett aktiviert. Mit anderen Worten: Diese spärliche dynamische Struktur kann es großen Modellen ermöglichen, die Parametermenge um einige Ebenen zu erhöhen, ohne dass große Rechenkosten aufgewandt werden müssen, wodurch zwei Fliegen mit einer Klappe geschlagen werden. Dies ist ein enormer Vorteil gegenüber dichten, großen Modellen wie GPT-3, die die Aktivierung des gesamten neuronalen Netzwerks erfordern, um selbst die einfachsten Aufgaben zu erledigen, was zu einer enormen Ressourcenverschwendung führt.
Google ist der Pionier für spärliche dynamische Strukturen. Sie haben MoE (Sparsely-Gated Mixture-of-Experts Layer) erstmals im Jahr 2017 vorgeschlagen und letztes Jahr auf den Markt gebracht Switch Transformers verfügt über eine Architektur im MoE-Stil und die Trainingseffizienz ist im Vergleich zu ihrem Vorgängermodell T5-Base Transformer mit hoher Dichte um das Siebenfache erhöht.
Die einheitliche Pathways-Architektur, auf der das diesjährige PaLM basiert, ist ein Modell mit spärlicher dynamischer Struktur: Das Modell kann das Netzwerk dynamisch lernen Anstatt das gesamte neuronale Netzwerk zu aktivieren, um eine Aufgabe zu erledigen, können wir nach Bedarf kleine Pfade durch das Netzwerk aufrufen, um zu bestimmen, für welche Aufgaben ein bestimmter Teil des neuronalen Netzwerks gut ist.

Hinweis: Pathways Architecture# 🎜 🎜#
Dies ähnelt im Wesentlichen der Funktionsweise des menschlichen Gehirns. Es gibt Dutzende Milliarden Neuronen im menschlichen Gehirn, aber nur Neuronen mit bestimmten Funktionen werden aktiviert, wenn sie bestimmte Aufgaben ausführen. Andernfalls wird der enorme Energieverbrauch unerträglich.
Groß, vielseitig und effizient – diese große Modellstrecke hat zweifellos eine große Anziehungskraft.
„In Zukunft, mit dem Segen von spärliche DynamikDer Rechenaufwand wird nicht so hoch sein, aber die Modellparameter werden definitiv immer größer. Die spärliche dynamische Struktur eröffnet möglicherweise eine neue Welt für große Modelle, und es wird kein Problem sein, auf Dutzende Billionen oder mehr zu gehen Hunderte von Milliarden.“ Zhang Jiaxing glaubt, dass eine spärliche Dynamik möglich sein wird. Struktur wird der ultimative Weg sein, den Widerspruch zwischen großer Modellgröße und Rechenleistungskosten zu lösen. Er fügte jedoch auch hinzu, dass es wenig Sinn mache, das Modell blind weiter zu vergrößern, wenn diese Art der Modellstruktur noch nicht beliebt sei.
Derzeit gibt es relativ wenige inländische Versuche in diese Richtung, und sie sind nicht so gründlich wie Google. Erforschung und Innovation in großen Modellstrukturen und Open Source fördern sich gegenseitig, und wir brauchen mehr Open Source, um Veränderungen in der Technologie großer Modelle anzuregen.
Was die Open Source großer Modelle behindert, ist nicht nur die geringe Verfügbarkeit, die durch die Rechenleistungskosten großer Modelle verursacht wird, sondern auch Sicherheitsprobleme.
Bezüglich des Risikos des Missbrauchs großer Modelle, insbesondere solcher, die nach Open Source generiert wurden, scheint es aus dem Ausland mehr Bedenken zu geben, und Es gibt auch Streitigkeiten. Dies ist für viele Institutionen zu einem Vorwand geworden, sich dafür zu entscheiden, große Modelle nicht als Open Source zu veröffentlichen, kann aber auch eine Ausrede für sie sein, Großzügigkeit zu verweigern.
OpenAI hat dafür viel Kritik auf sich gezogen. Als sie 2019 GPT-2 veröffentlichten, behaupteten sie, dass die Textgenerierungsfähigkeit des Modells zu leistungsfähig sei und ethischen Schaden anrichten könnte, was es für Open Source ungeeignet mache. Als GPT-3 ein Jahr später veröffentlicht wurde, gab es lediglich eine API-Testversion. Die aktuelle Open-Source-Version von GPT-3 wird tatsächlich von der Open-Source-Community selbst reproduziert.
Tatsächlich wirkt sich die Beschränkung des Zugriffs auf große Modelle nachteilig auf die Verbesserung der Robustheit großer Modelle und die Reduzierung von Verzerrungen und Toxizität aus. Als Joelle Pineau, die Leiterin von Meta AI, über die Entscheidung für Open Source OPT sprach, erklärte sie aufrichtig, dass ihr eigenes Team allein nicht alle Probleme lösen kann, wie etwa ethische Voreingenommenheit und bösartige Worte, die während des Textgenerierungsprozesses auftreten können. Sie glauben, dass große Modelle verantwortungsvoll öffentlich zugänglich gemacht werden können, wenn genügend Hausaufgaben gemacht werden. Es ist keine leichte Aufgabe, einen offenen Zugang und ausreichende Transparenz aufrechtzuerhalten und gleichzeitig das Risiko eines Missbrauchs zu verhindern. Als die Person, die die „Büchse der Pandora“ öffnete, genoss Stability AI einen guten Ruf, der durch proaktives Open Source hervorgerufen wurde, musste jedoch in letzter Zeit auch mit der Gegenreaktion konfrontiert werden, die Open Source mit sich brachte, was zu Kontroversen in Aspekten wie dem Urheberrechtseigentum führte.
Der alte dialektische Satz von „Freiheit und Sicherheit“ hinter Open Source gibt es schon seit langem, und vielleicht gibt es ihn nicht mehr Absolut richtige Antwort, aber da große Modelle implementiert werden, ist eine klare Tatsache: Wir haben nicht genug getan, um große Modelle als Open Source anzubieten.
Mehr als zwei Jahre sind vergangen, und wir haben bereits unser eigenes Großmodell auf Billionenebene im nächsten Transformationsprozess von „Tausende von Büchern lesen“ zu „Tausende von Meilen reisen“ eröffnet Quelle ist eine unvermeidliche Wahl.
Vor Kurzem steht GPT-4 kurz vor der Veröffentlichung und alle haben große Erwartungen an die sprunghaften Leistungssteigerungen, aber wir wissen nicht, wie viel Produktivität es für wie viele Menschen in der Zukunft freisetzen wird?
Das obige ist der detaillierte Inhalt vonDas Dilemma von Open Source für große KI-Modelle: Monopol, Mauern und das Leid der Rechenleistung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
 IP ändern
IP ändern
 So beheben Sie die Zeitüberschreitung des Vorgangs
So beheben Sie die Zeitüberschreitung des Vorgangs
 Hongmeng-System
Hongmeng-System
 Welche Sprache wird im Allgemeinen zum Schreiben von vscode verwendet?
Welche Sprache wird im Allgemeinen zum Schreiben von vscode verwendet?
 Von welcher Marke ist das Nubia-Handy?
Von welcher Marke ist das Nubia-Handy?
 So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
 msvcp140.dll
msvcp140.dll








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



