


Im Jahr 2021 haben Microsoft, OpenAI und Github gemeinsam ein nützliches Code-Vervollständigungs- und Vorschlagstool entwickelt – Copilot.
Es werden Codezeilen im Code-Editor des Entwicklers empfohlen, z. B. wenn Entwickler Code in integrierte Entwicklungsumgebungen wie Visual Studio Code, Neovim und JetBrains IDE eingeben kann die nächste Codezeile empfehlen. Darüber hinaus bietet Copilot sogar Beratung zu kompletten Methoden und komplexen Algorithmen sowie Unterstützung bei Template-Code und Unit-Tests.
Mehr als ein Jahr später ist dieses Tool für viele Programmierer zu einem untrennbaren „Programmierpartner“ geworden. Andrej Karpathy, ehemaliger Direktor für künstliche Intelligenz bei Tesla, sagte: „Copilot hat meine Programmiergeschwindigkeit erheblich beschleunigt, und es ist schwer vorstellbar, wie ich zur ‚manuellen Programmierung‘ zurückkehren kann. Derzeit lerne ich noch, wie man es verwendet, und.“ Es hat fast 80 % meiner Codes programmiert. Der Code hat eine Genauigkeit von fast 80 %. „
, wie sieht beispielsweise die Eingabeaufforderung von Copilot aus? Wie heißt das Modell? Wie wird die Empfehlungserfolgsrate gemessen? Werden Benutzercode-Schnipsel gesammelt und an den eigenen Server gesendet? Ist das Modell hinter Copilot ein großes oder ein kleines Modell?
Um diese Fragen zu beantworten, hat ein Forscher der University of Illinois in Urbana-Champaign Copilot grob nachentwickelt und über seine Beobachtungen gebloggt.
Andrej Karpathy hat diesen Blog in seinem Tweet empfohlen.
Das Folgende ist der Originaltext des Blogs.
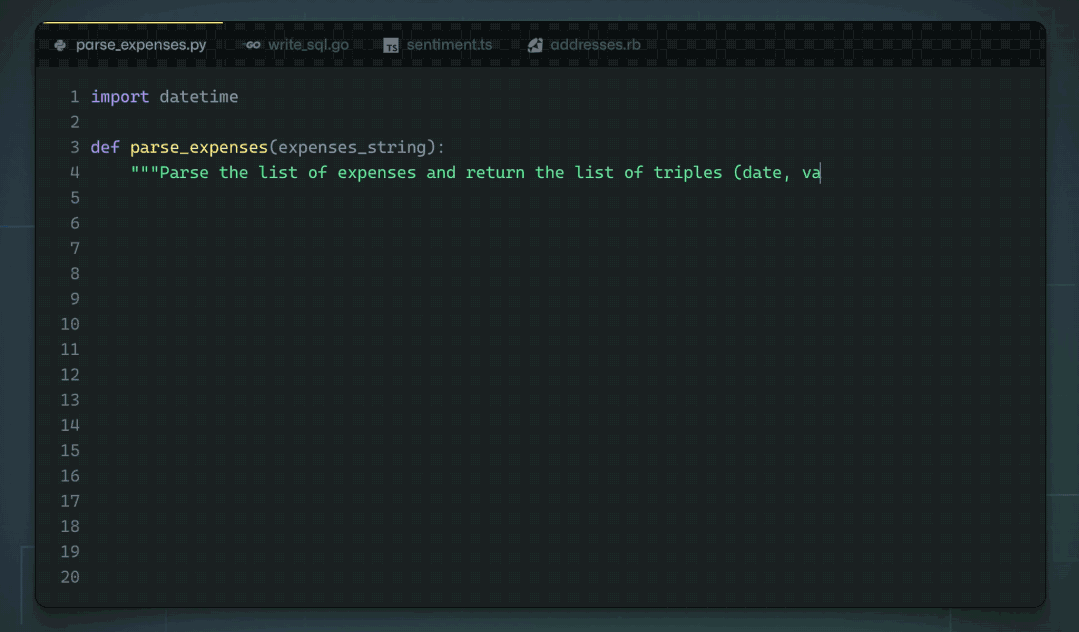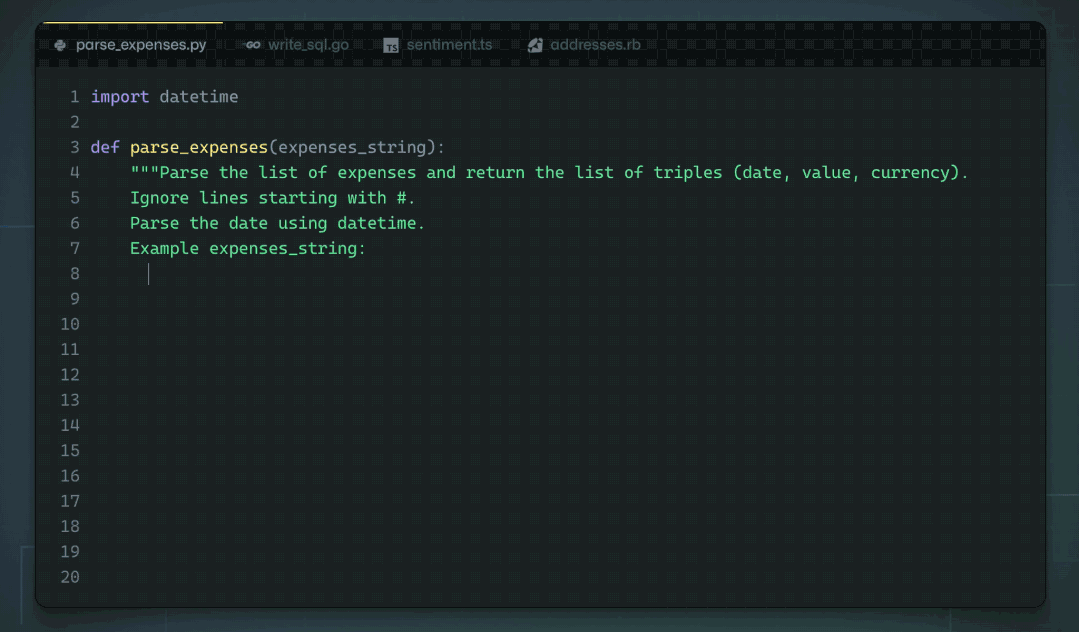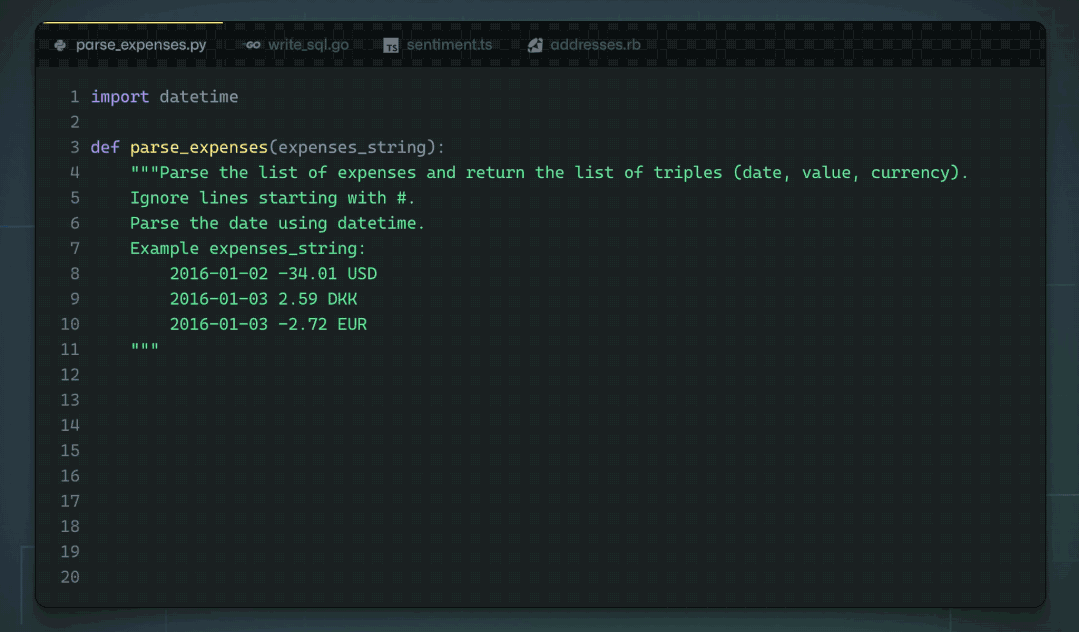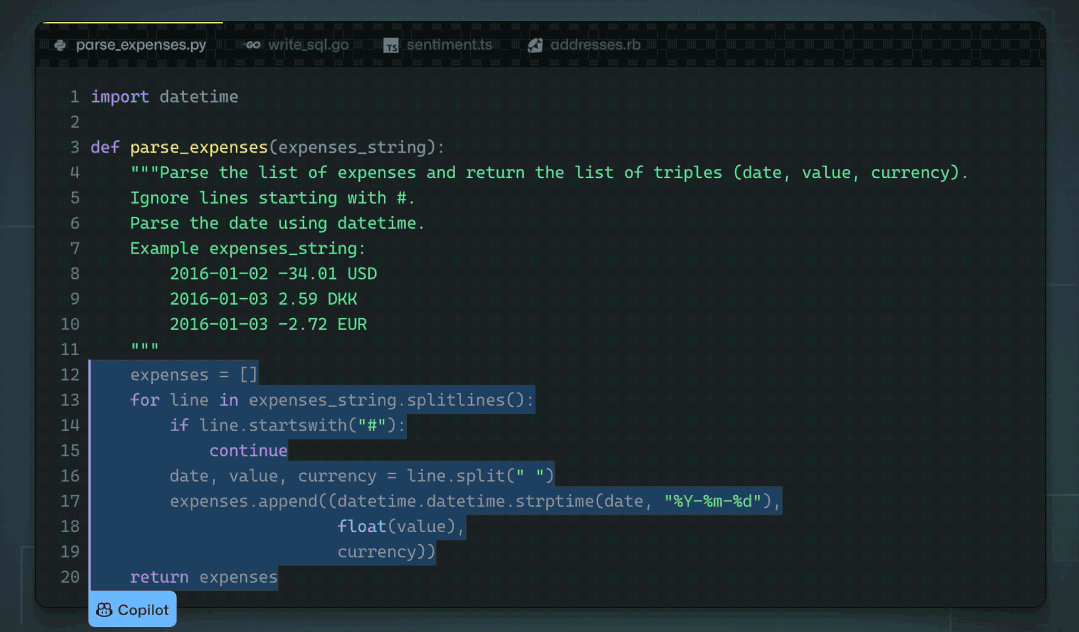
Github Copilot ist für mich sehr nützlich. Es liest oft auf magische Weise meine Gedanken und macht hilfreiche Vorschläge. Was mich am meisten überraschte, war die Fähigkeit, Funktionen/Variablen aus dem umgebenden Code (einschließlich Code in anderen Dateien) richtig zu „erraten“. Dies geschieht nur, wenn die Copilot-Erweiterung wertvolle Informationen aus dem umgebenden Code an das Codex-Modell sendet. Ich war neugierig, wie es funktioniert, also beschloss ich, einen Blick auf den Quellcode zu werfen.
In diesem Beitrag versuche ich, spezifische Fragen zu den Interna von Copilot zu beantworten und gleichzeitig einige interessante Beobachtungen zu beschreiben, die ich beim Durchforsten des Codes gemacht habe.
Der Code für dieses Projekt ist hier zu finden:
# 🎜🎜#Codeadresse: https://github.com/thakkarparth007/copilot-explorer
Der gesamte Artikel ist wie folgt strukturiert folgt: # 🎜🎜#
 Reverse Engineering Overview
Reverse Engineering Overview
Sie können die rückentwickelte Copilot-Codebasis mithilfe der von mir erstellten Tools erkunden. Es ist möglicherweise nicht umfassend und verfeinert, aber Sie können es dennoch verwenden, um den Code von Copilot zu erkunden. Tool-Link: https:// /thakkarparth007.github.io/copilot-explorer/
Copilot: Übersicht
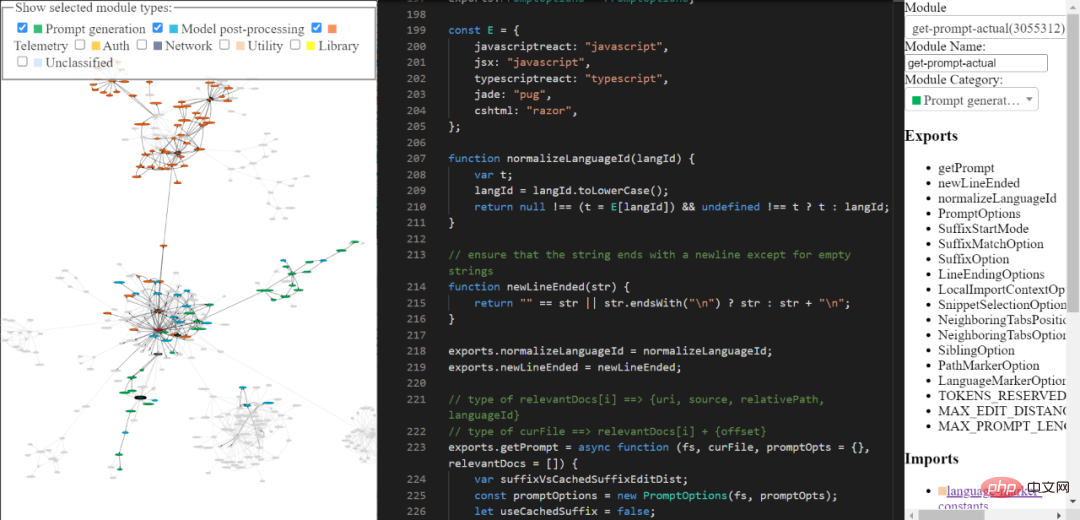
Da Codex nun auf einer großen Menge öffentlichen Github-Codes trainiert wurde, ist es sinnvoll, dass es nützliche Vorschläge machen kann. Codex hat jedoch keine Möglichkeit zu wissen, welche Funktionen in Ihrem aktuellen Projekt vorhanden sind. Dennoch kann es Vorschläge zu Projektfunktionen machen. Beantworten wir diese Frage in zwei Teilen: Schauen wir uns zunächst ein echtes Prompt-Beispiel an, das von Copilot generiert wurde, und dann schauen wir uns an, wie es generiert wird. Eingabeaufforderung sieht aus wie Die Copilot-Erweiterung kodiert viele Informationen zu Ihrem Projekt in der Eingabeaufforderung. Copilot verfügt über eine ziemlich komplexe Prompt-Engineering-Pipeline. Hier ist ein Beispiel für eine Eingabeaufforderung:
Tipp 1: Schnelles Engineering
{"prefix": "# Path: codeviz\app.pyn# Compare this snippet from codeviz\predictions.py:n# import jsonn# import sysn# import timen# from manifest import Manifestn# n# sys.path.append(__file__ + "/..")n# from common import module_codes, module_deps, module_categories, data_dir, cur_dirn# n# gold_annots = json.loads(open(data_dir / "gold_annotations.js").read().replace("let gold_annotations = ", ""))n# n# M = Manifest(n# client_name = "openai",n# client_connection = open(cur_dir / ".openai-api-key").read().strip(),n# cache_name = "sqlite",n# cache_connection = "codeviz_openai_cache.db",n# engine = "code-davinci-002",n# )n# n# def predict_with_retries(*args, **kwargs):n# for _ in range(5):n# try:n# return M.run(*args, **kwargs)n# except Exception as e:n# if "too many requests" in str(e).lower():n# print("Too many requests, waiting 30 seconds...")n# time.sleep(30)n# continuen# else:n# raise en# raise Exception("Too many retries")n# n# def collect_module_prediction_context(module_id):n# module_exports = module_deps[module_id]["exports"]n# module_exports = [m for m in module_exports if m != "default" and "complex-export" not in m]n# if len(module_exports) == 0:n# module_exports = ""n# else:n# module_exports = "It exports the following symbols: " + ", ".join(module_exports)n# n# # get module snippetn# module_code_snippet = module_codes[module_id]n# # snip to first 50 lines:n# module_code_snippet = module_code_snippet.split("\n")n# if len(module_code_snippet) > 50:n# module_code_snippet = "\n".join(module_code_snippet[:50]) + "\n..."n# else:n# module_code_snippet = "\n".join(module_code_snippet)n# n# return {"exports": module_exports, "snippet": module_code_snippet}n# n# #### Name prediction ####n# n# def _get_prompt_for_module_name_prediction(module_id):n# context = collect_module_prediction_context(module_id)n# module_exports = context["exports"]n# module_code_snippet = context["snippet"]n# n# prompt = f"""\n# Consider the code snippet of an unmodule named.n# nimport jsonnfrom flask import Flask, render_template, request, send_from_directorynfrom common import *nfrom predictions import predict_snippet_description, predict_module_namennapp = Flask(__name__)nn@app.route('/')ndef home():nreturn render_template('code-viz.html')nn@app.route('/data/<filename>')ndef get_data_files(filename):nreturn send_from_directory(data_dir, filename)nn@app.route('/api/describe_snippet', methods=['POST'])ndef describe_snippet():nmodule_id = request.json['module_id']nmodule_name = request.json['module_name']nsnippet = request.json['snippet']ndescription = predict_snippet_description(nmodule_id,nmodule_name,nsnippet,n)nreturn json.dumps({'description': description})nn# predict name of a module given its idn@app.route('/api/predict_module_name', methods=['POST'])ndef suggest_module_name():nmodule_id = request.json['module_id']nmodule_name = predict_module_name(module_id)n","suffix": "if __name__ == '__main__':rnapp.run(debug=True)","isFimEnabled": true,"promptElementRanges": [{ "kind": "PathMarker", "start": 0, "end": 23 },{ "kind": "SimilarFile", "start": 23, "end": 2219 },{ "kind": "BeforeCursor", "start": 2219, "end": 3142 }]}</filename>Nach dem Login kopieren
Wie Sie sehen können, enthält die obige Eingabeaufforderung ein Präfix und ein Suffix. Copilot sendet diese Eingabeaufforderung dann (nach einiger Formatierung) an das Modell. Da das Suffix in diesem Fall nicht leer ist, ruft Copilot den Codex im „Einfügemodus“ auf, dh im Fill-in-Middle-Modus (FIM).
Wenn Sie sich das Präfix ansehen, werden Sie feststellen, dass es Code aus einer anderen Datei im Projekt enthält. Siehe # Vergleichen Sie diesen Ausschnitt aus codevizpredictions.py: Wie werden die Codezeile und die Zeilen danach
prompt vorbereitet?
Grob wird die folgende Abfolge von Schritten ausgeführt, um die Eingabeaufforderung zu generieren:
Im Allgemeinen wird die Eingabeaufforderung Schritt für Schritt durch die folgende Reihe von Schritten generiert:
1 Einstiegspunkt: Eingabeaufforderungsextraktion tritt auf, wenn das angegebene Dokument und die Cursorposition angegeben sind. Der generierte Haupteinstiegspunkt ist extractPrompt (ctx, doc, insertPos)
2 Fragen Sie den relativen Pfad und die Sprach-ID des Dokuments von VSCode ab. Siehe: getPromptForRegularDoc (ctx, doc, insertPos)
3. Zugehörige Dokumente: Fragen Sie dann die 20 zuletzt aufgerufenen Dateien in derselben Sprache von VSCode ab. Siehe getPromptHelper (ctx, docText, insertOffset, docRelPath, docUri, docLangId) . Diese Dateien werden später verwendet, um ähnliche Snippets zu extrahieren, die in die Eingabeaufforderung eingefügt werden sollen. Ich persönlich finde es seltsam, dieselbe Sprache als Filter zu verwenden, da die Entwicklung mehrerer Sprachen ziemlich verbreitet ist. Aber ich denke, das deckt immer noch die meisten Fälle ab.
4. Konfiguration: Als nächstes legen Sie einige Optionen fest. Dazu gehören insbesondere:
5. Präfixberechnung: Erstellen Sie nun eine „Prompt-Wunschliste“, um den Präfixteil des Prompts zu berechnen. Hier fügen wir verschiedene „Elemente“ und deren Prioritäten hinzu. Ein Element könnte beispielsweise so etwas wie „Vergleiche dieses Fragment aus “ sein, oder der Kontext eines lokalen Imports oder die Sprach-ID und/oder der Pfad jeder Datei. Dies alles geschieht in getPrompt (fs, curFile, promptOpts = {}, relevantDocs = []) .
6. Suffixberechnung: Der vorherige Schritt gilt für Präfixe, aber die Logik der Suffixe ist relativ einfach – füllen Sie einfach das Token-Budget mit einem beliebigen verfügbaren Suffix aus dem Cursor. Dies ist die Standardeinstellung, aber die Startposition des Suffixes variiert geringfügig je nach der Option SuffixStartMode, die auch vom AB-Experiment-Framework gesteuert wird. Wenn SuffixStartMode beispielsweise ein SiblingBlock ist, findet Copilot zunächst das nächstliegende funktionale Geschwister der bearbeiteten Funktion und schreibt das Suffix von dort.
Ein genauerer Blick auf die Fragmentextraktion
Für mich scheint der vollständigste Teil der Eingabeaufforderungsgenerierung das Extrahieren von Fragmenten aus anderen Dateien zu sein. Es wird hier aufgerufen und durch neighbour-snippet-selector.getNeighbourSnippets definiert. Abhängig von den Optionen wird dabei der „Fixed Window Jaccard Matcher“ oder der „Indentation based Jaccard Matcher“ verwendet. Ich bin mir nicht 100 % sicher, aber es sieht nicht so aus, als ob der auf Einrückungen basierende Jaccard Matcher tatsächlich verwendet wird.
Standardmäßig verwenden wir Jaccard Matcher mit festem Fenster. In diesem Fall wird die angegebene Datei (aus der die Fragmente extrahiert werden) in Schiebefenster mit fester Größe aufgeteilt. Berechnen Sie dann die Jaccard-Ähnlichkeit zwischen jedem Fenster und der Referenzdatei (der Datei, in die Sie tippen). Für jede „zugehörige Datei“ wird nur das optimale Fenster zurückgegeben (obwohl es eine Anforderung gibt, die obersten K-Fragmente zurückzugeben, wird diese niemals befolgt). Standardmäßig wird FixedWindowJaccardMatcher im „Eager-Modus“ verwendet (d. h. die Fenstergröße beträgt 60 Zeilen). Dieser Modus wird jedoch vom AB Experimentation-Framework gesteuert, sodass wir möglicherweise andere Modi verwenden.
Copilot bietet die Vervollständigung über zwei Benutzeroberflächen: Inline/GhostText und Copilot Panel. In beiden Fällen gibt es einige Unterschiede in der Art und Weise, wie das Modell aufgerufen wird.
Inline/GhostText
Hauptmodul: https://thakkarparth007.github.io/copilot-explorer/codedeviz/templates/code-viz.html#m9334&pos=301:14
In Unter anderem erfordert die Copilot-Erweiterung, dass das Modell nur sehr wenige Vorschläge (1-3 Teile) zur Beschleunigung bereitstellt. Außerdem werden die Ergebnisse des Modells aktiv zwischengespeichert. Darüber hinaus sorgt es dafür, dass die Vorschläge angepasst werden, wenn der Benutzer weiter tippt. Wenn der Benutzer sehr schnell tippt, wird das Modell außerdem aufgefordert, die Funktionsentprellung zu aktivieren.
Diese Benutzeroberfläche legt auch eine Logik fest, um zu verhindern, dass unter bestimmten Umständen Anfragen gesendet werden. Befindet sich der Benutzercursor beispielsweise in der Mitte einer Zeile, wird die Anfrage nur gesendet, wenn das Zeichen rechts davon ein Leerzeichen, eine schließende Klammer usw. ist.
1. Ungültige Anfragen durch Kontextfilter blockieren
Was noch interessanter ist, ist, dass das Modul nach der Generierung der Eingabeaufforderung prüft, ob die Eingabeaufforderung „gut genug“ ist, um das Modell aufzurufen. Dies wird durch die Berechnung des „Kontextfilterungs-Scores“ erreicht. Diese Bewertung scheint auf einem einfachen logistischen Regressionsmodell zu basieren, das 11 Merkmale wie Sprache, ob der vorherige Vorschlag angenommen/abgelehnt wurde, die Dauer zwischen vorherigen Annahmen/Ablehnungen, die Länge der letzten Zeile in der Eingabeaufforderung und die letzte enthält Charakter usw. Dieses Modellgewicht ist im Erweiterungscode selbst enthalten.
Wenn die Punktzahl unter dem Schwellenwert liegt (Standard 15 %), wird keine Anfrage gestellt. Es wäre interessant, dieses Modell zu untersuchen. Ich habe beobachtet, dass einige Sprachen eine höhere Gewichtung haben als andere (z. B. php > js > python > rust > dart…php). Eine weitere intuitive Beobachtung ist, dass die Punktzahl niedriger ist, wenn die Eingabeaufforderung mit ) oder ] endet, als wenn sie mit ( oder [ endet. Dies ist sinnvoll, da ersteres eher darauf hinweist, dass es bereits „erledigt“ wurde, während die Letzteres zeigt deutlich, dass der Benutzer von der automatischen Vervollständigung profitieren wird =12: 1
Kernlogik 1: https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/code-viz.html#m893&pos=9:1
Kernlogik 2: https ://thakkarparth007.github.io/copilot-explorer/codedeviz/templates/code-viz.html#m2388&pos=67:1Diese Benutzeroberfläche fordert im Vergleich zur Inline-Benutzeroberfläche mehr Beispiele vom Modell an (standardmäßig 10). . Diese Benutzeroberfläche scheint keine kontextbezogene Filterlogik zu haben (macht Sinn, Sie möchten das Modell nicht auffordern, wenn der Benutzer es explizit aufruft)
Hier gibt es zwei hauptsächlich interessante Dinge:
... .
Keine unnötigen Vervollständigungsvorschläge anzeigen:
Tipp 3: Telemetrie
Github behauptete in einem früheren Blog, dass 40 % des von Programmierern geschriebenen Codes von Copilot geschrieben werden (für beliebte Sprachen wie Python). ). Ich war neugierig, wie sie diese Zahl gemessen haben, also wollte ich etwas in den Telemetriecode einfügen.Ich würde auch gerne wissen, welche Telemetriedaten es sammelt, insbesondere ob es Codeschnipsel sammelt. Ich frage mich darüber, denn obwohl wir die Copilot-Erweiterung problemlos auf das Open-Source-FauxPilot-Backend anstelle des Github-Backends verweisen könnten, sendet die Erweiterung möglicherweise immer noch Codeausschnitte per Telemetrie an Github, was einige Leute, die Bedenken hinsichtlich des Code-Datenschutzes haben, davon abhält, sie zu verwenden. Kopilot. Ich frage mich, ob das der Fall ist.
Frage 1: Wie wird der 40 %-Wert gemessen?
Bei der Messung der Erfolgsquote von Copilot geht es nicht nur darum, einfach die Anzahl der Annahmen/Ablehnungen zu zählen, da die Leute normalerweise die Empfehlungen akzeptieren und einige Änderungen vornehmen. Daher prüfen Github-Mitarbeiter, ob der akzeptierte Vorschlag noch im Code vorhanden ist. Konkret prüfen sie 15 Sekunden, 30 Sekunden, 2 Minuten, 5 Minuten und 10 Minuten nach der Eingabe des vorgeschlagenen Codes.Genaue Suchen nach akzeptierten Vorschlägen sind jetzt zu restriktiv, sodass sie den Bearbeitungsabstand (auf Zeichenebene und Wortebene) zwischen dem vorgeschlagenen Text und dem Fenster um die Einfügemarke messen. Ein Vorschlag gilt als „noch im Code“, wenn der Bearbeitungsabstand auf Wortebene zwischen der Einfügung und dem Fenster weniger als 50 % beträgt (normalisiert auf die Vorschlagsgröße).
Das alles gilt natürlich nur für akzeptierte Codes. Frage 2: Enthalten Telemetriedaten Codeausschnitte? Ja, inklusive. Dreißig Sekunden nach Annahme oder Ablehnung eines Vorschlags „erfasst“ der Copilot einen Schnappschuss in der Nähe des Einfügepunkts. Insbesondere ruft die Erweiterung den Prompt-Extraktionsmechanismus auf, um einen „hypothetischen Prompt“ zu sammeln, der zum Unterbreiten von Vorschlägen an diesem Einfügepunkt verwendet werden kann. Copilot erfasst auch die „hypothetische Vervollständigung“, indem es den Code zwischen dem Einfügepunkt und dem „geschätzten“ Endpunkt erfasst. Ich verstehe nicht ganz, wie es diesen Endpunkt errät. Wie bereits erwähnt, geschieht dies nach Annahme oder Ablehnung. Ich vermute, dass diese Schnappschüsse als Trainingsdaten zur weiteren Verbesserung des Modells verwendet werden können. Allerdings scheinen 30 Sekunden eine zu kurze Zeit zu sein, um anzunehmen, dass sich der Code „beruhigt“ hat. Da die Telemetrie jedoch das Github-Repo enthält, das dem Projekt des Benutzers entspricht, kann das GitHub-Personal diese relativ verrauschten Daten offline bereinigen, selbst wenn ein Zeitraum von 30 Sekunden verrauschte Datenpunkte erzeugt. Natürlich ist das alles nur Spekulation meinerseits. Beachten Sie, dass Sie auf GitHub entscheiden können, ob Sie der Verwendung Ihrer Codeausschnitte zur „Verbesserung des Produkts“ zustimmen nicht an den Server gesendet werden (zumindest in Version 1.57 habe ich dies überprüft, aber ich habe auch Version 1.65 überprüft). Ich überprüfe dies, indem ich mir den Code ansehe und Telemetriedatenpunkte protokolliere, bevor sie über das Netzwerk gesendet werden. Andere Beobachtungen In diesem Artikel habe ich die Datei worker.js, die mit der Erweiterung verteilt wird, nicht behandelt. Auf den ersten Blick scheint es im Grunde nur eine parallele Version der Eingabeaufforderungs-Extraktionslogik bereitzustellen, verfügt jedoch möglicherweise über mehr Funktionen. Dateiadresse: https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/worker_expanded.js#🎜 🎜# Ausführliche Protokollierung aktivieren Wenn Sie die ausführliche Protokollierung aktivieren möchten, können Sie Folgendes tun Dies kann durch Ändern des Erweiterungscodes erreicht werden: Nach Erweiterungsdateien suchen. Es befindet sich normalerweise unter ~/.vscode/extensions/github.copilot-/dist/extension.js.
Das obige ist der detaillierte Inhalt vonNach dem Reverse Engineering des Copilot stellte ich fest, dass möglicherweise nur ein kleines Modell mit 12B-Parametern verwendet wird.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



