

想象一下,你正在网上购物,你发现有两家店铺销售同一种商品,它们的评分相同。然而,第一家只有一个人评分,第二家有 100 人评分。您会更信任哪个评分呢?最终您会选择购买哪家的商品呢?大多数人的答案很简单。100 个人的意见肯定比只有一个人的意见更值得信赖。这被称为“群众的智慧”,这也是集成方法有效的原因。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

通常,我们只从训练数据中创建一个学习者(学习者=训练模型)(即,我们只在训练数据上训练一个机器学习模型)。而集成方法是让多个学习者解决同一个问题,然后将他们组合在一起。这些学习者被称为基础学习者,可以有任何底层算法,如神经网络,支持向量机,决策树等。如果所有这些基础学习者都由相同的算法组成那么它们被称为同质基础学习者,而如果它们由不同的算法组成那么它们被称为异质基础学习者。与单个基础学习者相比,集成具有更好的泛化能力,从而获得更好的结果。
当集成方法由弱学习者组成时。因此,基础学习者有时被称为弱学习者。而集成模型或强学习者(是这些弱学习者的组合)具有更低的偏差/方差,并获得更好的表现。这种集成方法将弱学习者转变为强学习者的能力之所以普及,是因为在实践中更容易获得弱学习者。
近年来,集成方法不断赢了各种在线比赛。除了在线比赛之外,集成方法也被应用于现实生活中,如目标检测、识别和跟踪等计算机视觉技术。
根据基学习器的生成方式,集成方法可以分为两大类,即顺序集成方法和并行集成方法。顾名思义,在Sequential ensemble 方法中,基学习器是按顺序生成的,然后组合起来进行预测,例如AdaBoost等Boosting算法。而在Parallel ensemble 方法中,基础学习器是并行生成的,然后组合起来进行预测,例如随机森林和Stacking等Bagging算法算法。下图显示了解释并行和顺序方法的简单架构。
根据基础学习者的生成方式不同,集成方法可分为两大类:顺序集成方法和并行集成方法。顾名思义,在顺序集成方法中,基学习者是按顺序生成的,然后组合起来进行预测,例如AdaBoost等Boosting算法。在并行集成方法中,基学习者是并行生成的,然后组合在一起进行预测,例如随机森林和Stacking等Bagging算法。下图展示了一个简单的体系结构,解释了并行和顺序方法。
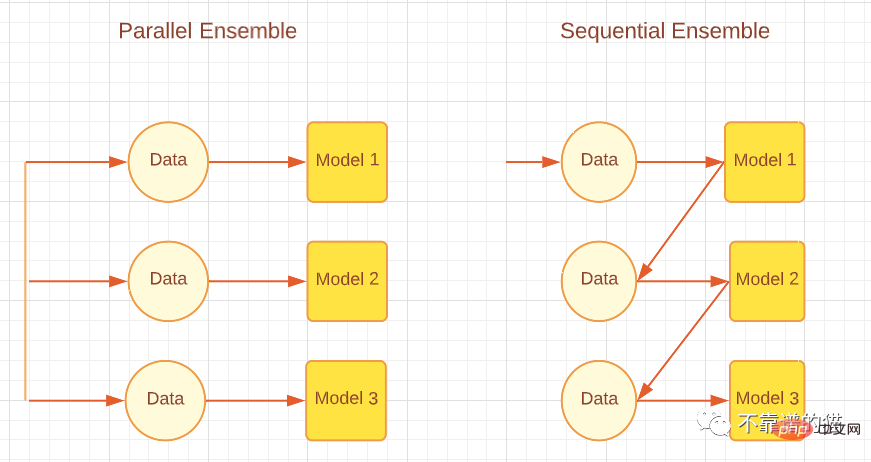
并行与顺序集成方法
顺序学习方法利用弱学习者之间的依赖关系,以残差递减的方式提高整体性能,使后学习者更多地关注前学习者的错误。粗略地说(对于回归问题),boosting方法所得到的集成模型误差的减小主要是通过降低弱学习者的高偏差来实现的,尽管有时也会观察到方差的减小。另一方面,并行集成方法通过组合独立弱学习者来减小误差,即它利用了弱学习者之间的独立性。这种误差的减小是由于机器学习模型方差的减小。因此,我们可以归纳为,boosting主要通过减小机器学习模型的偏差来减小误差,而bagging通过减小机器学习模型的方差来减小误差。这是很重要的,因为选择哪种集成方法将取决于弱学习者是否有高方差或高偏差。
在生成这些所谓的基础学习者之后,我们不会选择这些学习者中最好的,而是将它们组合在一起以实现更好的泛化,我们这样做的方式在集成方法中起着重要作用。
平均:当输出是数字时,最常见的组合基础学习者的方法是平均。平均可以是简单平均或加权平均。对于回归问题,简单平均将是所有基础模型的误差之和除以学习者总数。加权平均的组合输出是通过给每个基础学习者赋予不同的权重来实现的。对于回归问题,我们将每个基学习者的误差与给定的权重相乘,然后求和。
投票:对于名义输出,投票是组合基础学习器最常用的方式。投票可以是不同的类型,例如绝对多数投票、相对多数投票、加权投票和软投票。对于分类问题,绝对多数投票给每个学习者一票,他们投票给一个类标签。无论哪个类标签获得超过 50% 的选票,都是集成的预测结果。但是,如果没有一个类标签获得超过 50% 的选票,则会给出拒绝选项,这意味着组合集成无法做出任何预测。在相对多数投票中,获得最多票数的类标签是预测结果,超过50%的票数对类标签不是必需的。意思是,如果我们有三个输出标签,三个得到的结果都少于50%,比如40% 30% 30%,那么获得40%的类标签就是集合模型的预测结果。。加权投票,就像加权平均一样,根据分类器的重要性和特定学习器的强度为分类器分配权重。软投票用于概率(0到1之间的值)而不是标签(二进制或其他)的类输出。软投票进一步分为简单软投票(对概率进行简单平均)和加权软投票(将权重分配给学习者,概率乘以这些权重并相加)。
学习:另一种组合方法是通过学习进行组合,这是stacking集成方法使用的。在这种方法中,一个称为元学习者的单独学习者在新数据集上进行训练,以组合从原始机器学习数据集生成的其他基础/弱学习者。
请注意,无论是 boosting、bagging还是 stacking,所有这三种集成方法都可以使用同质或异质弱学习者生成。最常见的做法是使用同质弱学习者进行 Bagging 和 Boosting,使用异质弱学习器进行 Stacking。下图很好地分类了三种主要的集成方法。
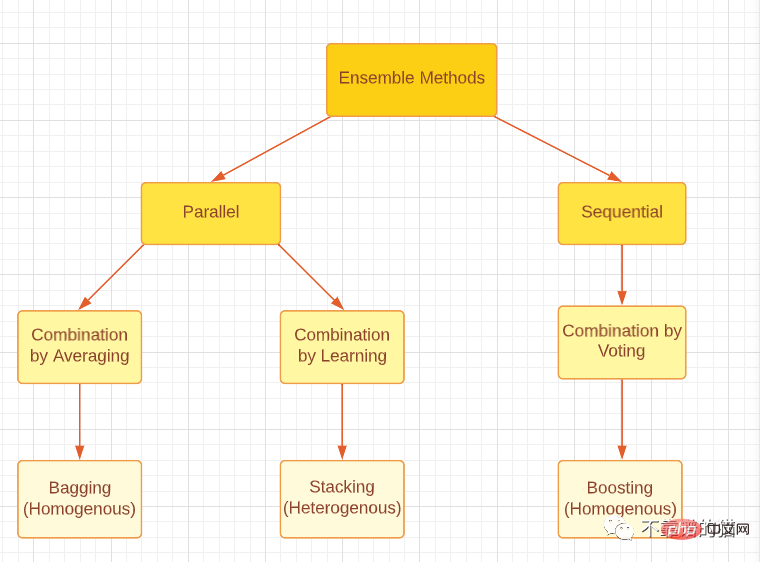
对集成方法的主要类型进行分类
集成多样性是指基础学习器之间的差异有多大,这对于生成良好的集成模型具有重要意义。理论上已经证明,通过不同的组合方法,完全独立(多样化)的基础学习者可以最大程度地减少错误,而完全(高度)相关的学习者不会带来任何改进。这在现实生活中却是一个具有挑战性的问题,因为我们正在训练所有弱学习者通过使用相同的数据集来解决相同的问题,从而导致高相关性。在此之上,我们需要确保弱学习者不是真正糟糕的模型,因为这甚至可能导致集成性能恶化。另一方面,将强而准确的基础学习者组合起来,也可能没有将一些弱学习者和一些强学习者组合起来的效果好。因此,需要在基础学习器的准确程度与基础学习器之间的差异之间取得平衡。
我们可以将我们的数据集划分为子集供基础学习者使用。如果机器学习数据集很大,我们可以简单地将数据集分成相等的部分,然后输入到机器学习模型中。如果数据集很小,我们可以使用随机抽样替换,从原始数据集生成新的数据集。Bagging方法使用bootstrapping技术来生成新的数据集,它基本上是带替换的随机抽样。通过bootstrapping,我们能够创造一些随机性,因为所有生成的数据集都必须拥有一些不同的值。然而,请注意,大多数值(根据理论约为67%)仍然会重复,因此数据集不会完全独立。
所有数据集都包含提供有关数据信息的特征。我们可以创建特征子集并生成不同的数据集并将其输入模型,而不是使用一个模型中的所有特征。这种方法被随机森林技术采用,当数据中存在大量冗余特征时有效。当数据集中的特征很少时,有效性会降低。
该技术通过对基础学习算法应用不同的参数设置,即超参数调优,在基础学习者中产生随机性。例如,通过改变正则化项,可以将不同的初始权重分配给各个神经网络。
最后,集成剪枝技术在某些情况下有助于获得更好的集成性能。集成剪枝(Ensemble Pruning)的意思是,我们只组合学习者的子集,而不是组合所有弱学习者。除此之外,更小的集成可以节省存储和计算资源,从而提高效率。
本文仅仅是机器学习集成方法概述。希望大家能够更加深入的进行研究,更重要的是能购将研究应用于现实生活中。
以上就是机器学习中的集成方法概述的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 //m.sbmmt.com/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 846
846























