


Viele Anwendungen in der Informatik und im maschinellen Lernen (ML) erfordern die Verarbeitung mehrdimensionaler Datensätze, die sich über Koordinatensysteme erstrecken, und ein einzelner Datensatz muss möglicherweise auch Terabytes oder Petabytes an Daten speichern. Andererseits kann die Arbeit mit solchen Datensätzen auch eine Herausforderung darstellen, da Benutzer Daten in unregelmäßigen Abständen und in unterschiedlichen Maßstäben lesen und schreiben und häufig umfangreiche parallele Arbeiten durchführen müssen.
Um die oben genannten Probleme zu lösen, hat Google eine Open-Source-C++- und Python-Softwarebibliothek TensorStore entwickelt, die für die Speicherung und den Betrieb n-dimensionaler Daten konzipiert ist. Auch Jeff Dean, Leiter von Google AI, twitterte, dass TensorStore nun offiziell Open Source sei.
Zu den Hauptfunktionen von TensorStore gehören: Bietet eine einheitliche API zum Lesen und Schreiben mehrerer Array-Formate, einschließlich zarr und N5;
API für Datenzugriff und -bearbeitung
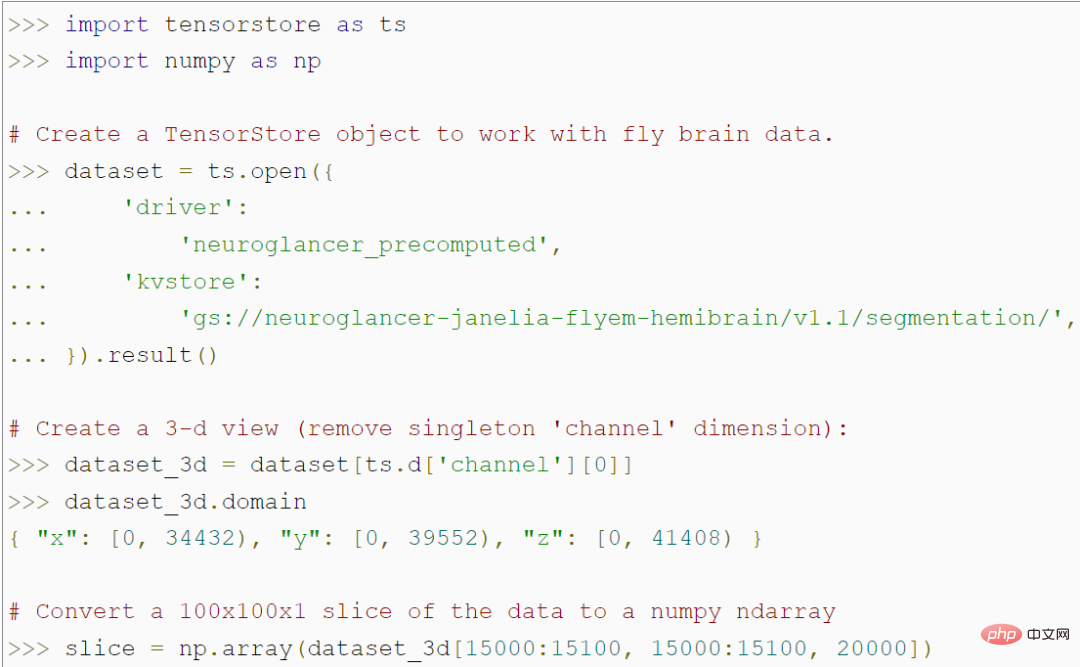
TensorStore bietet eine einfache Python-API zum Laden und Bearbeiten großer Array-Daten. Der folgende Code erstellt beispielsweise ein TensorStore-Objekt, das ein 56 Billionen Voxel großes 3D-Bild eines Fliegengehirns darstellt und den Zugriff auf 100x100-Bild-Patch-Daten in einem NumPy-Array ermöglicht: 
#🎜 🎜#Es ist erwähnenswert, dass das Programm nicht auf die tatsächlichen Daten im Speicher zugreift, bevor es auf den spezifischen 100x100-Patch zugreift, sodass es beliebig große zugrunde liegende Datensätze laden und bearbeiten kann, ohne sie zu speichern den gesamten Datensatz im Speicher. TensorStore verwendet im Wesentlichen dieselbe Indizierungs- und Operationssyntax wie Standard-NumPy.
Darüber hinaus bietet TensorStore umfassende Unterstützung für erweiterte Indizierungsfunktionen, einschließlich Ausrichtung, virtuelle Ansichten und mehr.Der folgende Code zeigt, wie TensorStore zum Erstellen eines Zarr-Arrays verwendet wird und wie die asynchrone API von TensorStore einen höheren Durchsatz erzielen kann:
 #🎜 🎜#
#🎜 🎜#
Sicherheits- und Leistungserweiterungen
Wie wir alle wissen, erfordert die Analyse und Verarbeitung großer Datenmengen viele Rechenressourcen, was normalerweise der Fall ist müssen über die Parallelisierung von CPU- oder Beschleunigerkernen auf mehreren Maschinen verteilt werden. Daher besteht ein grundlegendes Ziel von TensorStore darin, parallele Verarbeitung zu implementieren, um sowohl Sicherheit als auch hohe Leistung zu erreichen. Tatsächlich haben sie bei Tests in Google-Rechenzentren herausgefunden, dass die Lese- und Schreibleistung von TensorStore mit zunehmender Anzahl an CPUs nahezu linear zunimmt:
# 🎜🎜#
Bei der Lese- und Schreibleistung von Datensätzen im Zarr-Format auf Google Cloud Storage (GCS) wächst die Lese- und Schreibleistung nahezu linear mit der Anzahl der Rechenaufgaben. 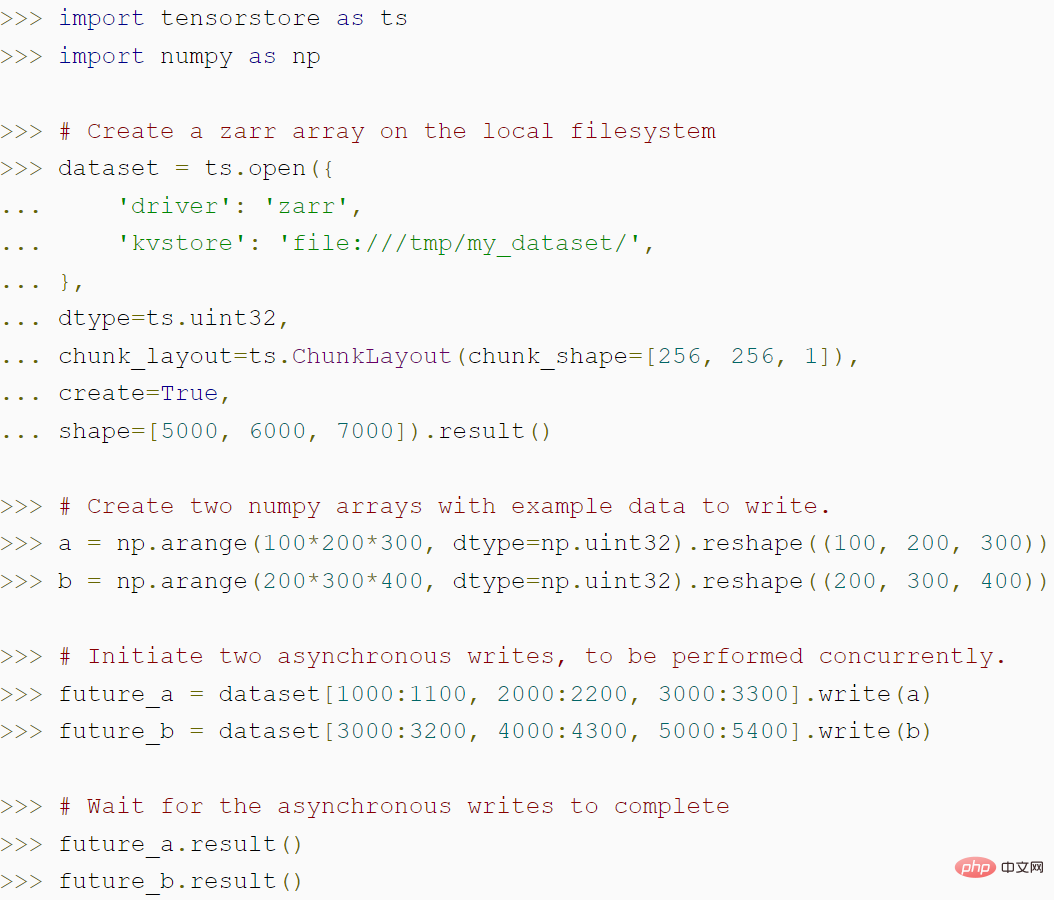
TensorStore bietet außerdem einen konfigurierbaren Speichercache und eine asynchrone API, um Lese- und Schreibvorgänge im Hintergrund zu ermöglichen, während das Programm andere Arbeiten erledigt Setzen Sie die Ausführung fort. Um das verteilte Computing von TensorStore mit Datenverarbeitungsworkflows kompatibel zu machen, integriert Google TensorStore auch in parallele Computing-Bibliotheken wie Apache Beam.
Beispiel 1 Sprachmodell: In jüngster Zeit sind im Bereich des maschinellen Lernens einige fortgeschrittene Sprachmodelle wie PaLM aufgetaucht. Diese Modelle enthalten Hunderte Milliarden Parameter und zeigen erstaunliche Fähigkeiten beim Verständnis und der Erzeugung natürlicher Sprache. Diese Modelle stellen jedoch eine Herausforderung für die Recheneinrichtungen dar. Insbesondere das Training eines Sprachmodells wie PaLM erfordert die parallele Arbeit von Tausenden von TPUs.
Das effiziente Lesen und Schreiben von Modellparametern ist ein Problem im Trainingsprozess: Beispielsweise ist das Training auf verschiedene Maschinen verteilt, die Parameter müssen jedoch regelmäßig gespeichert werden der Prüfpunkt; ein weiteres Beispiel ist, dass ein einzelnes Training nur einen bestimmten Parametersatz lesen darf, um den Overhead zu vermeiden, der zum Laden des gesamten Modellparametersatzes erforderlich ist (der Hunderte von GB betragen kann).
TensorStore kann die oben genannten Probleme lösen. Es wurde zur Verwaltung von Prüfpunkten im Zusammenhang mit großen (Multipod-)Modellen verwendet und wurde in Frameworks wie T5X und Pathways integriert. TensorStore konvertiert Prüfpunkte in Speicher im Zarr-Format und wählt die Blockstruktur aus, damit die Partitionen jeder TPU parallel und unabhängig gelesen und geschrieben werden können. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Wenn gespeichert Am Prüfpunkt werden die Parameter im Zarr-Format geschrieben und das Blockraster wird weiter unterteilt, um das Parameterraster auf der TPU aufzuteilen. Der Host schreibt Zarr-Blöcke parallel für jede Partition, die der TPU des Hosts zugewiesen ist. Mit der asynchronen API von TensorStore wird das Training fortgesetzt, auch wenn noch Daten in den persistenten Speicher geschrieben werden. Bei der Wiederherstellung von einem Prüfpunkt liest jeder Host nur die diesem Host zugewiesenen Partitionsblöcke.
Beispiel 2 Gehirn-3D-Mapping: Synapsen-aufgelöste Konnektomik zielt darauf ab, Tiere und Menschen auf der Ebene einzelner synaptischer Verbindungen abzubilden. Um dies zu erreichen, ist eine Bildgebung des Gehirns mit extrem hoher Auflösung (Nanoskala) über ein Sichtfeld von Millimetern oder mehr erforderlich, was zu Datenmengen im Petabytebereich führt. Allerdings gibt es bei Datensätzen auch heute noch Probleme bei der Speicherung, Verarbeitung usw. Selbst eine einzelne Gehirnprobe kann Millionen Gigabyte Speicherplatz beanspruchen. 
Google hat TensorStore verwendet, um die Rechenherausforderungen zu lösen, die mit großen Connectomics-Datensätzen verbunden sind. Konkret hat TensorStore damit begonnen, einige Connectomics-Datensätze zu verwalten und Google Cloud Storage als zugrunde liegendes Objektspeichersystem zu verwenden. Derzeit wird TensorStore für den Datensatz H01 der menschlichen Großhirnrinde verwendet, wobei die ursprünglichen Bilddaten 1,4 PB (ungefähr 500.000 * 350.000 * 5.000 Pixel) betragen. Die Rohdaten werden dann in unabhängige Blöcke von 128 x 128 x 16 Pixeln unterteilt und in einem „Neuroglancer-vorberechneten“ Format gespeichert, das von TensorStore leicht bearbeitet werden kann.
Mit TensorStore können Sie einfach auf die zugrunde liegenden Daten zugreifen und diese bearbeiten (fly Gehirnrekonstruktion)
Wer loslegen möchte, kann das TensorStore PyPI-Paket mit der folgenden Methode installieren:  # 🎜🎜#
# 🎜🎜#
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tensorstore</span>
Das obige ist der detaillierte Inhalt vonGoogle löst das Problem der Speicherung und Bearbeitung n-dimensionaler Daten mit einer Open-Source-Softwarebibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



