



Reguläre Ausdrücke können zum Suchen, Bearbeiten und Bearbeiten von Text verwendet werden. Python RegEx wird von fast allen Unternehmen häufig verwendet und ist für ihre Anwendungen in der Branche gut geeignet, wodurch reguläre Ausdrücke immer wichtiger werden.
Heute lernen wir gemeinsam reguläre Python-Ausdrücke.
Warum reguläre Ausdrücke verwenden?
Um diese Frage zu beantworten, schauen wir uns zunächst die verschiedenen Probleme an, mit denen wir konfrontiert sind und die durch die Verwendung regulärer Ausdrücke gelöst werden können.
Stellen Sie sich das folgende Szenario vor:
Am Ende des Artikels befindet sich eine Protokolldatei mit einer großen Datenmenge. Wir hoffen, aus dieser Protokolldatei nur Datum und Uhrzeit zu erhalten. Die Lesbarkeit der Logdatei ist auf den ersten Blick sehr gering.

In diesem Fall können reguläre Ausdrücke verwendet werden, um Muster zu erkennen und die erforderlichen Informationen einfach zu extrahieren.
Stellen Sie sich das nächste Szenario vor: Sie sind Verkäufer und haben viele E-Mail-Adressen, viele davon sind gefälscht/ungültig. Sehen Sie sich das Bild unten an:

Wir können eine Formel für reguläre Ausdrücke verwenden, die dies überprüfen kann das Format von E-Mail-Adressen und filtern gefälschte Ausweise aus echten Ausweisen heraus.
Das nächste Szenario ist dem des Verkäuferbeispiels sehr ähnlich. Betrachten Sie das folgende Bild:

Wie validieren wir eine Telefonnummer und klassifizieren sie dann nach Herkunftsland?
Jede richtige Zahl weist ein bestimmtes Muster auf, das mithilfe regulärer Ausdrücke verfolgt und verfolgt werden kann.
Als nächstes kommt ein weiteres einfaches Szenario:
Wir haben eine Studentendatenbank mit Details wie Name, Alter und Adresse. Stellen Sie sich eine Situation vor, in der der Bezirkscode ursprünglich 59006 lautete, jetzt aber in 59076 geändert wurde. Eine Situation, in der die manuelle Aktualisierung dieses Codes für jeden Schüler sehr zeitaufwändig und der Prozess sehr langwierig wäre.
Um diese Probleme mit regulären Ausdrücken zu lösen, suchen wir im Grunde zunächst eine bestimmte Zeichenfolge aus den Schülerdaten, die PIN-Codes enthält, und ersetzen sie dann alle durch die neue Zeichenfolge.
Betrachten Sie das folgende Beispiel:
 Unter der Annahme, dass wir nur die Stadt benötigen, kann diese aus allen Daten für eine bestimmte Zeichenfolge formatiert in ein Wörterbuch konvertiert werden, das nur den Namen und die Stadt enthält. Die Frage ist nun: Können wir ein Muster für das Erraten von Namen und Städten erkennen? Wir können auch das Alter herausfinden, wenn wir älter werden, ist es einfach, oder? Es ist nur eine ganze Zahl.
Unter der Annahme, dass wir nur die Stadt benötigen, kann diese aus allen Daten für eine bestimmte Zeichenfolge formatiert in ein Wörterbuch konvertiert werden, das nur den Namen und die Stadt enthält. Die Frage ist nun: Können wir ein Muster für das Erraten von Namen und Städten erkennen? Wir können auch das Alter herausfinden, wenn wir älter werden, ist es einfach, oder? Es ist nur eine ganze Zahl.
Was machen wir mit diesem Namen? Wenn Sie sich das Muster ansehen, beginnen alle Namen mit einem Großbuchstaben. Mithilfe regulärer Ausdrücke können wir mit dieser Methode Namen und Altersangaben ermitteln.
Wir können den folgenden Code verwenden
import re
Nameage = '''
Janice is 22 and Theon is 33
Gabriel is 44 and Joey is 21
'''
ages = re.findall(r'd{1,3}', Nameage)
names = re.findall(r'[A-Z][a-z]*',Nameage)
ageDict = {}
x = 0
for eachname in names
ageDict[eachname] = ages[x]
x+=1
print(ageDict)Ausgabe:
{'Janice': '22', 'Theon': '33', 'Gabriel': '44', 'Joey': '21'}Ein paar Beispiele für reguläre Ausdrücke:
Schauen wir uns zunächst an, wie man ein bestimmtes Wort in einer Zeichenfolge findet
Ein Wort in einer Zeichenfolge finden
import re
if re.search("inform","we need to inform him with the latest information"):
print("There is inform")Alles, was wir hier tun, ist zu suchen, ob das Wort „inform“ in unserer Suchzeichenfolge vorhanden ist.
Natürlich können wir auch den folgenden Code optimieren
import re
allinform = re.findall("inform","We need to inform him with the latest information!")
for i in allinform:
print(i)Hier werden in diesem speziellen Fall Informationen doppelt gefunden. Einer kommt von informieren und der andere kommt von Information.
Wie oben gezeigt, ist das Finden von Wörtern in regulären Ausdrücken so einfach.
Als nächstes lernen wir, wie man Iteratoren mithilfe regulärer Ausdrücke generiert.
Iteratoren generieren
import re
Str = "we need to inform him with the latest information"
for i in re.finditer("inform.", Str
locTuple = i.span()
print(locTuple)Für jede gefundene Übereinstimmung werden die Start- und Endindizes gedruckt. Wenn wir das obige Programm ausführen, sieht die Ausgabe wie folgt aus:
(11, 18) (38, 45)
Als Nächstes prüfen wir, wie man mithilfe regulärer Ausdrücke Wörter mit Mustern abgleicht.
考虑一个输入字符串,我们必须将某些单词与该字符串匹配。要详细说明,请查看以下示例代码:
import re
Str = "Sat, hat, mat, pat"
allStr = re.findall("[shmp]at", Str)
for i in allStr:
print(i)字符串中有什么共同点?可以看到字母“a”和“t”在所有输入字符串中都很常见。代码中的 [shmp] 表示要查找的单词的首字母,因此,任何以字母 s、h、m 或 p 开头的子字符串都将被视为匹配,其中任何一个,并且最后必须跟在“at”后面。
Output:
hat mat pat
接下来我们将检查如何使用正则表达式一次匹配一系列字符。
我们希望输出第一个字母应该在 h 和 m 之间并且必须紧跟 at 的所有单词。看看下面的例子,我们应该得到的输出是 hat 和 mat
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[h-m]at", Str)
for i in someStr:
print(i)Output:
hat mat
现在让我们稍微改变一下上面的程序以获得一个不同的结果
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[^h-m]at", Str)
for i in someStr:
print(i)发现细微差别了吗,我们在正则表达式中添加了插入符号 (^),它的作用否定了它所遵循的任何效果。我们不会给出从 h 到 m 开始的所有内容的输出,而是会向我们展示除此之外的所有内容的输出。
我们可以预期的输出是不以 h 和 m 之间的字母开头但最后仍然紧随其后的单词。Output:
sat pat
接下来,我们可以使用正则表达式检查另一个操作,其中我们将字符串中的一项替换为其他内容:
import re
Food = "hat rat mat pat"
regex = re.compile("[r]at")
Food = regex.sub("food", Food)
print(Food)在上面的示例中,单词 rat 被替换为单词 food。正则表达式的替代方法就是利用这种情况,它也有各种各样的实际用例。Output:
hat food mat pat
import re randstr = "Here is Edureka" print(randstr)
Output:
Here is Edureka
这就是反斜杠问题,其中一个斜线从输出中消失了,这个特殊问题可以使用正则表达式来解决。
import re randstr = "Here is Edureka" print(re.search(r"Edureka", randstr))
Output:
<re.Match object; span=(8, 16), match='Edureka'>
这就是使用正则表达式解决反斜杠问题的简单方法。
使用正则表达式可以轻松地单独匹配字符串中的单个字符
import re
randstr = "12345"
print("Matches: ", len(re.findall("d{5}", randstr)))Output:
Matches: 1
我们可以在 Python 中使用正则表达式轻松删除换行符
import re
randstr = '''
You Never
Walk Alone
Liverpool FC
'''
print(randstr)
regex = re.compile("
")
randstr = regex.sub(" ", randstr)
print(randstr)Output:
You Never Walk Alone Liverpool FC You Never Walk Alone Liverpool FC
可以从上面的输出中看到,新行已被空格替换,并且输出打印在一行上。
还可以使用许多其他东西,具体取决于要替换字符串的内容
: Backspace : Formfeed : Carriage Return : Tab : Vertical Tab
可以使用如下代码
import re
randstr = "12345"
print("Matches:", len(re.findall("d", randstr)))Output:
Matches: 5
从上面的输出可以看出,d 匹配字符串中存在的整数。但是,如果我们用 D 替换它,它将匹配除整数之外的所有内容,与 d 完全相反。
接下来我们了解一些在 Python 中使用正则表达式的重要实际例子。
我们将检查使用最为广泛的 3 个主要用例
需要在任何相关场景中轻松验证电话号码
考虑以下电话号码:
电话号码的一般格式如下:
我们将在下面的示例中使用 w,请注意 w = [a-zA-Z0-9_]
import re
phn = "412-555-1212"
if re.search("w{3}-w{3}-w{4}", phn):
print("Valid phone number")Output:
Valid phone number
在任何情况下验证电子邮件地址的有效性。
考虑以下电子邮件地址示例:
我们只需一眼就可以从无效的邮件 ID 中识别出有效的邮件 ID,但是当我们的程序为我们做这件事时,却并没有那么容易,但是使用正则,就非常简单了。
指导思路,所有电子邮件地址应包括:
import re
email = "ac@aol.com md@.com @seo.com dc@.com"
print("Email Matches: ", len(re.findall("[w._%+-]{1,20}@[w.-]{2,20}.[A-Za-z]{2,3}", email)))Output:
Email Matches: 1
从上面的输出可以看出,我们输入的 4 封电子邮件中有一封有效的邮件。
这基本上证明了使用正则表达式并实际使用它们是多么简单和高效。
从网站上删除所有电话号码以满足需求。
要了解网络抓取,请查看下图:
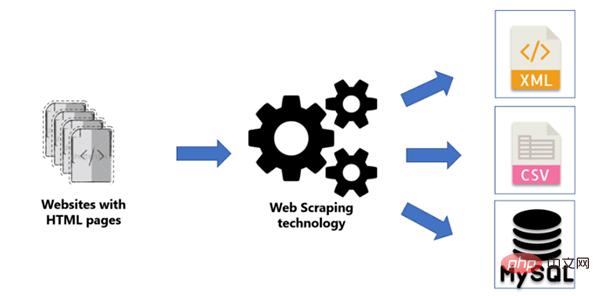
我们已经知道,一个网站将由多个网页组成,我们需要从这些页面中抓取一些信息。
网页抓取主要用于从网站中提取信息,可以将提取的信息以 XML、CSV 甚至 MySQL 数据库的形式保存,这可以通过使用 Python 正则表达式轻松实现。
import urllib.request
from re import findall
url = "http://www.summet.com/dmsi/html/codesamples/addresses.html"
response = urllib.request.urlopen(url)
html = response.read()
htmlStr = html.decode()
pdata = findall("(d{3}) d{3}-d{4}", htmlStr)
for item in pdata:
print(item)Output:
(257) 563-7401 (372) 587-2335 (786) 713-8616 (793) 151-6230 (492) 709-6392 (654) 393-5734 (404) 960-3807 (314) 244-6306 (947) 278-5929 (684) 579-1879 (389) 737-2852 ...
我们首先是通过导入执行网络抓取所需的包,最终结果包括作为使用正则表达式完成网络抓取的结果而提取的电话号码。
Das obige ist der detaillierte Inhalt vonIch habe mehrere reguläre Python-Ausdrücke zusammengestellt und Sie können sie sofort verwenden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



