



Hallo zusammen! Ich bin Bruder Tiger.
Als Datenanalysten müssen wir häufig statistische Analysediagramme erstellen. Aber wenn es zu viele Berichte gibt, nehmen wir oft die meiste Zeit in Anspruch, sie zu erstellen. Dies hat uns davon abgehalten, viel Zeit für die Datenanalyse aufzuwenden. Aber als Datenanalysten sollten wir unser Bestes geben, um die relevanten Informationen herauszufinden, die sich hinter den Daten in Tabellen und Diagrammen verbergen, anstatt einfach nur statistische Tabellen und Diagramme zu erstellen und dann Berichte zu versenden.
Automatisierung kann immer Zeit sparen und unsere Arbeitseffizienz verbessern. Lassen Sie unsere Programmierung die Kopplung jedes Funktionsimplementierungscodes so weit wie möglich reduzieren und den Code besser verwalten. Dadurch sparen wir viel Zeit und können uns auf wertvollere und sinnvollere Arbeiten konzentrieren.
Wenn der Codierungseffekt korrekt ist, kann er für immer verwendet werden. Wenn er manuell durchgeführt wird, können einige Fehler gemacht werden. Es ist beruhigender, es einem festen Programm zu überlassen. Wenn sich die Anforderungen ändern, kann nur ein Teil des Codes geändert werden, um das Problem zu lösen.
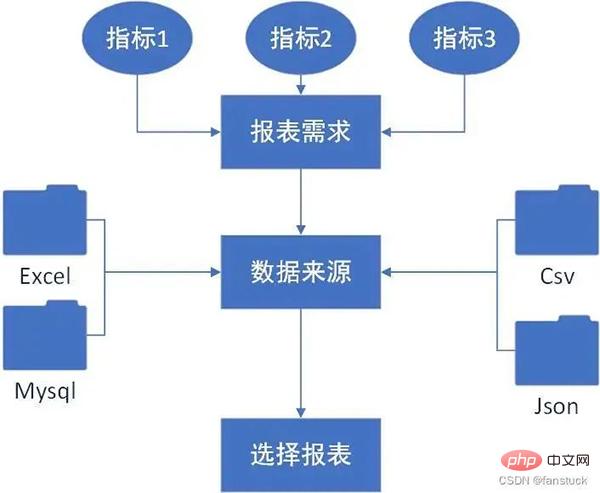
Zunächst müssen wir die von uns benötigten Berichte entsprechend den Geschäftsanforderungen formulieren. Einige komplexe sekundäre Entwicklungsindikatordaten erfordern eine automatisierte Programmierung. , und es können verschiedene Fehler versteckt sein. Daher müssen wir die Merkmale der Berichte, die wir in unserer Arbeit verwenden, zusammenfassen. Die folgenden Aspekte müssen wir umfassend berücksichtigen:
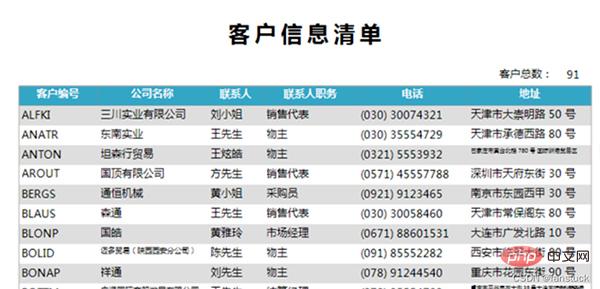
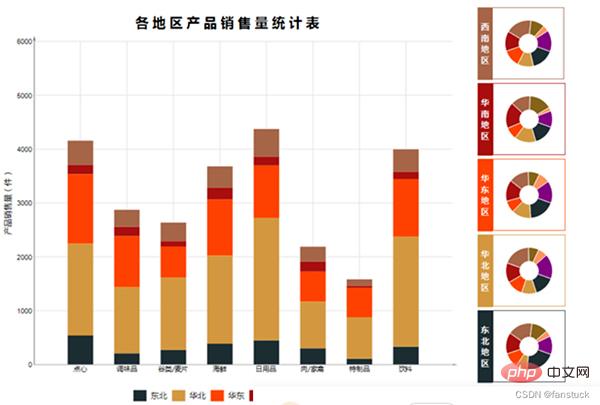 Es ist notwendig, diese häufig verwendeten Berichte zu automatisieren. Für Berichte, die gelegentlich verwendet werden müssen, für sekundäre Entwicklungsindikatoren oder für Berichte, die Statistiken kopieren müssen, besteht keine Notwendigkeit, diese Berichte zu automatisieren.
Es ist notwendig, diese häufig verwendeten Berichte zu automatisieren. Für Berichte, die gelegentlich verwendet werden müssen, für sekundäre Entwicklungsindikatoren oder für Berichte, die Statistiken kopieren müssen, besteht keine Notwendigkeit, diese Berichte zu automatisieren.
2. Entwicklungszeit
3. Prozess
Vergleich von Indikatoren zu einem gemeinsamen Zeitpunkt in benachbarten Zeiträumen
Zentraler Tendenzindikatorimport pandas as pd
import json
import pymysql
from sqlalchemy import create_engine
# 打开数据库连接
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='xxxx',
charset = 'utf8'
)
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
def read_excel(file):
df_excel=pd.read_excel(file)
return df_excel
def read_json(file):
with open(file,'r')as json_f:
df_json=pd.read_json(json_f)
return df_json
def read_sql(table):
sql_cmd ='SELECT * FROM %s'%table
df_sql=pd.read_sql(sql_cmd,engine)
return df_sql
def read_csv(file):
df_csv=pd.read_csv(file)
return df_csv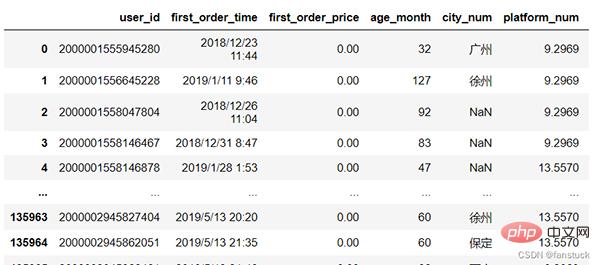
我们需要统计的指标为:
#将城市空值的一行删除 df=df[df['city_num'].notna()] #删除error df=df.drop(df[df['city_num']=='error'].index) #统计df = df.city_num.value_counts()

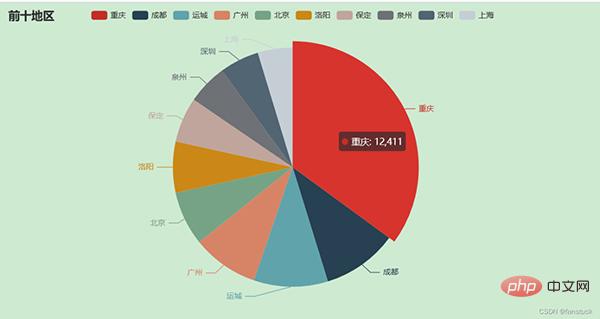
我们仅获取前10名的城市就好了,封装为饼图:
def pie_chart(df):
#将城市空值的一行删除
df=df[df['city_num'].notna()]
#删除error
df=df.drop(df[df['city_num']=='error'].index)
#统计
df = df.city_num.value_counts()
df.head(10).plot.pie(subplots=True,figsize=(5, 6),autopct='%.2f%%',radius = 1.2,startangle = 250,legend=False)
pie_chart(read_csv('user_info.csv'))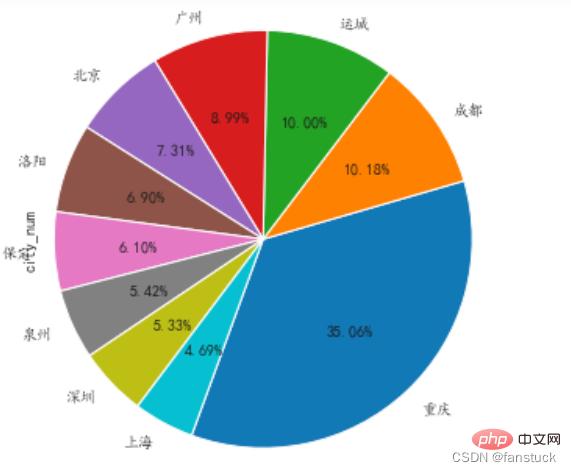
将图表保存起来:
plt.savefig('fig_cat.png')要是你觉得matplotlib的图片不太美观的话,你也可以换成echarts的图片,会更加好看一些:
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
pie.render_notebook()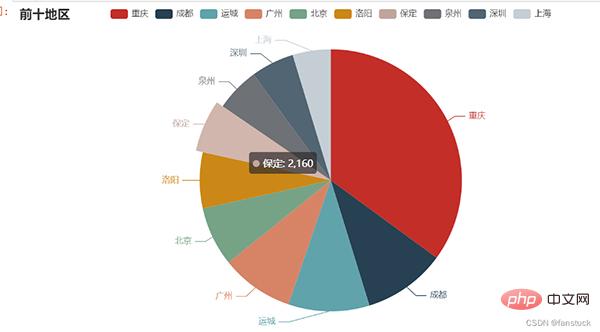
封装后就可以直接使用了:
def echart_pie(user_df):
user_df=user_df[user_df['city_num'].notna()]
user_df=user_df.drop(user_df[user_df['city_num']=='error'].index)
user_df = user_df.city_num.value_counts()
name=user_df.head(10).index.tolist()
value=user_df.head(10).values.tolist()
words=list(zip(list(name),list(value)))
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
return pie.render_notebook()
user_df=read_csv('user_info.csv')
echart_pie(user_df)可以进行保存,可惜不是动图:
from snapshot_selenium import snapshot make_snapshot(snapshot,echart_pie(user_df).render(),"test.png")
保存为网页的形式就可以自动加载JS进行渲染了:
echart_pie(user_df).render('problem.html')
os.system('problem.html')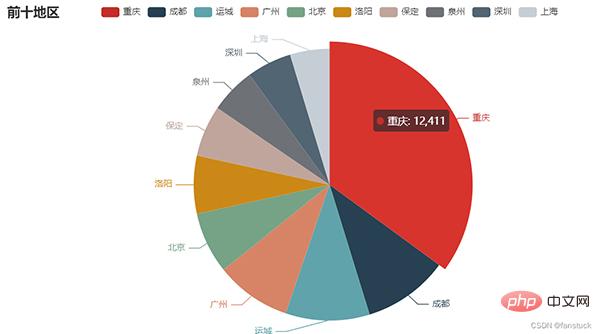
做出来的一系列报表一般都要发给别人看的,对于一些每天需要发送到指定邮箱或者需要发送多封报表的可以使用Python来自动发送邮箱。
在Python发送邮件主要借助到smtplib和email这个两个模块。
不同种类的邮箱服务器连接地址不一样,大家根据自己平常使用的邮箱设置相应的服务器进行连接。这里博主用网易邮箱展示:
首先需要开启POP3/SMTP/IMAP服务:
之后便可以根据授权码使用python登入了。
import smtplib
from email import encoders
from email.header import Header
from email.utils import parseaddr,formataddr
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
#发件人邮箱
asender="fanstuck@163.com"
#收件人邮箱
areceiver="1079944650@qq.com"
#抄送人邮箱
acc="fanstuck@163.com"
#邮箱主题
asubject="谢谢关注"
#发件人地址
from_addr="fanstuck@163.com"
#邮箱授权码
password="####"
#邮件设置
msg=MIMEMultipart()
msg['Subject']=asubject
msg['to']=areceiver
msg['Cc']=acc
msg['from']="fanstuck"
#邮件正文
body="你好,欢迎关注fanstuck,您的关注就是我继续创作的动力!"
msg.attach(MIMEText(body,'plain','utf-8'))
#添加附件
htmlFile = 'C:/Users/10799/problem.html'
html = MIMEApplication(open(htmlFile , 'rb').read())
html.add_header('Content-Disposition', 'attachment', filename='html')
msg.attach(html)
#设置邮箱服务器地址和接口
smtp_server="smtp.163.com"
server = smtplib.SMTP(smtp_server,25)
server.set_debuglevel(1)
#登录邮箱
server.login(from_addr,password)
#发生邮箱
server.sendmail(from_addr,areceiver.split(',')+acc.split(','),msg.as_string())
#断开服务器连接
server.quit()运行测试:
下载文件:
完全没问题!!!
Das obige ist der detaillierte Inhalt vonAutomatisiertes Python-Office-Applet: Implementieren Sie die Berichtsautomatisierung und senden Sie sie automatisch an das Zielpostfach. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



