


Übersetzer | Li Rui Rezensent | Bedrohungen für die Privatsphäre.
Die Sicherheitsbedrohungen, denen verschiedene Paradigmen des maschinellen Lernens ausgesetzt sind, variieren jedoch, und einige Bereiche der Sicherheit des maschinellen Lernens sind nach wie vor unzureichend erforscht. Insbesondere der Sicherheit von Reinforcement-Learning-Algorithmen wurde in den letzten Jahren wenig Aufmerksamkeit geschenkt.
Forscher der kanadischen McGill University, des Machine Learning Laboratory (MILA) und der University of Waterloo führten eine neue Studie durch, die sich auf die Datenschutzbedrohungen von Deep-Reinforcement-Learning-Algorithmen konzentrierte. Forscher schlagen einen Rahmen zum Testen der Anfälligkeit von Reinforcement-Learning-Modellen für Membership-Inference-Angriffe vor.
Forschungsergebnisse zeigen, dass Angreifer Deep Reinforcement Learning (RL)-Systeme effektiv angreifen und möglicherweise vertrauliche Informationen erhalten, die zum Trainieren von Modellen verwendet werden. Ihre Ergebnisse sind von Bedeutung, da Techniken des verstärkenden Lernens nun Einzug in Industrie- und Verbraucheranwendungen halten.
Membership Inference AttackMembership Inference Attack beobachtet das Verhalten eines Zielmodells für maschinelles Lernen und sagt die Beispiele voraus, die zum Trainieren des Modells verwendet werden.
Jedes Modell für maschinelles Lernen wird anhand einer Reihe von Beispielen trainiert. In einigen Fällen umfassen Schulungsbeispiele vertrauliche Informationen wie Gesundheits- oder Finanzdaten oder andere persönlich identifizierbare Informationen.
Member-Inferenzangriffe sind eine Reihe von Techniken, die versuchen, ein maschinelles Lernmodell dazu zu zwingen, seine Trainingssatzdaten preiszugeben. Während sich kontradiktorische Beispiele (die bekanntere Art von Angriffen gegen maschinelles Lernen) auf die Änderung des Verhaltens von Modellen für maschinelles Lernen konzentrieren und als Sicherheitsbedrohung gelten, konzentrieren sich Mitgliedschaftsinferenzangriffe auf das Extrahieren von Informationen aus dem Modell und stellen eher eine Bedrohung für die Privatsphäre dar.
Membership-Inference-Angriffe wurden in überwachten maschinellen Lernalgorithmen gut untersucht, bei denen Modelle anhand gekennzeichneter Beispiele trainiert werden.
Im Gegensatz zum überwachten Lernen verwenden Deep-Reinforcement-Learning-Systeme keine gekennzeichneten Beispiele. Ein Reinforcement Learning (RL)-Agent erhält Belohnungen oder Strafen für seine Interaktionen mit der Umgebung. Durch diese Interaktionen und Verstärkungssignale lernt es nach und nach und entwickelt sein Verhalten weiter.
Die Autoren des Papiers sagten in schriftlichen Kommentaren: „Belohnungen beim verstärkenden Lernen stellen nicht unbedingt Etiketten dar; daher können sie nicht als prädiktive Etiketten dienen, die häufig bei der Gestaltung von Mitgliedschaftsinferenzangriffen in anderen Lernparadigmen verwendet werden.“ Forschung „Derzeit gibt es keine Studien zum potenziellen Verlust von Daten, die direkt zum Trainieren von Deep-Reinforcement-Learning-Agenten verwendet werden“, schreiben die Forscher in ihrem Artikel
Und ein Grund für diesen Mangel an Forschung ist das Reinforcement-Learning ist in der realen Welt weniger effizient. Die Anwendungen sind begrenzt.
Die Autoren des Forschungspapiers sagen: „Trotz erheblicher Fortschritte im Bereich des Deep Reinforcement Learning, wie Alpha Go, Alpha Fold und GT Sophy, werden Deep Reinforcement Learning-Modelle im industriellen Maßstab immer noch nicht weit verbreitet.“ Andererseits ist der Datenschutz ein sehr weit verbreitetes Forschungsgebiet. Das Fehlen tiefgreifender Reinforcement-Learning-Modelle in tatsächlichen industriellen Anwendungen hat die Forschung in diesem grundlegenden und wichtigen Forschungsgebiet stark verzögert, was zu einer unzureichenden Forschung zu Angriffen auf Reinforcement-Learning-Systeme geführt hat.
Mit der wachsenden Notwendigkeit, Reinforcement-Learning-Algorithmen im industriellen Maßstab in realen Szenarien anzuwenden, werden der Fokus und die strengen Anforderungen an Frameworks, die die Datenschutzaspekte von Reinforcement-Learning-Algorithmen aus einer kontradiktorischen und algorithmischen Perspektive berücksichtigen, immer deutlicher relevant.
Herausforderungen der Mitgliedschaftsinferenz beim Deep Reinforcement Learning
Die Autoren des Forschungspapiers sagten: „Unsere Bemühungen bei der Entwicklung der ersten Generation von datenschutzerhaltenden Deep Reinforcement Learning-Algorithmen haben uns dazu geführt, dass wir dies aus der Privatsphäre heraus erkannt haben Aus einer Perspektive gibt es grundlegende strukturelle Unterschiede zwischen herkömmlichen Algorithmen für maschinelles Lernen und Algorithmen für verstärkendes Lernen.“ Die Forscher stellten vor allem fest, dass die grundlegenden Unterschiede zwischen Deep Reinforcement Learning und anderen Lernparadigmen angesichts der möglichen Konsequenzen für den Datenschutz ernsthafte Herausforderungen bei der Bereitstellung von Deep Reinforcement Learning-Modellen für praktische Anwendungen darstellen. Sie sagten: „Basierend auf diesem Verständnis ist die größte Frage für uns: Wie anfällig sind Deep-Reinforcement-Learning-Algorithmen für Datenschutzangriffe wie Mitgliedschaftsinferenzangriffe? Bestehende Angriffsmodelle für Mitgliedschaftsinferenzangriffe sind speziell für andere Lernparadigmen konzipiert.“ Die Anfälligkeit von Deep-Reinforcement-Learning-Algorithmen für solche Angriffe ist angesichts der schwerwiegenden Auswirkungen auf die Privatsphäre bei ihrem Einsatz auf der ganzen Welt weitgehend unbekannt. Die Notwendigkeit, das Bewusstsein in Forschung und Industrie zu schärfen, war die Hauptmotivation für diese Studie , durchläuft ein Reinforcement-Learning-Modell mehrere Phasen, die jeweils aus einer Trajektorie oder Abfolge von Aktionen und Zuständen bestehen. Daher muss ein erfolgreicher Membership-Inference-Angriffsalgorithmus für Reinforcement Learning die Datenpunkte und Trajektorien lernen, die zum Trainieren des Modells verwendet werden. Dies macht es einerseits schwieriger, Mitgliedschaftsinferenzalgorithmen für Reinforcement-Learning-Systeme zu entwerfen, andererseits erschwert es auch die Bewertung der Robustheit von Reinforcement-Learning-Modellen gegenüber solchen Angriffen. Die Autoren sagen: „Membership Inference Attacks (MIA) sind im Vergleich zu anderen Arten des maschinellen Lernens aufgrund der sequentiellen und zeitabhängigen Natur der beim Training und Vorhersagen verwendeten Datenpunkte schwierig.“ -Viele Beziehungen zwischen Datenpunkten unterscheiden sich grundlegend von anderen Lernparadigmen. Der grundlegende Unterschied zwischen Reinforcement Learning und anderen Machine-Learning-Paradigmen macht es schwierig, Mitgliedschaftsinferenzangriffe für Deep Reinforcement Learning zu entwerfen und zu bewerten. Es ist wichtig, neu zu denken Wege. Entwerfen von Mitgliedschaftsinferenzangriffen gegen Reinforcement-Learning-Systeme Nicht-richtlinienbasiertes Verstärkungslernen ist besonders wichtig für viele reale Anwendungen, bei denen Trainingsdaten bereits vorhanden sind und dem maschinellen Lernteam bereitgestellt werden, das das Verstärkungslernmodell trainiert. Nicht-richtlinienbasiertes Verstärkungslernen ist auch für die Erstellung von Mitgliedschaftsinferenz-Angriffsmodellen von entscheidender Bedeutung.
Nicht-richtlinienbasiertes Verstärkungslernen verwendet einen „Wiederholungspuffer“, um zuvor gesammelte Daten während des Modelltrainings wiederzuverwenden Die Autoren sagen: „Die Erkundungs- und Nutzungsphasen sind bei einem echten nicht-richtlinienbasierten Verstärkungslernen getrennt Daher hat die Zielstrategie keinen Einfluss auf die Trainingstrajektorien. Diese Einstellung eignet sich besonders beim Entwerfen eines Member-Inference-Angriffs-Frameworks in einer Black-Box-Umgebung, da der Angreifer weder die interne Struktur des Zielmodells noch die verwendete Methode kennt Sammeln Sie die Trainingstrajektorien. Bei einem Black-Box-Mitgliedschaftsinferenzangriff kann der Angreifer nur das Verhalten des trainierten Verstärkungslernmodells beobachten. In diesem speziellen Fall geht der Angreifer davon aus, dass das Zielmodell auf Trajektorien trainiert wurde, die aus einem Satz privater Daten generiert wurden. Auf diese Weise funktioniert nicht-richtlinienbasiertes Reinforcement Learning.
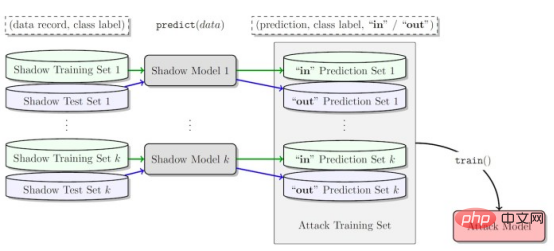
In der Studie entschieden sich die Forscher für „Batch Constrained Deep Q Learning“ (BCQ), einen fortschrittlichen nicht-richtlinienbasierten Verstärkungslernalgorithmus, der eine hervorragende Leistung bei Kontrollaufgaben zeigt. Sie zeigen jedoch, dass ihre Mitgliedschaftsinferenz-Angriffstechnik auf andere nicht-richtlinienbasierte Verstärkungslernmodelle ausgeweitet werden kann. Eine Möglichkeit für Angreifer, Mitgliedschaftsinferenzangriffe durchzuführen, besteht darin, „Schattenmodelle“ zu entwickeln. Hierbei handelt es sich um ein maschinelles Lernmodell für Klassifikatoren, das auf einer Mischung von Daten aus derselben Verteilung wie die Trainingsdaten des Zielmodells und anderswo trainiert wurde. Nach dem Training kann das Schattenmodell zwischen Datenpunkten, die zum Trainingssatz des Zielmodells für maschinelles Lernen gehören, und neuen Daten unterscheiden, die das Modell zuvor noch nicht gesehen hat. Das Erstellen von Schattenmodellen für Reinforcement-Learning-Agenten ist aufgrund der sequentiellen Natur des Zielmodelltrainings schwierig. Dies gelang den Forschern in mehreren Schritten. Zunächst füttern sie den Trainer des Reinforcement-Learning-Modells mit einem neuen Satz nicht-privater Datentrajektorien und beobachten die vom Zielmodell generierten Trajektorien. Der Angriffstrainer verwendet dann die Trainings- und Ausgabetrajektorien, um einen Klassifikator für maschinelles Lernen zu trainieren, um die Eingabetrajektorien zu erkennen, die beim Training des Lernmodells zur Zielverstärkung verwendet werden. Schließlich erhält der Klassifikator neue Trajektorien zur Klassifizierung als Trainingsmitglieder oder neue Datenbeispiele. Trainieren von Schattenmodellen für Membership-Inference-Angriffe gegen Reinforcement-Learning-Modelle Die Forscher testeten ihre Membership-Inference-Angriffe in verschiedenen Modi, einschließlich unterschiedlicher Trajektorienlänge, Single versus mehrere Trajektorien und korrelierte versus dekorrelierte Trajektorien. Die Forscher stellten in ihrer Arbeit fest: „Die Ergebnisse zeigen, dass unser vorgeschlagenes Angriffsframework sehr effektiv bei der Ableitung von Trainingsdatenpunkten für Reinforcement-Learning-Modelle ist … Die erzielten Ergebnisse zeigen, dass beim Einsatz von Deep Reinforcement Learning ein hohes Risiko besteht.“ Datenschutzrisiko.“ Ihre Ergebnisse zeigen, dass Angriffe mit mehreren Flugbahnen effektiver sind als Angriffe mit einer einzigen Flugbahn, und dass die Genauigkeit des Angriffs zunimmt, je länger die Flugbahnen werden und korrelieren. Die Autoren sagen: „Die natürliche Umgebung sind natürlich einzelne Modelle, und der Angreifer ist daran interessiert, die Anwesenheit einer bestimmten Person im Trainingssatz zu identifizieren, der zum Trainieren der Zielverstärkungs-Lernrichtlinie (Festlegen der gesamten Flugbahn in Verstärkung) verwendet wird.“ „Membership Inference Attacks (MIA) im kollektiven Modus zeigen jedoch, dass der Angreifer zusätzlich zur zeitlichen Korrelation, die durch die Merkmale der Trainingsrichtlinie erfasst wird, auch die Kreuzkorrelation zwischen den Trainingstrajektorien der Zielrichtlinie ausnutzen kann“ Studie Dies bedeutet auch, dass Angreifer komplexere Lernarchitekturen und eine ausgefeiltere Hyperparameter-Abstimmung benötigen, um Kreuzkorrelationen zwischen Trainingstrajektorien und zeitlichen Korrelationen innerhalb von Trajektorien auszunutzen, sagten die Forscher. Die Forscher sagten: „Das Verständnis dieser verschiedenen Angriffsmodi kann uns ein tieferes Verständnis der Auswirkungen auf die Datensicherheit und den Datenschutz vermitteln, da es uns ermöglicht, die verschiedenen Blickwinkel, aus denen Angriffe auftreten können, und die Auswirkungen auf den Datenschutz besser zu verstehen.“ Verstöße. Das Ausmaß der Auswirkungen. Die Forscher testeten ihren Angriff an einem Reinforcement-Learning-Modell, das auf drei Aufgaben basierend auf der Open AIGym- und MuJoCo-Physik trainiert wurde Motoren. Die Forscher sagten: „Unsere aktuellen Experimente decken drei hochdimensionale Bewegungsaufgaben ab: Hopper, Half-Cheetah und Ant. Diese Aufgaben sind alles Robotersimulationsaufgaben und fördern hauptsächlich die Ausweitung von Experimenten auf reale Roboterlernaufgaben. Eine weitere spannende Möglichkeit für Anwendungsmitglieder, auf Angriffe zu schließen, sind Konversationssysteme wie Amazon Alexa, Apple Siri und Google Assistant, sagten die Forscher des Papiers. In diesen Anwendungen werden Datenpunkte durch die vollständige Interaktionsverfolgung zwischen dem Chatbot und dem Endbenutzer dargestellt. In dieser Einstellung ist der Chatbot eine trainierte Reinforcement-Learning-Richtlinie, und die Interaktionen des Benutzers mit dem Roboter bilden die Eingabetrajektorie. Die Autoren sagen: „In diesem Fall ist das kollektive Muster die natürliche Umgebung. Mit anderen Worten: Der Angreifer kann daraus schließen, dass sich der Benutzer in dieser Art befindet.“ Der Angriff könnte sich auf Reinforcement-Learning-Systeme auswirken. Sie können auch untersuchen, wie diese Angriffe auf das verstärkende Lernen in anderen Kontexten angewendet werden können. Die Autoren sagen: „Eine interessante Erweiterung dieses Forschungsbereichs besteht darin, Member-Inferenzangriffe gegen Deep-Reinforcement-Learning-Modelle in einer White-Box-Umgebung zu untersuchen, in der dem Angreifer auch die interne Struktur der Zielrichtlinie bekannt ist.“ Die Forscher hoffen, dass ihre Studie Licht auf Sicherheits- und Datenschutzprobleme in realen Reinforcement-Learning-Anwendungen werfen und das Bewusstsein in der Community des maschinellen Lernens schärfen wird, damit mehr Forschung in diesem Bereich durchgeführt werden kann. Originaltitel: Reinforcement-Learning-Modelle sind anfällig für Mitgliedschaftsinferenzangriffe, Autor: Ben Dickson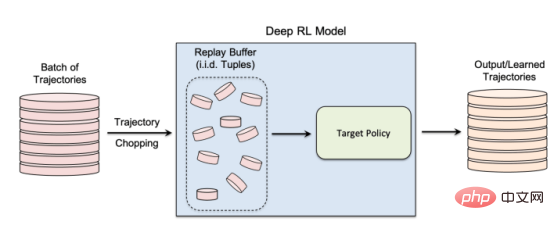
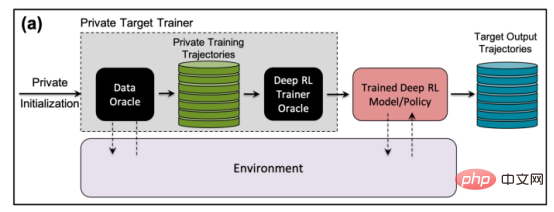
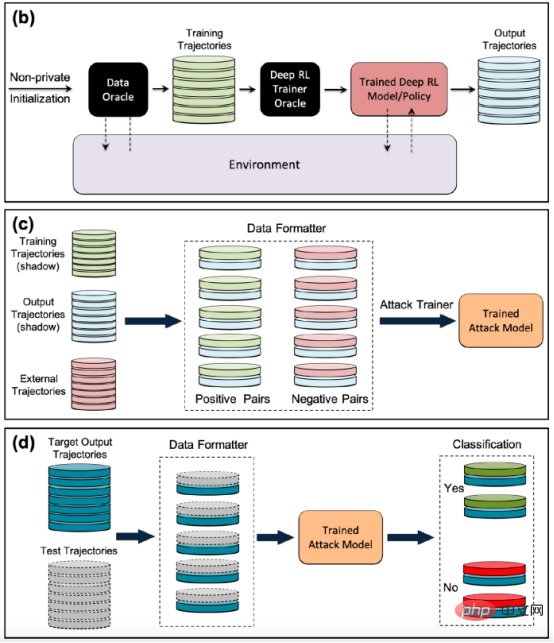
Testen von Membership-Inference-Angriffen gegen Reinforcement-Learning-Systeme
Reale Mitgliedschaftsinferenzangriffe auf Reinforcement-Learning-Systeme
Das obige ist der detaillierte Inhalt vonUntersuchungen zeigen, dass Reinforcement-Learning-Modelle anfällig für Membership-Inference-Angriffe sind. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































