


arXiv-Artikel „Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection“, 22. Juni, Arbeit der University of Science and Technology of China, des Harbin Institute of Technology und SenseTime.

Das Erkennen von 3D-Objekten aus mehreren Bildansichten ist eine grundlegende, aber anspruchsvolle Aufgabe beim visuellen Szenenverständnis. Aufgrund der geringen Kosten und der hohen Effizienz bietet die Multi-View-3D-Objekterkennung breite Anwendungsaussichten. Aufgrund des Mangels an Tiefeninformationen ist es jedoch äußerst schwierig, Objekte perspektivisch im 3D-Raum genau zu erkennen. Kürzlich führte DETR3D ein neues 3D-2D-Abfrageparadigma zur Aggregation von Mehransichtsbildern zur 3D-Objekterkennung ein und erreichte eine Leistung auf dem neuesten Stand der Technik.
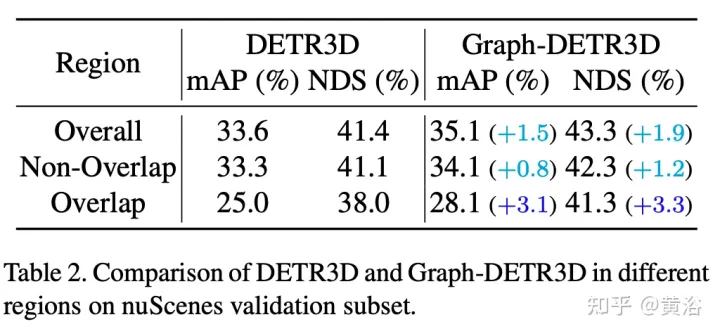
Durch intensive geführte Experimente quantifiziert dieser Artikel Ziele in verschiedenen Bereichen und stellt fest, dass „abgeschnittene Instanzen“ (d. h. die Grenzbereiche jedes Bildes) der Hauptengpass sind, der die Leistung von DETR3D beeinträchtigt. Trotz der Zusammenführung mehrerer Features aus zwei benachbarten Ansichten in überlappenden Regionen leidet DETR3D immer noch unter einer unzureichenden Feature-Aggregation und verpasst daher die Gelegenheit, die Erkennungsleistung vollständig zu verbessern.
Um dieses Problem zu lösen, wird Graph-DETR3D vorgeschlagen, um Bildinformationen mit mehreren Ansichten durch Graph Structure Learning (GSL) automatisch zu aggregieren. Zwischen jeder Zielabfrage und der 2D-Feature-Map wird eine dynamische 3D-Karte erstellt, um die Zieldarstellung, insbesondere in Grenzregionen, zu verbessern. Darüber hinaus profitiert Graph-DETR3D von einer neuen tiefeninvarianten Multiskalen-Trainingsstrategie, die die visuelle Tiefenkonsistenz durch gleichzeitige Skalierung der Bildgröße und der Zieltiefe aufrechterhält.
Graph-DETR3D unterscheidet sich in zwei Punkten, wie in der Abbildung gezeigt: (1) Aggregationsmodul dynamischer Diagrammfunktionen (2) tiefeninvariante Multiskalen-Trainingsstrategie. Es folgt der Grundstruktur von DETR3D und besteht aus drei Komponenten: Bild-Encoder, Transformator-Decoder und Zielvorhersagekopf. Bei einer Reihe von Bildern I = {I1, I2,…,IK} (aufgenommen von N Peri-View-Kameras) zielt Graph-DETR3D darauf ab, den Ort und die Kategorie des interessierenden Begrenzungsrahmens vorherzusagen. Verwenden Sie zunächst einen Bildencoder (einschließlich ResNet und FPN), um diese Bilder in einen Satz relativ L-Feature-Map-Level-Features F umzuwandeln. Anschließend wird ein dynamischer 3D-Graph erstellt, um 2D-Informationen über das DGFA-Modul (Dynamic Graph Feature Aggregation) umfassend zu aggregieren und so die Darstellung der Zielabfrage zu optimieren. Schließlich wird die erweiterte Zielabfrage verwendet, um die endgültige Vorhersage auszugeben.
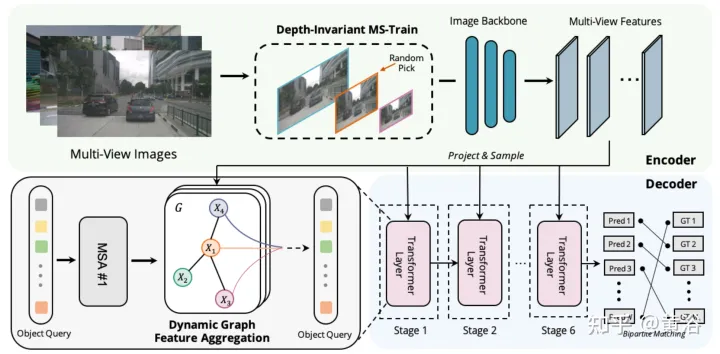
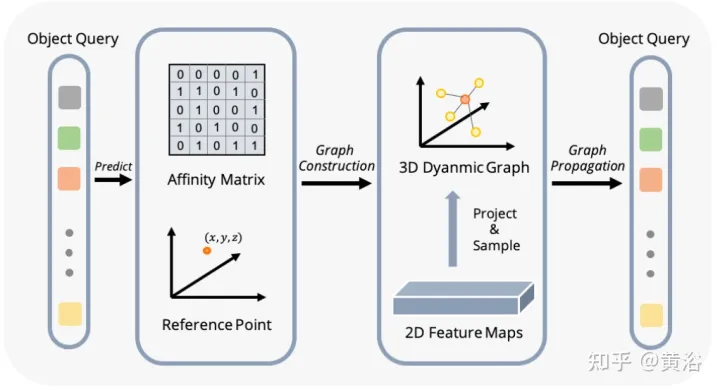
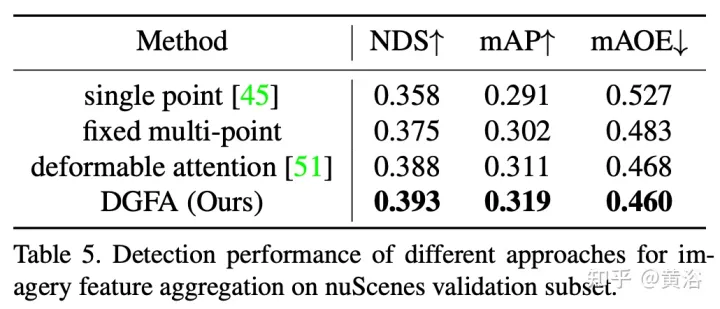
Die Abbildung zeigt den DFGA-Prozess (Dynamic Graph Feature Aggregation): Erstellen Sie zunächst ein lernbares 3D-Diagramm für jede Zielabfrage und probieren Sie dann Features aus der 2D-Bildebene aus. Schließlich wird die Darstellung der Zielabfrage durch Diagrammverbindungen verbessert. Dieses vernetzte Nachrichtenverbreitungsschema unterstützt die iterative Verfeinerung der Strukturkonstruktion des Graphen und die Funktionserweiterung.
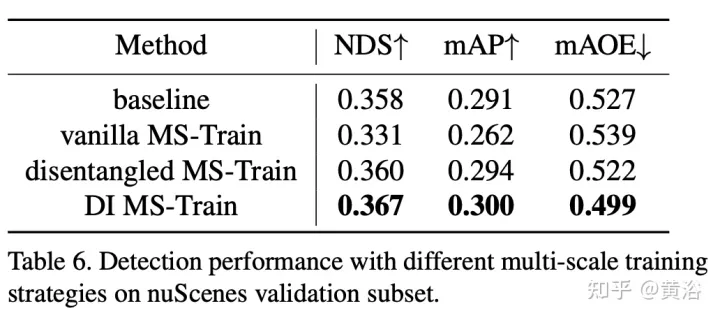
Multiskalentraining ist eine häufig verwendete Datenerweiterungsstrategie bei 2D- und 3D-Objekterkennungsaufgaben, die sich als effektive und kostengünstige Inferenz erwiesen hat. Bei visionsbasierten 3D-Inspektionsmethoden kommt es jedoch selten vor. Die Berücksichtigung unterschiedlicher Eingabebildgrößen kann die Robustheit des Modells verbessern, während gleichzeitig die Bildgröße angepasst und die internen Parameter der Kamera geändert werden, um eine gemeinsame Trainingsstrategie mit mehreren Maßstäben zu implementieren.
Ein interessantes Phänomen ist, dass die Endleistung stark abnimmt. Durch sorgfältige Analyse der Eingabedaten haben wir herausgefunden, dass eine einfache Neuskalierung des Bildes zu einem Problem der perspektivischen Mehrdeutigkeit führt: Wenn die Größe des Ziels auf einen größeren/kleineren Maßstab geändert wird, werden seine absoluten Eigenschaften (d. h. die Größe des Ziels, die Entfernung zum Ego) verändert Punkt) nicht ändern.
Als konkretes Beispiel zeigt die Abbildung dieses mehrdeutige Problem: Obwohl die absolute 3D-Position des ausgewählten Bereichs in (a) und (b) gleich ist, ist die Anzahl der Bildpixel unterschiedlich. Tiefenvorhersagenetzwerke neigen dazu, die Tiefe basierend auf dem eingenommenen Bereich des Bildes zu schätzen. Daher kann dieses Trainingsmuster in der Abbildung das Tiefenvorhersagemodell verwirren und die endgültige Leistung weiter verschlechtern.

Berechnen Sie hierfür die Tiefe aus Pixelperspektive neu. Der Pseudocode des Algorithmus lautet wie folgt:

Das Folgende ist die Dekodierungsoperation:

Die neu berechnete Pixelgröße lautet:
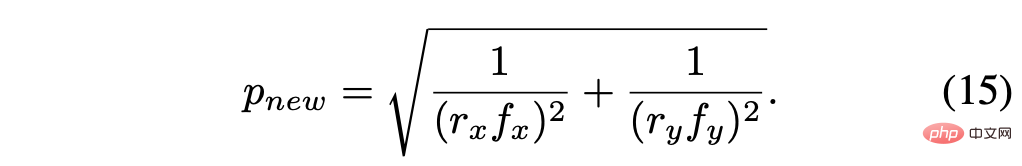
Unter der Annahme des Skalierungsfaktors r = rx = ry, vereinfacht Ergebnis ist:
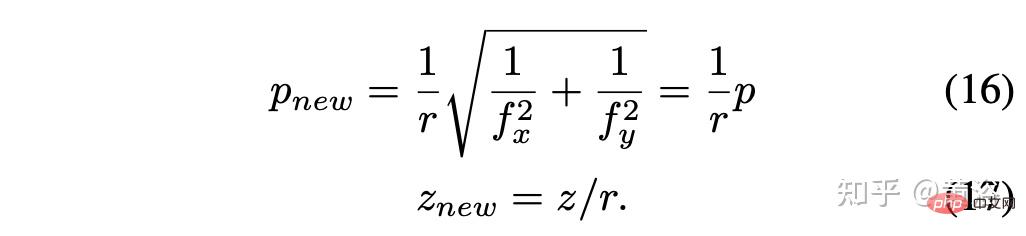
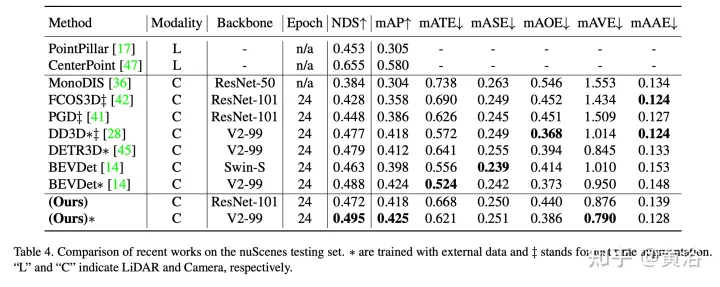
Die experimentellen Ergebnisse sind wie folgt:
 #🎜🎜 ##🎜 🎜#
#🎜🎜 ##🎜 🎜#
 Hinweis: DI = Tiefeninvariant
Hinweis: DI = Tiefeninvariant
Das obige ist der detaillierte Inhalt vonGraph-DETR3D: Überlappende Bereiche bei der 3D-Objekterkennung mit mehreren Ansichten überdenken. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Beliebte Fernverbindungssoftware
Beliebte Fernverbindungssoftware
 Einführung in Screenshot-Tastenkombinationen im Windows 7-System
Einführung in Screenshot-Tastenkombinationen im Windows 7-System
 Grenzradius
Grenzradius
 CAD-Zeilenbruchbefehl
CAD-Zeilenbruchbefehl
 So stellen Sie Chinesisch in vscode ein
So stellen Sie Chinesisch in vscode ein
 Die Direct3D-Funktion ist nicht verfügbar
Die Direct3D-Funktion ist nicht verfügbar
 Lösung dafür, dass Google Chrome nicht funktioniert
Lösung dafür, dass Google Chrome nicht funktioniert












