



Gast: Lu Mian
Zusammengestellt von: Mo Se
Am 6. und 7. August 2022 findet wie geplant die AISummit Global Artificial Intelligence Technology Conference statt. Bei dem Treffen hielt Lu Mian, 4Paradigm-Systemarchitekt und Leiter der OpenMLDB-Forschung und -Entwicklung, eine Grundsatzrede mit dem Titel „Open-Source-Datenbank für maschinelles Lernen OpenMLDB: Eine konsistente Online- und Offline-Feature-Plattform auf Produktionsebene“, in der er sich auf die Daten- und Feature-Herausforderungen künstlicher Intelligenz konzentrierte Intelligence Engineering-Implementierung, OpenMLDBs Feature-Berechnungsplattform auf Produktionsebene, die online und offline konsistent ist, OpenMLDB v0.5: Leistungs-, Kosten- und Benutzerfreundlichkeitsverbesserungen wurden in drei Aspekten geteilt.
Der Inhalt der Rede ist nun wie folgt aufgebaut, ich hoffe, er kann Sie inspirieren.
Heute werden laut Statistik 95 % der Zeit bei der Implementierung künstlicher Intelligenz für Daten aufgewendet. Obwohl es verschiedene Datentools wie MySQL auf dem Markt gibt, sind sie weit davon entfernt, das Problem der Implementierung künstlicher Intelligenz zu lösen. Schauen wir uns also zunächst die Datenprobleme an.
Wenn Sie an der Entwicklung von Anwendungen für maschinelles Lernen mitgewirkt haben, sollten Sie von MLOps tief beeindruckt sein, wie in der folgenden Abbildung dargestellt:
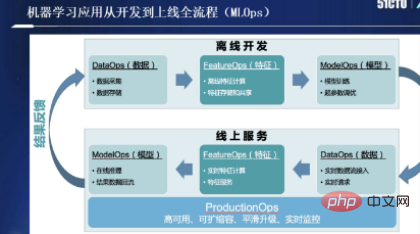
Tatsächlich gibt es derzeit keine strenge akademische Definition von MLOps, und das ist der Fall unterteilt werden in Offline-Entwicklung als Ganzes und Online-Service zwei Prozesse. Der Informationsträger in jedem Prozess, von Daten über Funktionen bis hin zu Modellen, durchläuft drei verschiedene Träger, vom Offline-Entwicklungsprozess bis zum Online-Service-Prozess.
Als nächstes konzentrieren wir uns auf den Zwischenfunktionsprozess, um zu verstehen, wie die Herausforderungen gelöst werden können.
Bei der Entwicklung künstlicher Intelligenz gibt es hauptsächlich zwei Anwendungskategorien: Die eine ist die bekannte Gesichtserkennung und andere KI-Anwendungen sind die Wahrnehmung Grundsätzlich basiert es auf dem DNN-Algorithmus. Der andere Typ sind entscheidungsrelevante KI-Szenarien, beispielsweise personalisierte Empfehlungen für Taobao-Einkäufe. Darüber hinaus gibt es einige Szenarien wie Risikokontrollszenarien und Betrugsbekämpfungsszenarien, in denen KI in großem Umfang bei der Entscheidungsfindung eingesetzt wird.
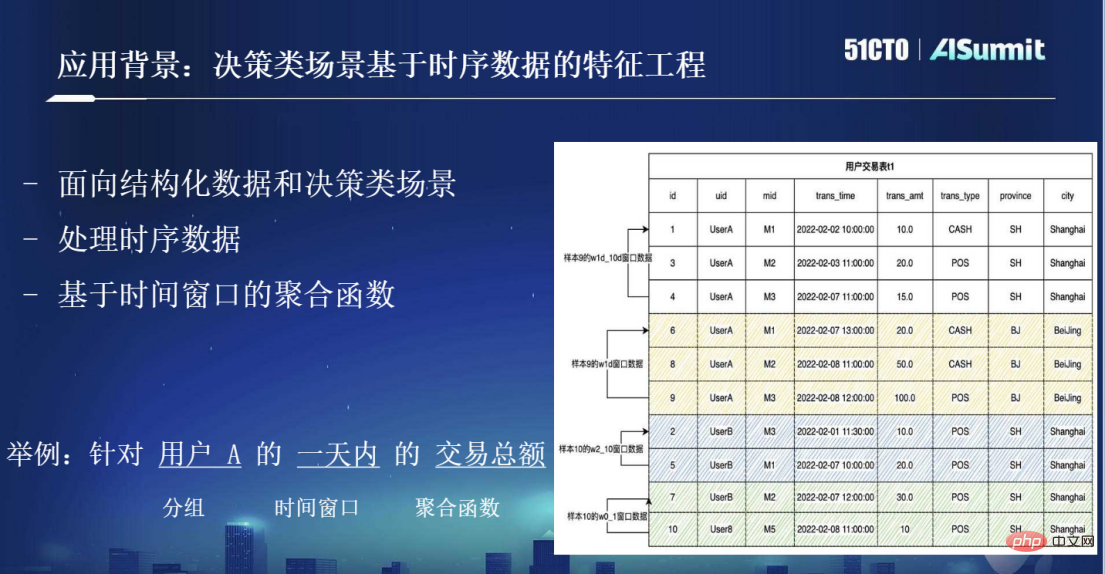
Der Anwendungshintergrund, über den wir jetzt sprechen, betrifft daher hauptsächlich diese Art von Entscheidungsszenario. Eines der größten Merkmale besteht darin, dass es sich bei den Daten um strukturierte Daten in einer zweidimensionalen Tabelle und auch um Zeitreihendaten handelt. Wie in der folgenden Abbildung dargestellt, gibt es in der Benutzertransaktionstabelle eine „trans_time“, die den Zeitpunkt darstellt, zu dem jeder Datensatz auftritt. Bei der Verbindung handelt es sich um Zeitreihendaten. Eine der gebräuchlichsten Verarbeitungsmethoden für das Feature Engineering basierend auf Zeitreihendaten ist die Aggregationsfunktion basierend auf Zeitfenstern. Beispielsweise das Zielen auf den Gesamttransaktionsbetrag eines Benutzers an einem Tag usw. Dies ist ein häufiger Vorgang des Feature Engineering in Entscheidungsszenarien.
Warum sollten wir nun OpenMLDB verwenden? Ein sehr wichtiger Hintergrund ist der Einsatz von wirklich hartem Echtzeit-Computing zur Erfüllung der KI-Anforderungen.
Was ist hartes Echtzeitrechnen? Es hat zwei Bedeutungen: Die eine bezieht sich auf die Verwendung der aktuellsten Echtzeitdaten, um den größten geschäftlichen Entscheidungseffekt zu erzielen. Sie müssen beispielsweise das Klickverhalten des Benutzers in den letzten 10 Sekunden oder 1 Minute verwenden, um Geschäftsentscheidungen zu treffen, und nicht die Daten aus dem vergangenen Jahr oder dem Vorjahr.
Ein weiterer sehr wichtiger Punkt ist, dass für Echtzeitberechnungen die Funktionsberechnung in kurzer Zeit oder sogar auf Millisekundenebene durchgeführt werden muss, sobald der Benutzer eine Verhaltensanforderung stellt.
Es gibt derzeit viele Produkte für Batch Computing/Streaming Computing auf dem Markt, aber sie haben noch nicht die Anforderungen an hartes Echtzeit-Computing im Millisekundenbereich erreicht.
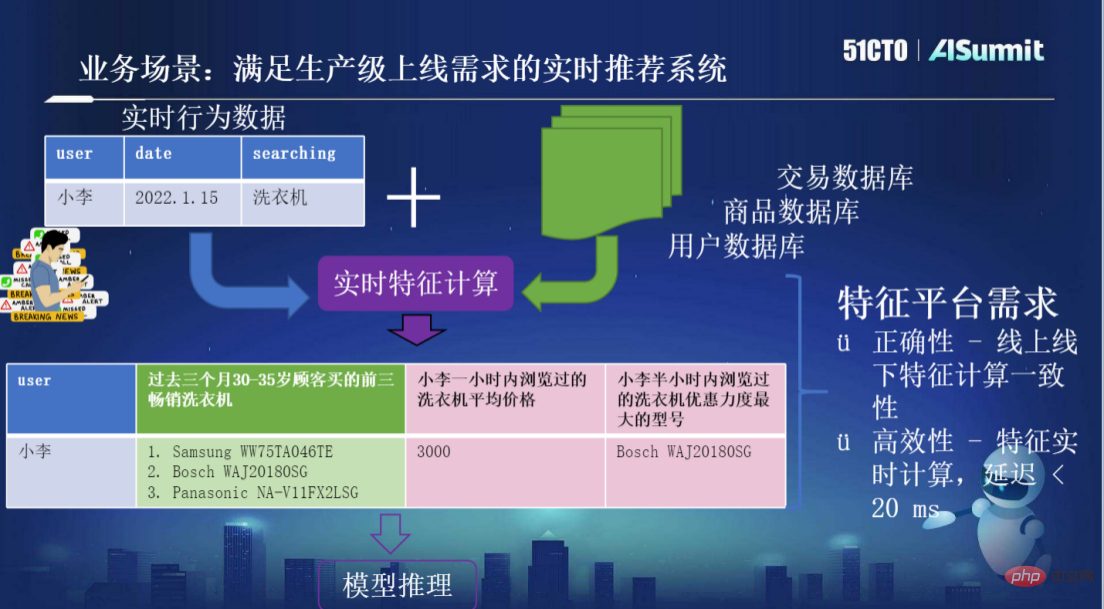
Um beispielsweise ein Echtzeit-Empfehlungssystem zu erstellen, das die Online-Anforderungen auf Produktionsebene erfüllt, führt der Benutzer Xiao Li beispielsweise eine Suche mit dem Schlüsselwort „Waschmaschine“ durch. Er muss auch die ursprünglichen Anforderungsdaten eingeben B. Benutzer-, Produkt-, Transaktions- und andere Informationen im System. Die Daten werden für die Echtzeit-Feature-Berechnung kombiniert und anschließend einige aussagekräftigere Features generiert. Dies ist das sogenannte Feature-Engineering, der Prozess der Generierung von Features. Das System generiert beispielsweise „die drei meistverkauften Waschmaschinen, die in den letzten drei Monaten von Kunden einer bestimmten Altersgruppe gekauft wurden“. Diese Art von Funktion erfordert keine hohe Aktualität und wird auf der Grundlage längerer historischer Daten berechnet. Allerdings benötigt das System möglicherweise auch einige sehr zeitkritische Daten, wie z. B. „Browsing-Datensätze innerhalb der letzten Stunde/halben Stunde“ usw. Nachdem das System die neu berechneten Merkmale erhalten hat, stellt es das Modell für die Schlussfolgerung bereit. Es gibt zwei Hauptanforderungen an eine solche System-Feature-Plattform: Die eine ist die Korrektheit, das heißt die Konsistenz der Online- und Offline-Feature-Berechnungen, die andere ist die Effizienz, das heißt die Echtzeit-Feature-Berechnung und die Verzögerung der Features Berechnungsentwicklung bis zum Online-Volllebenszyklus
Zunächst müssen wir ein Szenario erstellen, in dem Datenwissenschaftler Python/SparkSQL-Tools für die Offline-Funktionsextraktion verwenden. Der KPI von Datenwissenschaftlern besteht darin, ein Geschäftsanforderungsmodell zu erstellen, das der Genauigkeit entspricht. Wenn die Modellqualität den Standard erreicht, ist die Aufgabe abgeschlossen. Die technischen Herausforderungen, mit denen Feature-Skripte konfrontiert sind, nachdem sie online gehen, wie etwa geringe Latenz, hohe Parallelität und hohe Verfügbarkeit, fallen nicht in den Zuständigkeitsbereich von Wissenschaftlern.
Um das vom Datenwissenschaftler geschriebene Python-Skript online zu stellen, muss das Ingenieurteam eingreifen, indem es das vom Datenwissenschaftler geschriebene Offline-Skript rekonstruiert und optimiert Verwenden Sie C++/Datenbank, um einen Feature-Extraktionsdienst in Echtzeit durchzuführen. Dies erfüllt eine Reihe technischer Anforderungen an niedrige Latenz, hohe Parallelität und hohe Verfügbarkeit, sodass Feature-Skripte für Online-Dienste wirklich online gehen können. 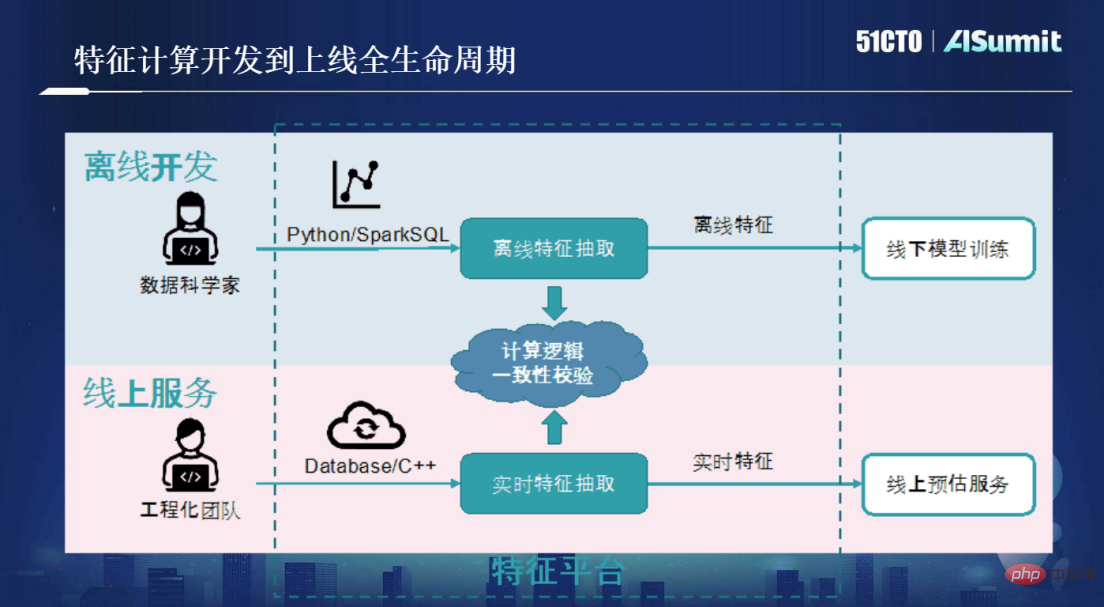
Dieser Prozess ist sehr teuer und erfordert die Intervention zweier Gruppen von Kompetenzteams, und die von ihnen verwendeten Werkzeuge sind unterschiedlich. Nachdem die beiden Prozesssätze abgeschlossen sind, muss die Konsistenz der Berechnungslogik überprüft werden. Das heißt, die Berechnungslogik des vom Datenwissenschaftler entwickelten Feature-Skripts muss vollständig mit der Logik der endgültigen Echtzeit-Feature-Extraktion übereinstimmen . Diese Anforderung scheint klar und einfach zu sein, verursacht jedoch während des Konsistenzüberprüfungsprozesses eine Menge Kommunikationskosten, Testkosten und iterative Entwicklungskosten. Erfahrungsgemäß gilt: Je größer das Projekt, desto länger dauert die Konsistenzprüfung und die Kosten sind sehr hoch.
Im Allgemeinen liegt der Hauptgrund für die Inkonsistenz zwischen Online und Offline während des Konsistenzüberprüfungsprozesses darin, dass die Entwicklungstools beispielsweise Python verwenden und Ingenieurteams Datenbanken verwenden Es gibt funktionale Kompromisse und Inkonsistenzen; es gibt auch Lücken in der Definition von Daten, Algorithmen und Erkenntnissen.
Kurz gesagt, die Entwicklungskosten basierend auf den traditionellen zwei Sätzen von Prozessen sind sehr hoch. Es sind zwei Sätze von Entwicklern mit unterschiedlichen Fähigkeiten erforderlich, die Entwicklung und der Betrieb von zwei Sätzen von Systemen Außerdem wurden in der Mitte Stapel von Verifizierungen, Verifizierungen usw. hinzugefügt.
Und OpenMLDB bietet eine kostengünstige Open-Source-Lösung.
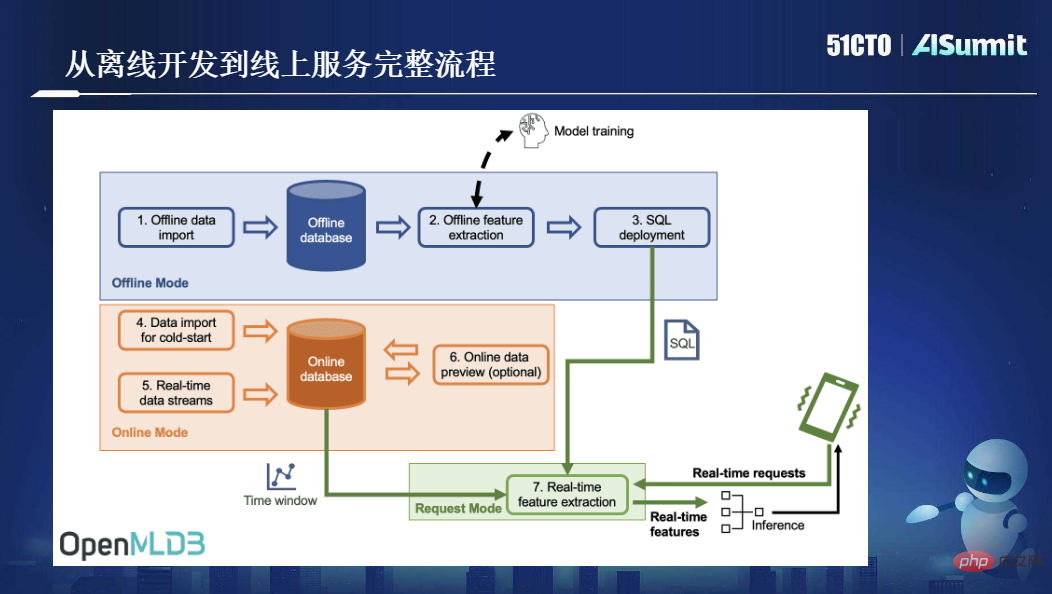
OpenMLDB: Eine Feature-Berechnungsplattform auf Produktionsebene, die online und offline konsistent istIm Juni letzten Jahres wurde OpenMLDB offiziell als Open Source bereitgestellt, es ist jedoch ein junges Projekt in der Open-Source-Community, das jedoch implementiert wurde in mehr als 100 Szenarien, die mehr als 300 mehrere Knoten abdecken.
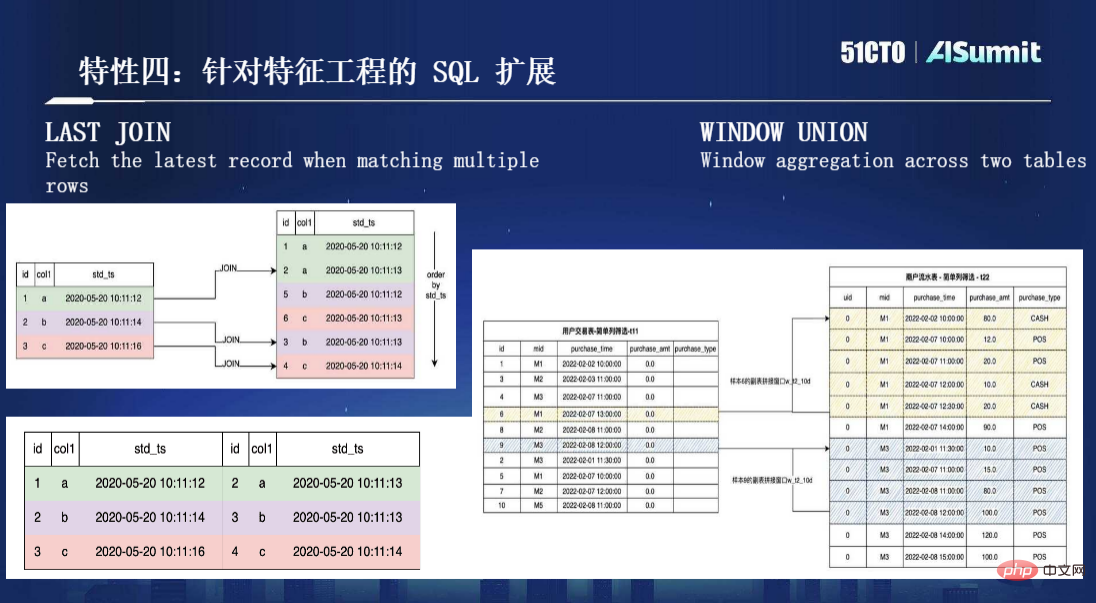
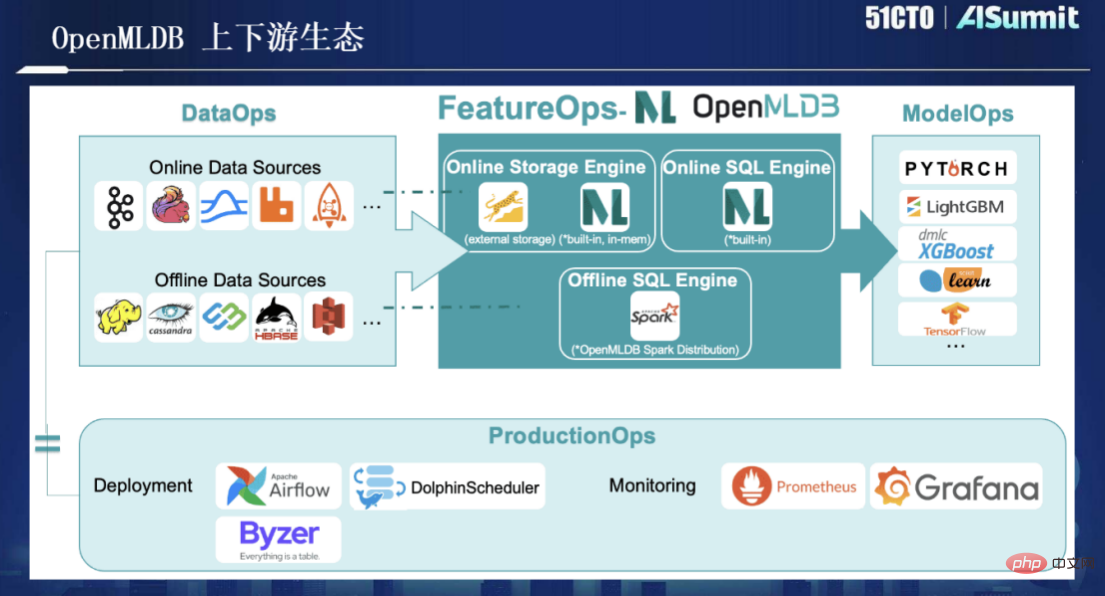
Wie im Bild oben gezeigt, ist SQL die einzige von OpenMLDB verwendete Programmiersprache. Sowohl Datenwissenschaftler als auch Entwickler verwenden SQL nicht mehr, um Funktionen auszudrücken . Zweitens sind in OpenMLDB zwei Gruppen von Engines getrennt: Die eine ist auf der Quellcodeebene auf Basis von Spark++ optimiert, bietet eine leistungsstärkere Rechenmethode und ermöglicht eine Syntaxerweiterung Es handelt sich um eine „Echtzeit-SQL-Engine“. Bei diesem Satz handelt es sich um eine von unserem Team entwickelte Ressourcen-Zeitreihendatenbank. Basierend auf der „Echtzeit-SQL-Engine“ können wir online effiziente Echtzeitberechnungen auf Millisekundenebene durchführen und gleichzeitig eine hohe Verfügbarkeit, geringe Latenz und hohe Parallelität gewährleisten. Es gibt auch einen wichtigen „konsistenten Ausführungsplangenerator“ zwischen diesen beiden Engines, der die Konsistenz der Online- und Offline-Ausführungsplanlogik sicherstellen soll. Damit kann die Online- und Offline-Konsistenz selbstverständlich gewährleistet werden, ohne dass ein manuelles Korrekturlesen erforderlich ist. Kurz gesagt, basierend auf dieser Architektur besteht unser ultimatives Ziel darin, das Optimierungsziel „Entwicklung und Online“ zu erreichen, das hauptsächlich drei Schritte umfasst: Offline-SQL-Funktionsskriptentwicklung und Online-Zugriff auf Real Zeitlicher Anforderungsdatenfluss. Es ist ersichtlich, dass der größte Vorteil dieses Satzes von Motoren im Vergleich zu den beiden vorherigen Sätzen von Prozessen, zwei Sätzen von Werkzeugketten und zwei Sätzen von Entwicklerinvestitionen darin besteht, dass dadurch eine Menge Engineering-Kosten eingespart werden Das heißt, solange Datenwissenschaftler SQL verwenden, um Funktionsskripte zu entwickeln, ist keine zweite Optimierungsrunde mehr durch das Engineering-Team erforderlich, bevor sie direkt online gestellt werden können, und es sind keine manuellen Zwischenvorgänge für die Online- und Offline-Konsistenzüberprüfung erforderlich, was viel spart von Zeit und Kosten. Die folgende Abbildung zeigt den gesamten Prozess von OpenMLDB von der Offline-Entwicklung bis zu Online-Diensten: Insgesamt löst OpenMLDB ein Kernproblem – maschinelles Lernen, Online- und Offline-Konsistenz; bietet eine Kernfunktion – Millisekunde -Ebene Echtzeit-Feature-Berechnung. Diese beiden Punkte sind die Kernwerte von OpenMLDB. Da OpenMLDB über zwei Sätze von Engines verfügt, online und offline, sind auch die Anwendungsmethoden unterschiedlich. Die folgende Abbildung zeigt unsere empfohlene Methode als Referenz: Als Nächstes stellen wir einige Kernkomponenten oder Funktionen in OpenMLDB vor: Funktion 1, konsistente Online- und Offline-Ausführungs-Engine, basierend auf einer einheitlichen Aufgrund der zugrunde liegenden Rechenfunktion werden die Online- und Offline-Ausführungsmodi von logischen Plänen bis hin zu physischen Plänen adaptiv angepasst und stellen so die Online- und Offline-Konsistenz sicher. Funktion zwei, leistungsstarke Online-Feature-Berechnungs-Engine, einschließlich leistungsstarker Doppelschicht-Sprungtabellen-Speicherindex-Datenstruktur; bietet zwei Speicher-/Festplattenspeicher-Engines; um unterschiedliche Leistungs- und Kostenanforderungen zu erfüllen. Feature drei, optimierte Offline-Computing-Engine für die Feature-Berechnung, einschließlich Optimierung der parallelen Berechnung der SQL-Syntax; Dies alles führt zu einer deutlichen Leistungssteigerung im Vergleich zur Community-Version. Feature 4, SQL-Erweiterung für Feature Engineering. Wie bereits erwähnt, verwenden wir SQL für die Feature-Definition, aber tatsächlich ist SQL nicht für die Feature-Berechnung konzipiert. Daher haben wir nach der Untersuchung einer großen Anzahl von Fällen und dem Sammeln von Nutzungserfahrungen festgestellt, dass einige Erweiterungen der SQL-Syntax erforderlich sind um die Feature-Berechnungsszene besser zu handhaben. Hier gibt es zwei wichtige Erweiterungen, eine ist LAST JOIN und die andere ist die häufiger verwendete WINDOW UNION, wie in der folgenden Abbildung dargestellt: Funktion fünf, Funktionsunterstützung auf Unternehmensebene. Als verteilte Datenbank weist OpenMLDB die Merkmale hoher Verfügbarkeit, nahtloser Erweiterung und Kontraktion sowie reibungsloser Aktualisierung auf und wurde in vielen Unternehmensfällen implementiert. Feature sechs, Entwicklung und Verwaltung mit SQL als Kern, OpenMLDB ist auch eine Datenbankverwaltung, die herkömmlichen Datenbanken ähnelt. Wenn beispielsweise eine CLI bereitgestellt wird, kann OpenMLDB den gesamten Prozess in der gesamten CLI implementieren. Angefangen bei den Offline-Funktionen: Von Berechnungen und SQL-Lösungen bis hin zu Online-Anfragen kann es eine vollständige Prozessentwicklungserfahrung basierend auf SQL und CLI bieten. Darüber hinaus ist OpenMLDB jetzt Open Source, und die Erweiterung seiner Upstream- und Downstream-Ökologie ist in der folgenden Abbildung dargestellt: Als nächstes stellen wir eine neue Version von OpenMLDB v0.5 vor. Wir haben einige Verbesserungen in drei Aspekten vorgenommen. Werfen wir zunächst einen Blick auf die Entwicklungsgeschichte von OpenMLDB. Im Juni 2021 wurde OpenMLDB als Open-Source-Lösung veröffentlicht. Tatsächlich hatte das Unternehmen bereits zuvor viele Kunden und begann 2017 mit der Entwicklung der ersten Codezeile. Die Technologieentwicklung dauerte vier oder fünf Jahre. Am ersten Jahrestag nach Open Source haben wir etwa fünf Versionen iteriert. Im Vergleich zu früheren Versionen weist v0.5.0 die folgenden bemerkenswerten Funktionen auf: Leistungsverbesserungen und Aggregationstechnologie können die Leistung bei langen Fenstern erheblich verbessern. Die Optimierung vor der Aggregation verbessert die Leistung um zwei Größenordnungen, sowohl hinsichtlich der Latenz als auch des Durchsatzes bei Abfragen mit langen Fenstern. Kostenreduzierung: Ab Version v0.5.0 bietet die Online-Engine zwei Engine-Optionen basierend auf Speicher und externem Speicher. Basierend auf Speicher, geringer Latenz und hoher Parallelität; Bereitstellung einer Latenzzeit im Millisekundenbereich bei höheren Nutzungskosten. Basierend auf externem Speicher ist es weniger leistungsempfindlich; die Kosten können bei kostengünstigem Einsatz und typischer Konfiguration auf SSD-Basis um 75 % gesenkt werden. Die Geschäftscodes der oberen Schicht der beiden Engines sind nicht wahrnehmbar und können kostenlos gewechselt werden. Erhöhte Benutzerfreundlichkeit. Wir haben in Version v0.5.0 benutzerdefinierte Funktionen (UDF) eingeführt. Das bedeutet, dass benutzerdefinierte Funktionen wie C/C++ UDF, dynamische UDF-Registrierung usw. unterstützt werden, wenn SQL Ihren logischen Ausdruck für die Merkmalsextraktion nicht erfüllen kann Erleichtern Sie den Benutzern die Rechenlogik und verbessern Sie die Anwendungsabdeckung. Abschließend vielen Dank an alle OpenMLDB-Entwickler. Seit Beginn von Open Source haben fast 100 Mitwirkende Codebeiträge in unserer Community geleistet. Gleichzeitig begrüßen wir auch weitere Entwickler, die sich der Community anschließen und ihre eigenen Bemühungen einbringen . Tun Sie etwas Sinnvolleres. Die Aufzeichnung der Konferenzrede und die PPT sind jetzt online. Besuchen Sie die offizielle Website, um die spannenden Inhalte anzusehen. 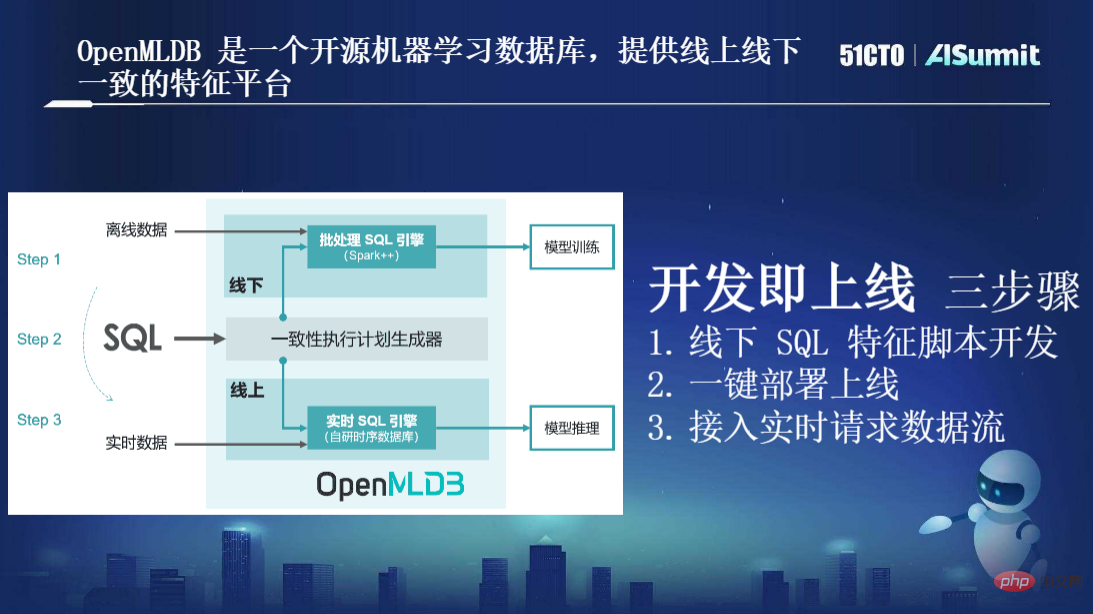

OpenMLDB v0.5.0: Verbesserungen bei Leistung, Kosten und Benutzerfreundlichkeit
Das obige ist der detaillierte Inhalt vonOpenMLDB-Forschungs- und Entwicklungsleiter Lu Mian, Systemarchitekt des vierten Paradigmas: Open-Source-Datenbank für maschinelles Lernen OpenMLDB: eine Funktionsplattform auf Produktionsebene, die online und offline konsistent ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Eine vollständige Liste der Tastenkombinationen für Ideen
Eine vollständige Liste der Tastenkombinationen für Ideen
 Tim Mobile online
Tim Mobile online
 Was bedeutet Kol?
Was bedeutet Kol?
 Konfiguration der JDK-Umgebungsvariablen
Konfiguration der JDK-Umgebungsvariablen
 Was sind die Operatoren in der Go-Sprache?
Was sind die Operatoren in der Go-Sprache?
 So lösen Sie das Problem eines ungültigen Datenbankobjektnamens
So lösen Sie das Problem eines ungültigen Datenbankobjektnamens








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



