


随着机器学习模型在预测和分析数据方面变得越来越流行,随机森林算法的使用正在获得动力。随机森林是一种监督学习算法,用于机器学习领域的回归和分类任务。它的工作原理是在训练时构建大量决策树并输出类,即类的模式(分类)或单个树的平均预测(回归)。
在本文中,我们将讨论如何使用在线真实数据集实现随机森林算法。我们还将提供详细的代码解释和每个步骤的描述,以及对模型性能和可视化的评估。
我们将使用的数据集是“Breast Cancer Wisconsin (Diagnostic) Dataset”,它是公开可用的,可以通过 UCI 机器学习存储库访问。该数据集有 569 个实例,具有 30 个属性和两个类别——恶性和良性。我们的目标是根据 30 个属性对这些实例进行分类,并确定它们是良性还是恶性。您可以从https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data下载数据集。
首先,我们将导入必要的库:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
接下来,我们将加载数据集:
df = pd.read_csv(r"C:UsersUserDownloadsdatabreast_cancer_wisconsin_diagnostic_dataset.csv") df
输出:
在构建模型之前,我们需要对数据进行预处理。由于 'id' 和 'Unnamed: 32' 列对我们的模型没有用,我们将删除它:
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1) df
输出:
接下来,我们将把“诊断”列分配给我们的目标变量并将其从我们的特征中删除:
target = df['diagnosis'] features = df.drop('diagnosis', axis=1)
我们现在将把我们的数据集分成训练集和测试集。我们将使用 70% 的数据进行训练,30% 的数据用于测试:
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
通过我们的数据预处理并分成训练和测试集,我们现在可以构建我们的随机森林模型:
rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train)
在这里,我们将森林中的决策树数量设置为 100,并设置了随机状态以确保结果的可重复性。
现在,我们可以评估模型的性能。我们将使用准确度分数、混淆矩阵和分类报告进行评估:
y_pred = rf.predict(X_test)
# 准确度分数 print("Accuracy Score:", accuracy_score(y_test, y_pred)) # Confusion Matrix conf_matrix = confusion_matrix(y_test, y_pred) print("Confusion Matrix:n", conf_matrix) # Classification Report class_report = classification_report(y_test, y_pred) print("Classification Report:n", class_report)
输出:
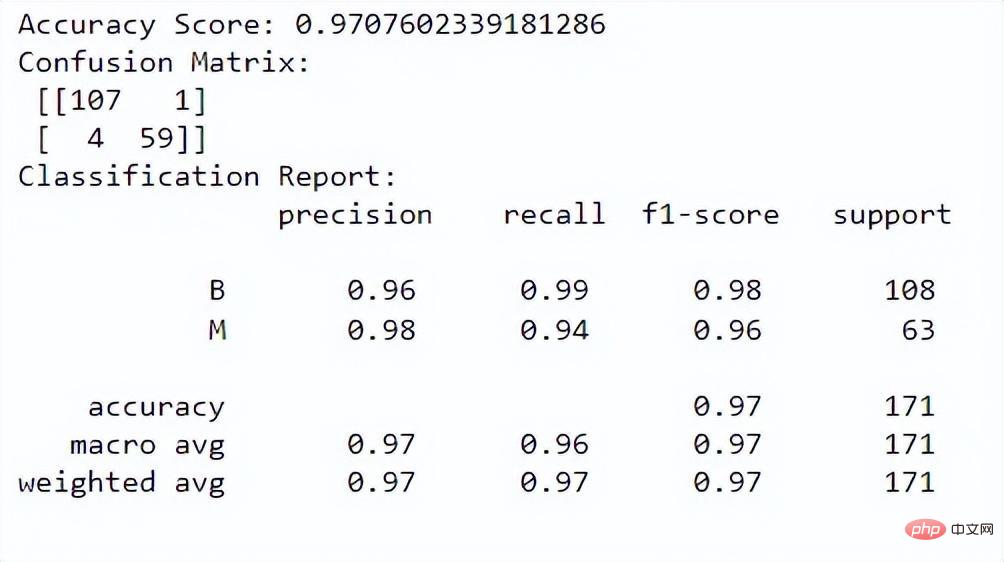
准确性得分告诉我们模型在正确分类实例方面的表现如何。混淆矩阵让我们更好地了解我们模型的分类性能。分类报告为我们提供了两个类别的精度、召回率、f1 分数和支持值。
最后,我们可以可视化模型中每个特征的重要性。我们可以通过创建一个显示特征重要性值的条形图来做到这一点:
importance = rf.feature_importances_ feat_imp = pd.Series(importance, index=features.columns) feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8)) feat_imp.plot(kind='bar') plt.ylabel('Feature Importance Score') plt.title("Feature Importance") plt.show()
输出:
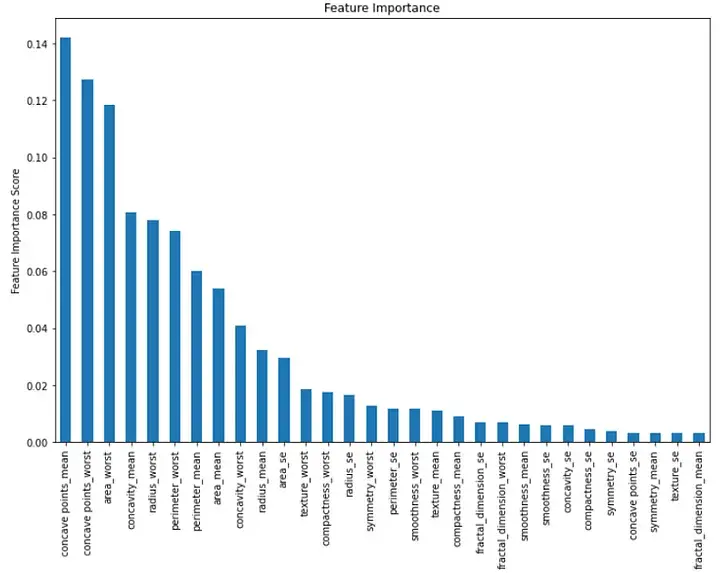
此条形图按降序显示每个特征的重要性。我们可以看到前三个重要特征是“凹点均值”、“凹点最差”和“区域最差”。
总之,在机器学习中实施随机森林算法是分类任务的强大工具。我们可以使用它根据多个特征对实例进行分类并评估我们模型的性能。在本文中,我们使用了在线真实数据集,并提供了详细的代码解释和每个步骤的描述,以及对模型性能和可视化的评估。
Das obige ist der detaillierte Inhalt von机器学习中实施随机森林算法的指南. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie eine ISO-Datei
So öffnen Sie eine ISO-Datei So legen Sie Seitenzahlen in Word fest
So legen Sie Seitenzahlen in Word fest Verwendung zum Löschen der Datenbank
Verwendung zum Löschen der Datenbank iPad-Spiele haben keinen Ton
iPad-Spiele haben keinen Ton Was sind die Voraussetzungen für die Eröffnung eines Digitalwährungskontos? Ist es frei?
Was sind die Voraussetzungen für die Eröffnung eines Digitalwährungskontos? Ist es frei? Was sind die Definitionen von Arrays?
Was sind die Definitionen von Arrays? Was ist ein System?
Was ist ein System? Die Rolle von Pycharm
Die Rolle von Pycharm
























