

Dieser Artikel bringt Ihnen relevantes Wissen überOracle, das hauptsächlich Probleme im Zusammenhang mit der Architektur organisiert. Die Architektur von Oracle ist im Allgemeinen in zwei Teile unterteilt: Instanz (Instanz) und Datenbank (Datenbank). hilft allen.

Empfohlenes Tutorial: „Oracle Video Tutorial“
Die Architektur von Oracle ist im Allgemeinen in zwei Teile unterteilt:Instanz (Instanz)undDatenbank (Datenbank).
Wie in Abbildung 1 gezeigt:
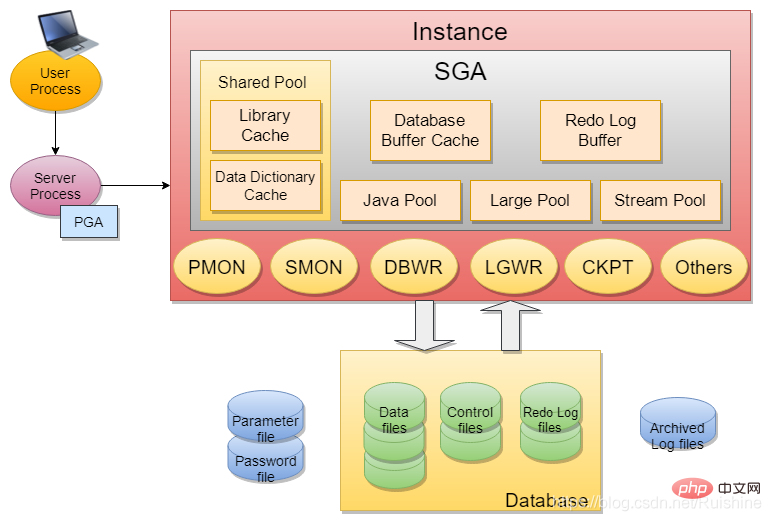
Abbildung 1 Oracle-Datenbankarchitektur
Was wir normalerweiseOracle Server(Oracle-Server) nennen, besteht aus Oracle-Instanz und Oracle-Datenbank, wie in Abbildung 2 dargestellt:
Abbildung 2 Oracle Server
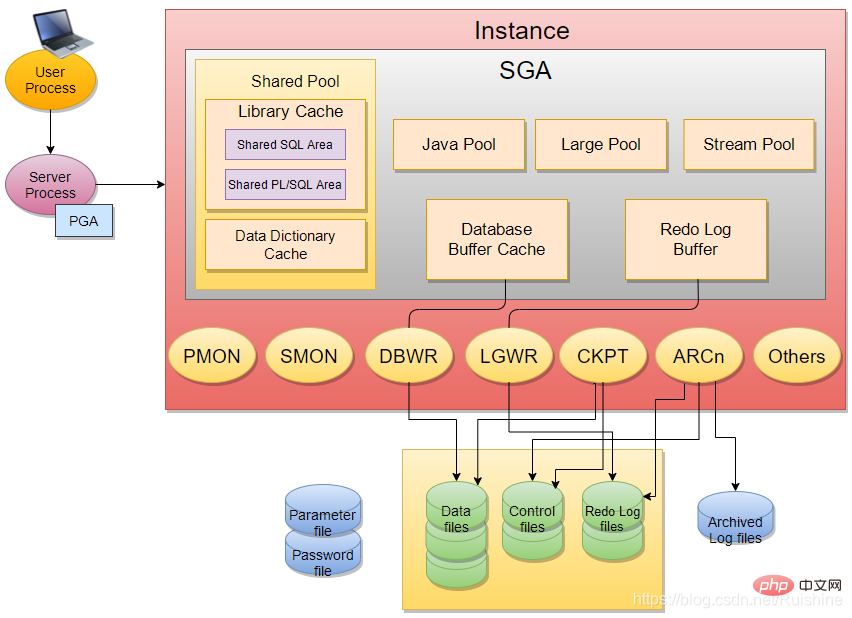
Oracle-InstanzInstanz umfasst hauptsächlich SGA und einige Hintergrundprozesse (z. B. PMON, SMON, DBWR, LGWR, CKPT usw.).
SGA enthält 6 Grundkomponenten:Gemeinsamer Pool (Bibliothekscache, Datenwörterbuch-Cache), Datenbankpuffer-Cache, Redo-Log-Puffer, Java-Pool, großer Pool, Stream-Pool.
Die Funktionen dieser 6 Grundkomponenten werden im Folgenden vorgestellt.
1) Shared Pool
Was sind ihre Funktionen?
Bibliothekscache: Der Parsing-Ort für SQL und PL/SQL, der den Inhalt kompilierter und analysierter SQL- und PL/SQL-Anweisungen speichert, damit alle Benutzer ihn teilen können.
* Wenn Sie das nächste Mal dieselbe SQL-Anweisung ausführen, ist es nicht erforderlich, sie zu analysieren, und sie wird sofort aus dem Bibliothekscache ausgeführt.
* Die GRÖSSE des Bibliothekscache bestimmt die Häufigkeit des Kompilierens und Parsens von SQL-Anweisungen und damit die Leistung.
* Der Bibliothekscache besteht aus zwei Teilen: Shared SQL Area und Shared PL/SQL Area.
Datenwörterbuch-Cache: Speichert wichtige Datenwörterbuchinformationen für die Datenbanknutzung.
* Das Datenwörterbuch wird am häufigsten verwendet und fast alle Vorgänge erfordern eine Abfrage des Datenwörterbuchs. Um die Zugriffsgeschwindigkeit auf das Datenwörterbuch zu verbessern, ist zu diesem Zeitpunkt ein Cache erforderlich, und bei Bedarf kann auf den Speicher zugegriffen werden.
* Zu den Informationen im Data Dictionary Cache gehören Datenbankdateien, Tabellen, Indizes, Spalten, Benutzer, Berechtigungen und andere Datenbankobjekte.
Server-Ergebniscache: Speichert serverseitige SQL-Ergebnismengen und Rückgabewerte von PL/SQL-Funktionen.
Nachdem Sie die obige Erklärung gelesen haben, denken Sie vielleicht, dass sie etwas abstrakt ist, deshalb werde ich sie unten anhand eines Beispiels erklären.
Angenommen, auf dem Client wird ein Befehl wie folgt übermittelt:
SELECT ename,sal FROM emp WHERE empno=7788;
Wenn diese Anweisung zum ersten Mal an die Datenbank übermittelt wird, muss sie analysiert werden. Der Analyseprozess ist in hartes Parsen und weiches Parsen unterteilt.
Library Cache lädt diese SQL-Anweisung und den Ausführungsplan hinein.
Was ist der Zweck der Installation dieser Dinge?
Wenn Sie das nächste Mal denselben Satz eingeben (Interpunktion, Groß- und Kleinschreibung und Leerzeichen sind genau gleich), müssen Sie keine harte Analyse durchführen.
Kurze Frage und Antwort:
Wenn der Client zu diesem Zeitpunkt einen anderen Befehl sendet:
select ename,sal from emp where empno=7788;
Ratet mal, muss diese Aussage analysiert werden?
Antwort: Ja.
Tipps: Beachten Sie, dass die Anweisungen genau gleich sein müssen, um ein Parsen zu vermeiden. Zeichensetzung, Groß- und Kleinschreibung, Leerzeichen usw. müssen genau gleich sein! Hier kommen die Vorteile des regelmäßigen Schreibens zum Ausdruck.
Wie bereits erwähnt, wird die Ergebnismenge nach der Ausführung zurückgegeben, wenn es sich um eine SELECT-Anweisung handelt. Wo wird die Ergebnismenge gespeichert?
select ename,sal from emp where empno=7788;
Der durch die Ausführung dieser Anweisung zurückgegebene Ergebnissatz wird im Server-Ergebniscache gespeichert.
2) Datenbankpuffer-Cache
小说明:逻辑读(从内存读)的速度是物理读(从磁盘读)的1万倍呦,所以还是想办法尽量多从内存读哦。
所以,数据缓冲区的大小对数据库的读取速度有直接的影响。
例如用户访问一个表里面的记录时,数据库接收到这个请求后,首先会在Database Buffer Cache中查找是否存在该数据库表的记录,如果有所需的记录就直接从内存中读取该记录返回给用户(有效提升了访问的速度),否则只能去磁盘上去读取。
继续看上面的例子:
select ename,sal from emp where empno=7788;
该条语句以及它的执行计划被放在Library Cache里,但语句涉及到的数据,会放在 Database Buffer Cache 里。
小问答:
Database Buffer Cache是怎么工作的呢?
这就要说一说Database Buffer Cache的设计思想了。
磁盘上存储的是块(block),文件都有文件号,块也有块号。
若要访问磁盘上的块,并不是CPU拿到指令后直接访问磁盘,而是先把块读到内存中的Database Buffer cache里,生成副本,查询或增删改都是对内存中的副本进行操作。如图3所示。
另外,如果是增删操作,操作后会形成脏块,脏块会在恰当时机再写回磁盘原位置,注意哦,可不是立刻写回呦。
也许你会问,为什么不立刻写回呢?
因为:
(1)减少物理IO;
(2)可共享,若后面又有对该块的访问,可直接在内存中进行逻辑读。
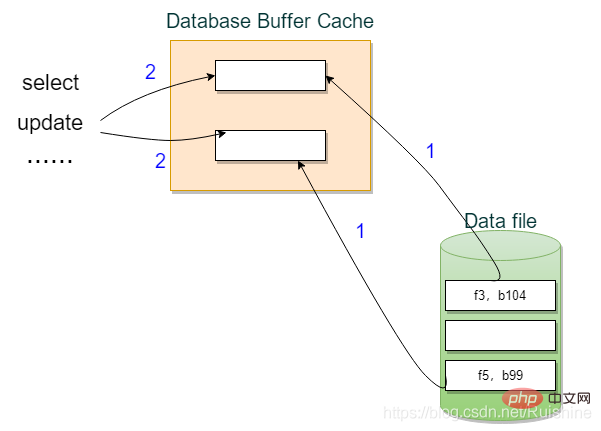
图3 访问数据块
小问答:
为什么要通过内存访问数据块,而不是CPU直接访问磁盘呢?
答:因为相较于CPU,IO的速度实在是太慢了,CPU的速度是IO 的100万倍呢?如果CPU直接访问磁盘的话,会造成大量的IO等待,CPU的利用率会很低。所以,利用速度相当的内存(CPU速度为内存的100倍)做中间缓存,可以有效减少物理IO,提高CPU利用率。
但是,这里会有一个问题。前面说到查询或增删改都是对内存中的副本进行操作,当增删改操作产生脏块时不会立刻写回磁盘。
小问答:
我们设想一下,如果在 Database Buffer Cache 中存放大量未来得及写回磁盘的脏块时,突然出现系统故障(比如断电),导致内存中的数据丢失。而此时磁盘中的块存放的依然是修改前的旧数据,这样岂不是导致前面的修改无效?
要怎样保持事务的一致性呢?
答:如果我们能够保存住提交的记录,在 Database Buffer Cache 中一旦有数据更改,马上写入一个地方记录下来,不就可以保证事务一致性了嘛。
小说明:Instance在断电时会消失,Instance在内存中存放的数据将丢失。这就需要 Redo Log Buffer 发挥它的作用啦。
3)Redo Log Buffer
4)Large Pool(可选)
为了进行大的后台进程操作而分配的内存空间,与 shared pool 管理不同,主要用于共享服
务器的 session memory,RMAN 备份恢复以及并行查询等。
5)Java Pool(可选)
为了 java 虚拟机及应用而分配的内存空间,包含所有 session 指定的 JAVA 代码和数据。
6)Stream Pool(可选)
为了 stream process 而分配的内存空间。stream 技术是为了在不同数据库之间共享数据,
因此,它只对使用了 stream 数据库特性的系统是重要的。
Background process
在正式介绍 Background Process 之前,先简单介绍 Oracle 的 Process 类型。
Oracle Process 有三种类型:
客户端要与服务器连接,在客户端启动起来的进程就是 User Process,一般分为三种形式(sql*plus, 应用程序,web 方式(OEM))。
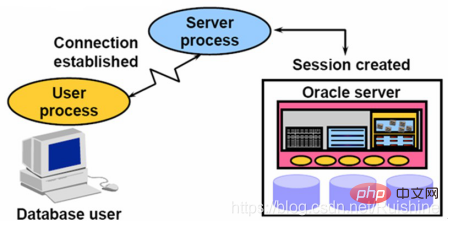
Der Benutzerprozess kann nicht direkt auf Oracle zugreifen. Er muss über den entsprechenden Serverprozess auf die Instanz zugreifen und dann auf die Datenbank zugreifen.
Wenn sich ein Benutzer bei Oracle Server anmeldet, stellen der Benutzerprozess und der Serverprozess eine Verbindung her.
Ein wichtiger Teil der Oracle-Instanz. Dies wird im Folgenden ausführlich erläutert.
Kleiner Zusatz:
Connection & Session
Connection bezieht sich auf die TCP-Verbindung, die von einem Oracle-Client und dem Hintergrund- und Hintergrundprozess (Serverprozess) aufgebaut wird. Wie in Abbildung 4 dargestellt: Abbildung 4 Verbindung .;2. Wenn diese übergeben werden, ermöglicht der Oracle-Serverprozess, dass der Client die von Oracle bereitgestellten Dienste nutzt.
Sie können den Unterschied zwischen Verbindung und Sitzung anhand von Abbildung 5 intuitiv erkennen.
Abbildung 5 Verbindung und Sitzung
Der Hintergrundprozess (Hintergrundprozess) umfasst hauptsächlich: SMON (Systemüberwachungsprozess), PMON (Prozessüberwachungsprozess), DBWR (Datenbankschreibprozess), LGWR (Protokollschreibprozess), CKPT (Checkpoint-Prozess).
1) PMON (Prozessmonitor)
Die Hauptfunktionen von PMON sind wie folgt:
Überwachen Sie, ob jeder Oracle-Hintergrundprozess normal ist, löschen Sie den abnormalen Prozess, wenn er gefunden wird, und generieren Sie den Prozess neu.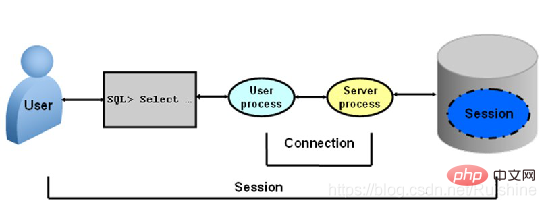
(Hinweis: Wenn die Verbindung zum Benutzerprozess getrennt wird, ist der Serverprozess unbrauchbar, wenn er verbleibt, aber er nimmt immer noch Platz ein. PMON überprüft den Serverprozess regelmäßig. Wenn er nicht mit dem Benutzerprozess verbunden werden kann, übernimmt PMON
Überwachen Sie, ob die Leerlaufsitzung den Schwellenwert erreicht.
Dynamische Registrierung und Überwachung.
2) SMON (Systemmonitor)3) DBWR (Database Writer)
Wenn die Datenbanklast relativ groß ist, es viele Anfragen von Clients gibt, eine große Anzahl von E/A-Vorgängen vorhanden sind und der Pufferinhalt häufig in Festplattendateien geschrieben werden muss, können Sie mehrere konfigurieren DBWn (Oracle unterstützt insgesamt 20 DBWn, DBW0-DBW9, DBWa-DBWg). Normalerweise benötigt ein kleines und mittleres Oracle nur einen DBW0-Prozess.
Hinweis: Wenn die folgenden Situationen auftreten, wird der DBWR-Prozess ausgelöst, um den Inhalt des Datenbankpuffercaches in Datendateien zu schreiben:Es sind keine freien Puffer vorhanden
Es tritt eine Zeitüberschreitung auf.RAC-Ping-Anfrage wird gestellt.
Tablespace OFFLINE.
Wie kann sichergestellt werden, dass die festgeschriebene Transaktion dauerhaft erhalten bleibt?
Antwort: Der Update-Vorgang wurde als Beispiel durchgeführt.
1. Beim Schreiben der Commit-Anweisung wurden die Änderungen in den Redo-Log-Puffer geschrieben
2 Nach erfolgreicher Übermittlung wurden die Änderungen mit der Festplatte synchronisiert und gehen nicht verloren.
Darüber hinaus gibt es Parameterdateien, Passwortdateien, erreichte Protokolldateien usw.
* Zum Beispiel: Es gibt eine Transaktion in der Datenbank, die übermittelt werden muss, aber die Übermittlung schlägt fehl und die Transaktion muss zurückgesetzt werden. Dann sind die Redo-Log-Dateien die Grundlage für das Transaktions-Rollback. Redo-Log-Dateien zeichnen Datenbankänderungen auf. Wenn Sie ein Rollback durchführen müssen, müssen Sie die Daten in den Redo-Log-Dateien herausnehmen und die Datendateien entsprechend den Daten in den Redo-Log-Dateien in den Zustand vor der Änderung zurückversetzen.
Kurze Frage und Antwort:Was ist die entsprechende Beziehung zwischen Instanz und Datenbank?
Antwort: Instanz: Datenbank = n: 1
1 Instanz kann nur zu einer Datenbank gehören und mehrere Instanzen können gleichzeitig auf eine Datenbank zugreifen.
Oracles Speicherstruktur
PGA (Program Global Area)
Empfohlenes Tutorial: „Oracle Video Tutorial“
Das obige ist der detaillierte Inhalt vonEine kurze Analyse der Oracle-Architektur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





































