


Dieser Artikel gibt Ihnen eine detaillierte Analyse des Indexes in MySQL und hilft Ihnen, die Prinzipien der MySQL-Indizierung zu verstehen. Ich hoffe, er wird Ihnen hilfreich sein!

Ein Index ist eine sortierte Datenstruktur, die MySQL hilft, Daten effizient zu erhalten
Vorwissen: Je niedriger die Höhe des Baums, desto höher die Abfrageeffizienz
Website zur Datenstruktursimulation: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
(1) Binärbaum
Problem: Er kann sich nicht selbst ausgleichen, in extremen Fällen kommt es zu einer Neigung. und die Abfrageeffizienz ähnelt der einer verknüpften Liste. 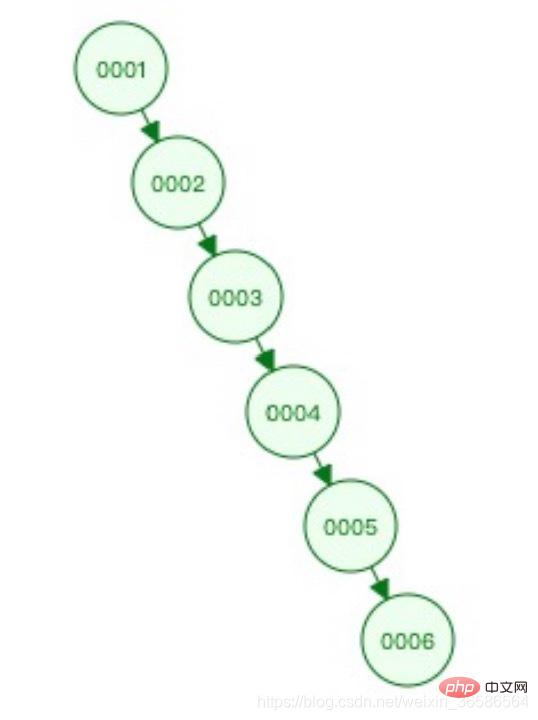
(2) Rot-Schwarz-Baum
Der Rot-Schwarz-Baum gleicht die Daten aus und löst das Problem des einseitigen Wachstums Wenn die Datenmenge groß ist, ist die Höhe des Baums nicht kontrollierbar und muss mehrmals vom Wurzelknoten bis zum Blattknoten durchlaufen werden, was ineffizient ist. 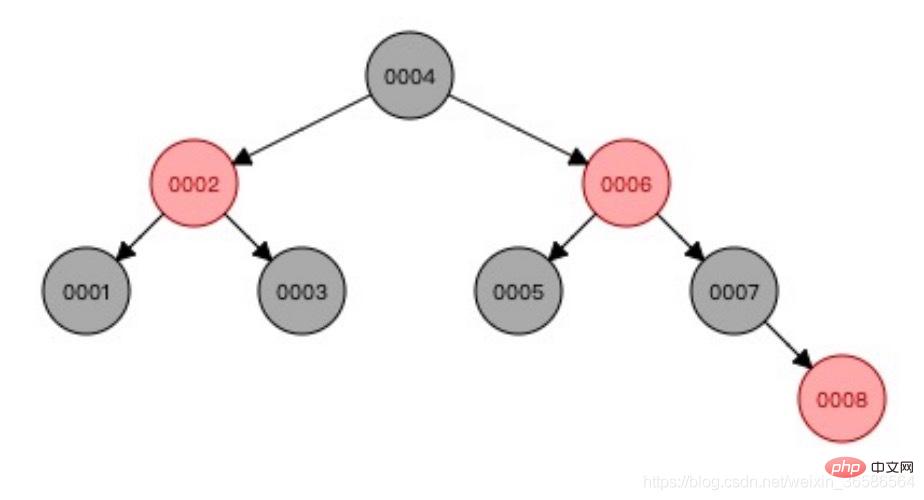
1. Eine Hash-Berechnung auf dem Indexschlüssel kann den Speicherort der Daten lokalisieren
2. In vielen Fällen ist der Hash-Index effizienter als der B+-Baum-Index
3. Nur „=“ kann sein zufrieden, „IN“, unterstützt keine Bereichsabfrage
4. Hash-Konfliktproblem 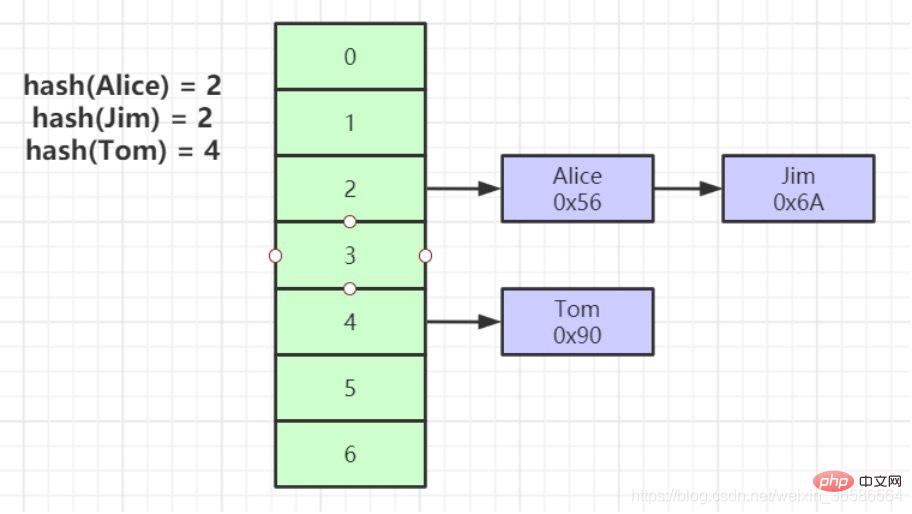
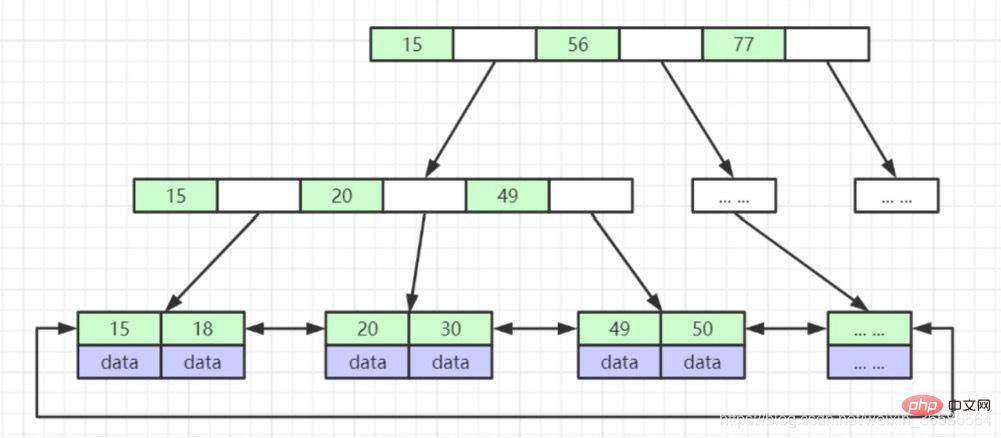
1. Die Blattknoten haben die gleiche Tiefe und die Zeiger der Blattknoten sind leer
2 . Alle Indexelemente werden nicht wiederholt
3. Die Datenindizes in den Knoten sind in aufsteigender Reihenfolge von links nach rechts angeordnet 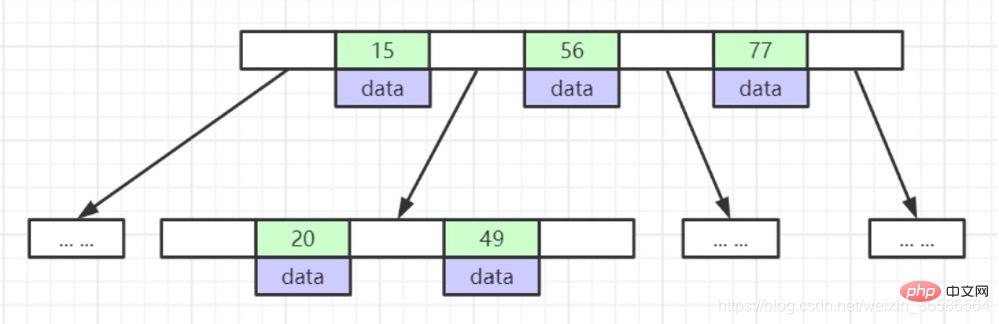
1. Nicht-Blattknoten Speichern Sie keine Daten, nur Indizes (redundant). Weitere Indizes können platziert werden
2. Blattknoten enthalten alle Indexfelder
3. Blattknoten sind mit Zeigern verbunden, um die Leistung des Intervallzugriffs zu verbessern
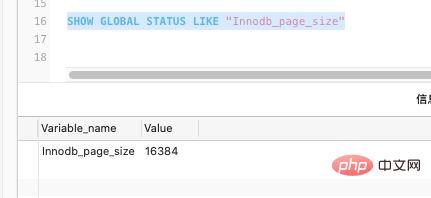
In MySQL beträgt die Standardgröße unserer InnoDB-Seite 16 KB. Natürlich kann sie auch über Parameter festgelegt werden:
SHOW GLOBAL STATUS LIKE "Innodb_page_size"
Weil wir nicht wissen, auf welcher Seite die Daten, die wir suchen möchten, vorhanden sind, und es unmöglich ist, alle Seiten zu durchsuchen zu langsam.
Also dachten die Leute über eine Möglichkeit nach, diese Daten mithilfe des B+-Baums zu organisieren. Wie in der Abbildung gezeigt: 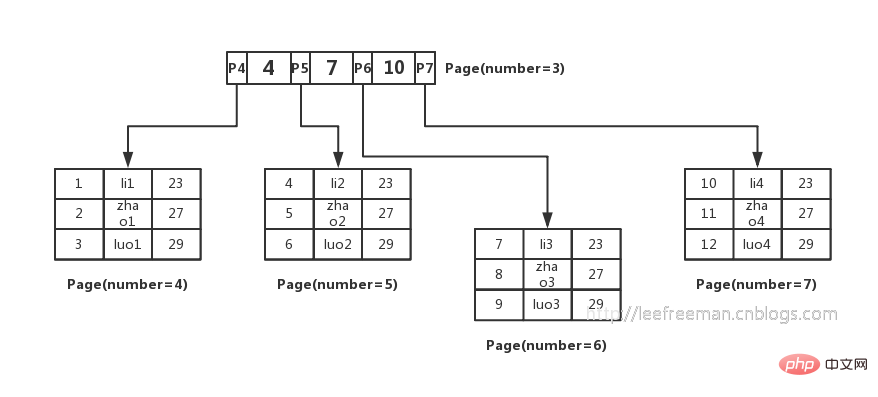
1. Die kleinste Speichereinheit der InnoDB-Speicher-Engine ist eine Seite, die zum Speichern verwendet werden kann Daten oder Verwendung Zum Speichern von Schlüsselwerten + Zeigern speichern Blattknoten im B + -Baum Daten und Nicht-Blattknoten speichern Schlüsselwerte + Zeiger.
Wie viel können wir auf einer Seite speichern? Eine solche Einheit stellt tatsächlich dar, wie viele Zeiger es gibt, also 16384/14 = 1170.
Dann lässt sich berechnen, dass ein B+-Baum mit einer Höhe von 2 1170*16=18720 solcher Datensätze speichern kann.
Basierend auf dem gleichen Prinzip können wir berechnen, dass ein B+-Baum mit einer Höhe von 3 Folgendes speichern kann: 1170*1170*16=21902400 solcher Datensätze.
In InnoDB beträgt die Höhe des B+-Baums im Allgemeinen 1-3 Schichten, was zig Millionen Datenspeicher ausfüllen kann.
Bei der Suche nach Daten stellt eine Seitensuche eine E/A dar, sodass die Abfrage des Primärschlüsselindex normalerweise nur 1–3 E/A-Vorgänge erfordert, um die Daten zu finden.
B-Baum
Blattknoten haben die gleiche Tiefe und die Zeiger der Blattknoten sind leer.
Alle Indexelemente werden nicht wiederholt.
Der Datenindex im Knoten wird inkrementell von links nach rechts angeordnet.
B+-Baumindex
Nicht-Blattknoten speichern keine Daten, sondern nur Indizes (redundant), es können mehr Indizes platziert werden.
Blattknoten enthalten alle Indexfelder.
Blattknoten sind mit Zeigern verbunden, um die Leistung des Intervallzugriffs zu verbessern.
Warum Datenknoten verschoben werden Für Blattknoten kann ein Knoten mehr Indizes speichern
16^n=20 Millionen, n ist die Höhe des Baums und die gleichen Daten werden gespeichert. Die Höhe des B+-Baums ist viel kleiner als die des B-Baums
Der B-Baum speichert die Daten unabhängig von Blattknoten oder Nicht-Blattknoten, was dazu führt, dass die Anzahl der Zeiger, die in Nicht-Blattknoten gespeichert werden können, kleiner wird (einige Daten werden auch als Fan-Out bezeichnet, wenn nur wenige Zeiger vorhanden sind).
5 Die Bedeutung des Clustered-Index: Das Blatt Knoten speichern den Index und die Daten, auch Clustered-Index genannt.
Nicht gruppierter Index wird auch als Sparse-Index bezeichnet. Der Primärschlüsselindex ist ein Clustered-Index! (1) MyISAM-Indexdateien und Datendateien sind getrennt (nicht aggregiert). MyISAM-Indexdateien und Datendateien sind getrennt (nicht aggregiert), und die Speicher-Engine wirkt auf die Tabelle.
Indexdateien speichern Indizes und Daten Dateien speichern Daten, Index und Daten werden nicht zusammen gespeichert
Abfrage: Fragen Sie zuerst den Index im B+-Baum ab und fragen Sie dann die Datendatei unter Verwendung des abgefragten Speicherorts ab 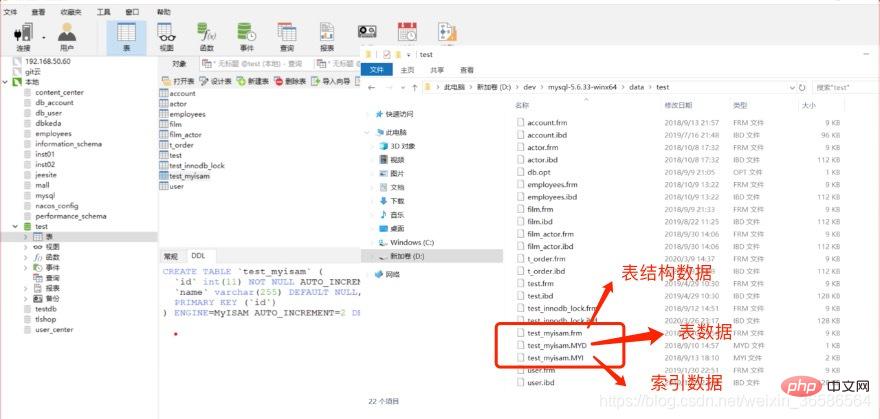
(1) InnoDB-Indeximplementierung
Tabellendatenindexdaten sind gespeichert in .ibd In der Datei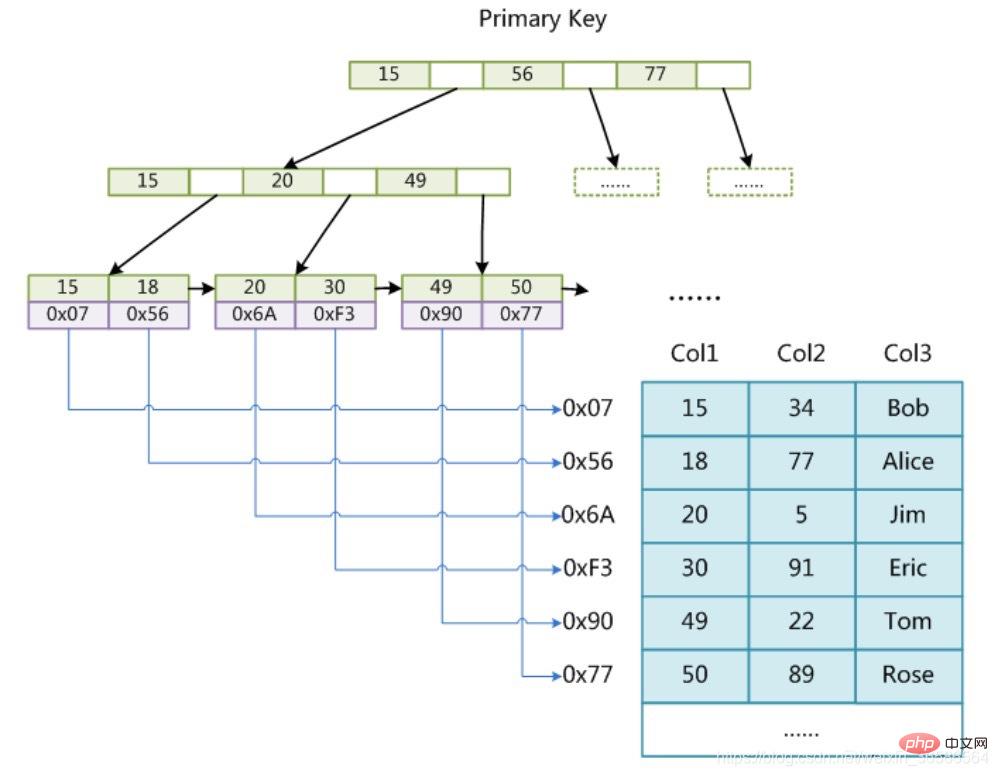
1 Die Tabellendatendatei selbst ist eine von B+Tree organisierte Indexstrukturdatei
2. Geclusterte Indexblattknoten enthalten vollständige Datensätze (1) Primärschlüsselindex:
(1) Primärschlüsselindex:
(2) Hilfsindex (Sekundärindex)
Die Blattknoten des Primärschlüsselindex speichern vollständige Datenzeilen, während die Blattknoten des Nicht-Primärschlüsselindex den Primärschlüsselindexwert speichern. Primärschlüsselindex: Zuerst wird der Primärschlüsselindex gefunden. Gehen Sie dann zum Primärschlüsselindex, um die entsprechenden Daten zu finden. Dieser Vorgang wird als Tabellenrückgabe bezeichnet (wird weiter unten noch einmal erwähnt). 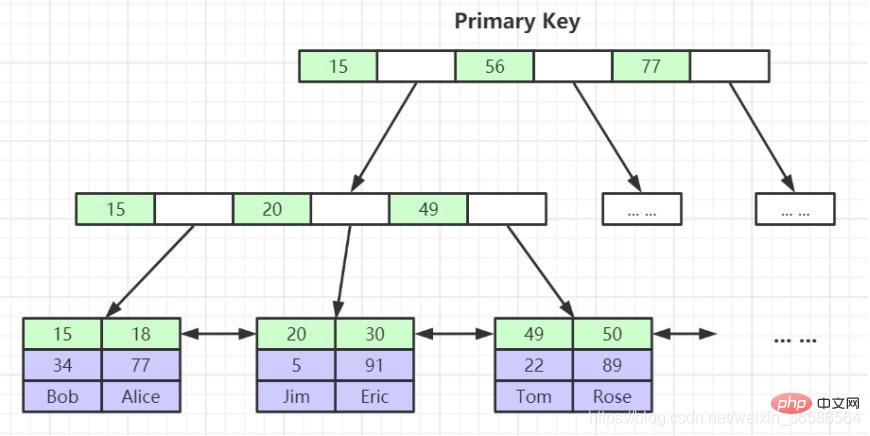
(2) Was passiert, wenn UUID als Primärschlüssel anstelle eines ganzzahligen, automatisch inkrementierenden Primärschlüssels verwendet wird? 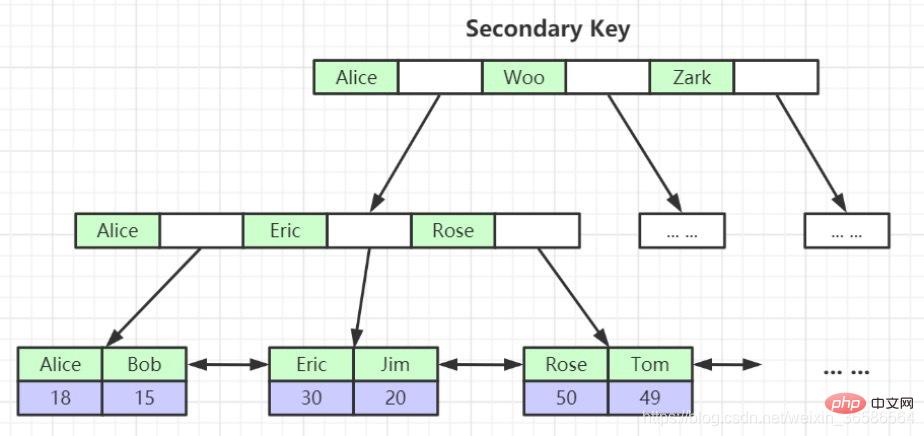 UUID ist ein Zeichenfolgentyp und Abfrageoperationen verfügen über Vergleichsoperationen. Ganzzahlige Vergleichsoperationen sind schneller, ganzzahlige Primärschlüssel sparen Platz als UUIDs und UUIDs werden nicht automatisch inkrementiert.
UUID ist ein Zeichenfolgentyp und Abfrageoperationen verfügen über Vergleichsoperationen. Ganzzahlige Vergleichsoperationen sind schneller, ganzzahlige Primärschlüssel sparen Platz als UUIDs und UUIDs werden nicht automatisch inkrementiert.
Warum nicht Hash verwenden?
Hash unterstützt Bereichsabfragen nicht gut. Die Daten in einer bestimmten Spalte sind ungeordnet, und der B+-Baum kann die Daten beim Erstellen ordnen. 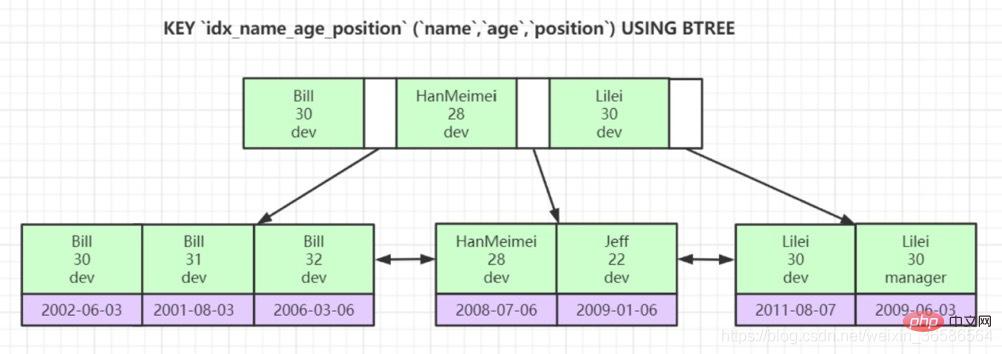 4. Warum speichern Blattknoten von Nicht-Primärschlüssel-Indexstrukturen Primärschlüsselwerte? (Konsistenz und Speicherplatzersparnis)
4. Warum speichern Blattknoten von Nicht-Primärschlüssel-Indexstrukturen Primärschlüsselwerte? (Konsistenz und Speicherplatzersparnis)
1. Jeder Index entspricht einem B+-Baum. Benutzerdatensätze werden in Blattknoten des B+-Baums gespeichert, und alle Verzeichnisdatensätze werden in Nicht-Blattknoten gespeichert.
2. Die InnoDB-Speicher-Engine erstellt automatisch einen Clustered-Index als Primärschlüssel (falls dieser nicht vorhanden ist, fügt er ihn automatisch für uns hinzu). Die Blattknoten des Clustered-Index enthalten vollständige Benutzerdatensätze.
3. Für die angegebene Spalte kann ein Sekundärindex erstellt werden. Der im Blattknoten des Sekundärindex enthaltene Benutzerdatensatz besteht aus der Indexspalte + dem Primärschlüssel. Wenn Sie also den vollständigen Benutzerdatensatz über den Sekundärindex finden möchten Index, Sie müssen den Tabellenvorgang zurückgeben besteht darin, den vollständigen Benutzerdatensatz im Clustered-Index zu finden, nachdem der Primärschlüsselwert über den Sekundärindex ermittelt wurde.
4. Die Knoten auf jeder Ebene im B+-Baum werden entsprechend dem Indexspaltenwert von klein nach groß sortiert, um eine doppelt verknüpfte Liste zu bilden, und die Datensätze auf jeder Seite (sei es ein Benutzerdatensatz oder ein Verzeichniseintrag). Datensatz) werden nach dem Index geordnet. Die Spaltenwerte bilden eine einfach verknüpfte Liste in aufsteigender Reihenfolge. Wenn es sich um einen gemeinsamen Index handelt, werden die Seiten und Datensätze zunächst nach der Spalte vor dem gemeinsamen Index sortiert. Wenn die Spaltenwerte gleich sind, werden sie nach der Spalte nach dem gemeinsamen Index sortiert.
Die Suche nach Datensätzen über den Index beginnt am Wurzelknoten des B+-Baums und sucht Schicht für Schicht nach unten. Da jede Seite über ein Seitenverzeichnis verfügt, das auf dem Wert der Indexspalte basiert, sind Suchvorgänge auf diesen Seiten sehr schnell.
Blog anzeigen: Zusammenfassung mehrerer Situationen, in denen der MySQL-Index fehlschlägt
https://blog.csdn.net/weixin_36586564/article/details/79641748
[Verwandte Empfehlungen: MySQL-Video-Tutorial]
Das obige ist der detaillierte Inhalt vonEingehende Analyse von Indizes in MySQL (ausführliche Erläuterung der Prinzipien). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



