

Dieser Artikel bringt Ihnen Fragen zuRedisvom Einstieg bis zur Praxis, einschließlich ausführlicher Tutorials zum Einstieg in Redis6.0, Redis-Persistenz, Redis-Replikationsprinzipien, Redis-Hochverfügbarkeits-Sentinel-Überwachung und Wissen über den Clusteraufbau. Ich hoffe, es hilft allen .

Detailliertes Tutorial für den Einstieg in Redis6.0, Redis-Persistenz, Redis-Replikationsprinzip, Redis-Hochverfügbarkeits-Sentinel-Überwachung und Cluster-Konstruktion.
Interviewer: Leute, sagt mir, was ihr über Redis denkt.
Ich: Ah, was denkst du, setz dich hin und schau es dir an oder leg dich hin und schau es dir an. Redis ist klein? bald? Aber langlebig?
Interviewer: Im Ernst gesagt, ich vermute, dass Sie Auto fahren, nicht nur Autofahren, sondern auch Farbe.
ICH:. . .
Interviewer: Mach weiter, mach weiter, meine Zeit ist begrenzt, rede keinen Unsinn. Zurück zum Thema: Wie viel wissen Sie über Redis?
Ich: Leicht und klein, basierend auf dem Speicher sehr schnell, RDB- und AOF-Persistenz machen es gleichermaßen stark und langlebig.
Interviewer: Seien Sie konkret.
Ich: Bitte lesen Sie den Text.

Einführung
Redis ist ein leistungsstarkes Open-Source-Caching- und Speichersystem auf der Basis von Schlüsselwertpaaren, das eine Vielzahl von Schlüsselwertdatentypen zur Anpassung an die Caching- und Speicheranforderungen bereitstellt verschiedene Szenarien. Gleichzeitig ermöglichen die vielen High-Level-Funktionen von Redis die Erfüllung verschiedener Rollen wie Nachrichtenwarteschlange und Aufgabenwarteschlange. Darüber hinaus unterstützt Redis auch die Erweiterung durch externe Module und kann in bestimmten spezifischen Szenarien als Hauptdatenbank verwendet werden.
Da die Lese- und Schreibgeschwindigkeit des Speichers viel schneller ist als die der Festplatte, entwickelt sich wahrscheinlich sogar die aktuelle Denkweise der Solid-State-Disk in Richtung der Denkweise des Speichers, aber für die Langzeitspeicherung bin ich vielleicht ein Amateur Ich verwende immer noch eine mechanische Festplatte. Daher werden alle Daten in der Redis-Datenbank im Speicher gespeichert, was recht schnell geht. Es besteht auch ein gewisses Risiko, das zu Datenverlust führt, aber die Arbeit mit RDB und AOF-Persistenz verringert das Risiko.
Das hier vorbereitete Quellcodepaket ist nicht die neueste Version, aber stabil und anwendbar.
Die restlichen Versionen sind auf der offiziellen Website oder auf der Github-Hosting-Plattform verfügbar. Nachfolgend finden Sie die offizielle Website-Download-Adresse von Redis.
https://redis.io/download
redis-6.0.8.tar.gz#安装tar -zxvf redis-6.0.8.tar.gz#编译make && make install
make[1]: *** [server.o] 错误 1

1.3.1, abhängige Umgebung installieren
yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
1.3.2, Umgebungsvariablen hinzufügen und wirksam werden
scl enable devtoolset-9 bashecho "/opt/rh/devtoolset-9/enable" >> /etc/profile
Lesen Sie die Umgebungsvariablen-Konfigurationsdatei noch einmal
source /etc/profile
Kompilieren Sie neu, um das Problem zu lösen
#切换到Redis的安装目录,一般源码包安装会放在/usr/local/下面,看个人使用习惯cd /opt/redis-6.0.8/ #编译make && make install
Für allgemeine grundlegende Befehlsübungen können Sie sich auf das Anfänger-Tutorial beziehen
https://www.runoob.com/ redis/redis-commands .html
#启动redis服务nohup /opt/redis-6.0.8/src/redis-server &
#登录redis-cli/opt/redis-6.0.8/src/redis-cli
 2. Installieren Sie
2. Installieren Sie
pingpong
2.1.2. Dienstbefehl festlegen (als Dienstformular registrieren, selbst starten)
#编辑配置文件vim /opt/redis-6.0.8/redis.conf #原本的被注释掉,复制一行改成你设置的密码即可 #requirepass foobaredrequirepass 123456
Redis-x64-3.2.100.zip
redis-server --service-install redis.windows-service.conf --loglevel verbose
2.2. Stoppen Sie den Dienst
redis-server --service-uninstall
redis-server redis.windows.conf
2. Häufig gestellte Interviewfragen
: String (String-Typ), Hash (Hash-Typ), Liste (Listentyp), Set (Set-Typ), Zset (geordneter Set-Typ),
stream (Stream-Typ) Stream ist Unterstützung für neue Funktionen in redis5.0.Interviewer
: Oh, dieser junge Mann hat etwas. Er weiß viel, sogar die Stream-Genres.
3. Fortgeschrittene1. Persistenz
Interviewer: Kennen Sie einige erweiterte Funktionen von Redis?
Ich
Interviewer
: Können Sie im Detail darüber sprechen?Ich
: Ich habe es vor den Hirnforschern schnell gelesen und zusammengefasst. Caching und Persistenz kommen.将Redis作为缓存服务器,但缓存被穿透后会对性能照成较大影响,所有缓存同时失效缓存雪崩,从而使服务无法响应。
我们希望Redis能将数据从内存中以某种形式同步到磁盘中,使之重启以后根据磁盘中的记录恢复数据。这一过程就是持久化。
面试官:知道Redis有哪几种常见的持久化方式吗?
我:Redis默认开启的RDB持久化,AOF持久化方式需要手动开启。
Redis支持两种持久化。一种是RDB方式,一种是AOF方式。前者会根据指定的规则“定时”将内存中的数据存储到硬盘上,而后者在每次执行命令后将命令本书记录下来。对于这两种持久化方式,你可以单独使用其中一种,但大多数情况下是将二者紧密结合起来。
此时的面试官一脸期待,炯炯有神的看向了我,请继续。
继续介绍,RDB采取的是快照方式,默认设置自定义快照【自动同步】,默认配置如下。

同样可以手动同步
#不推荐在生产环境中使用SAVE
#异步形式BGSAVE
#基于自定义快照FLASHALL
当使用Redis存储非临时数据时,一般需要打开AOF持久化来降低进程终止导致数据的丢失。AOF可以将Redis执行的每一条命令追加到硬盘文件中,着这个过程中显然会让Redis的性能打折扣,但大部分情况下这种情况可以接受。这里强调一点,使用读写较快的硬盘可以提高AOF的性能。
默认没有开启,需要手动开启AOF,当你查看redis.conf文件时也会发现appendonly配置的是no
appendonly yes
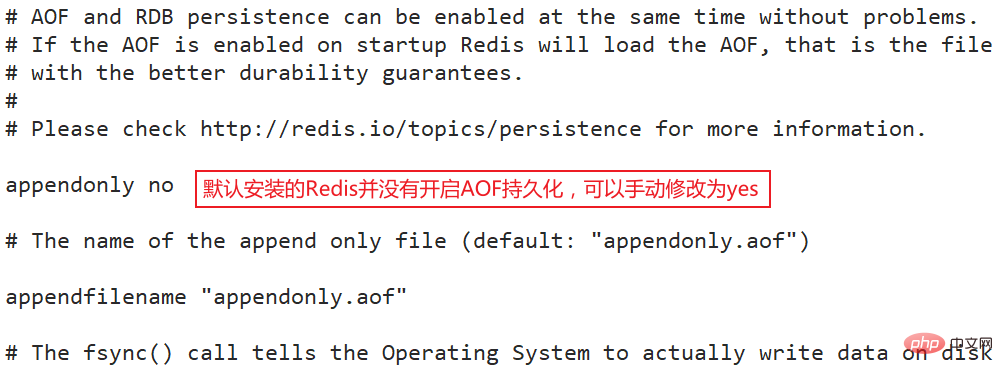
开启AOF持久化后,每次执行一条命令会会更改Redis中的数据的目录,Redis会将该命令写入磁盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置,默认的文件名是appendonly.aof,可以通过appendfilename参数修改。
appendfilename "appendonly.aof

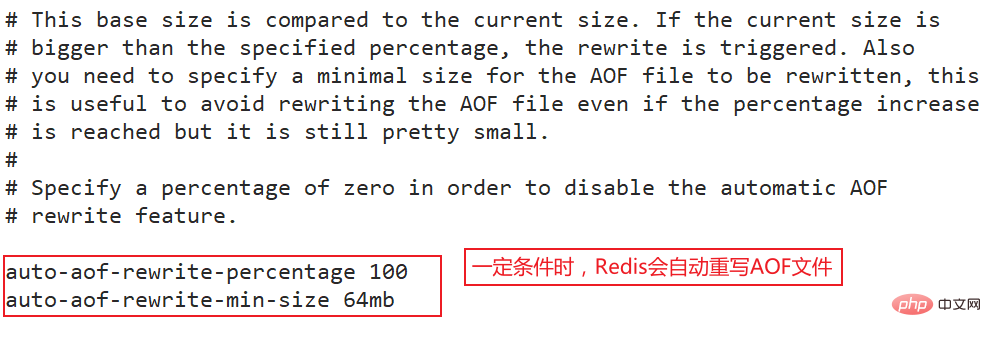
实际上Redis也正是这样做的,每当达到一定的条件时Redis就会自动重写AOF文件,这个条件可以通过redis.conf配置文件中设置:
auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb
在启动时Redis会逐行执行AOF文件中的命令将硬盘中的数据加载到内存中,加载的速度相比RDB会慢一些。
虽然每次执行更改数据库内容的操作时,AOF都将命令记录在AOF文件中。但事实上,由于操作系统的缓存机制,数据并没与真正写入硬盘,而是进入了操作系统的硬盘缓存。在默认情况下,操作系统每30秒会执行一次同步操作,以便将硬盘缓存中的内容写入硬盘。
在Redis中可以通过appendfsync设置同步的时机:
# appendfsync always #默认设置为everysecappendfsync everysec # appendfsync no
Redis允许同时开启AOF和RDB。这样既保证了数据的安全,又对进行备份等操作比较友好。此时重新启动Redis后,会使用AOF文件来恢复数据。因为AOF方式的持久化,将会丢失数据的概率降至最小化。
通过持久化功能,Redis保证了即使服务器重启的情况下也不会丢失(少部分遗失)数据。但是数据库是存储在单台服务器上的,难免不会发生各种突发情况,比如硬盘故障,服务器突然宕机等等,也会导致数据遗失。
为了尽可能的避免故障,通常做法是将数据库复制多个副本以部署在不同的服务器上。这样即使有一台出现故障,其它的服务器依旧可以提供服务。为此,Redis提供了复制(replication)功能。即实现一个数据库中的数据更新后,自动将更新的数据同步到其它数据库上。
此时熟悉MySQL的同学,是不是觉得与MySQL的主从复制很像,以开启二进制日志binlog实现同步复制。
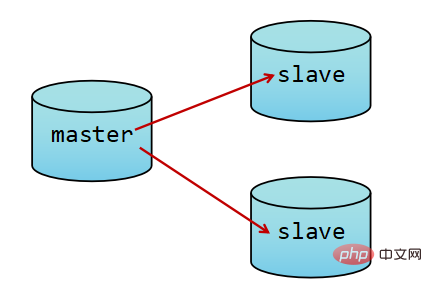
而Redis中使用复制功能更为容易,相比MySQL而言。只需要在从库中启动时加入slaveof从数据库地址。
#在从库中配置slaveof master_database_ip_addr #测试,加了nohup与&是放入后台,并且输出日志到/root/目录下的nohup.outnohup /opt/redis-6.0.8/src/redis-server --6380 --slaveof 192.168.245.147 6379 &

复制初始化。这里主要原理是从库启动,会向主库发送SYNC命令。同时主库接收到SYNC命令后会开始在后台保存快照,即RDB持久化的过程,并将快照期间接收的命令缓存起来。当快照完成后,Redis会将快照文件和所有缓存的命令发送给从数据库。从数据库收到后,会载入快照文件并执行收到的缓存命令。
复制同步阶段会贯穿整个主从同步过程,直到主从关系终止为止。在复制的过程中快照起到了至关重要的作用,只要执行复制就会进行快照,即使关闭了RDB方式的持久化,通过删除所有save参数。
Redis采用了乐观复制(optimistic replication)的复制策略。容忍在一定时间内主从数据库的内容是不同的,但是两者的数据最终是会同步的。具体来讲,Redis在主从数据库之间复制数据的过程本身是异步的,这就意味着,主数据库执行完客户端请求的命令会立即将命令在主数据库的执行结果反馈给客户端,并异步的将数据同步给从库,不会等待从数据库接收到该命令在返回给客户端。
当数据至少同步给指定数量的从库时,才是可写,通过参数指定:
#设置最少限制3min-slaves-to-write 3 #设置允许从数据最长失去连接时间min-slaves-max-lag 10
基于以下三点实现
当主数据库崩溃时,情况略微复杂。手动通过从数据库数据库恢复主库数据时,需要严格遵循以下原则:
SLAVEOF NO ONE命令将从库提升为主库继续服务。SLAVEOF命令将其设置为新的主库的从库。注意:当开启复制且数据库关闭持久化功能时,一定不要使用supervisor以及类似的进程管理工具令主库崩溃后重启。同样当主库所在的服务器因故障关闭时,也要避免直接重新启动。因为当主库重启后,没有开启持久化功能,数据库中所有数据都被清空。此时从库依然会从主库中接收数据,从而导致所有从库也被清空,导致数据库的持久化开了个寂寞。
手动维护确实很麻烦,好在Redis提供了一种自动化方案:哨兵去实现这一过程,避免手动维护易出错的问题。
从Redis的复制历中,我们了解到在一个典型的一主多从的Redis系统中,从库在整个系统中起到了冗余备份以及读写分离的作用。当主库遇到异常中断服务后,开发人员手动将从升主时,使系统继续服务。过程相对复杂,不好实现自动化。此时可借助哨兵工具。
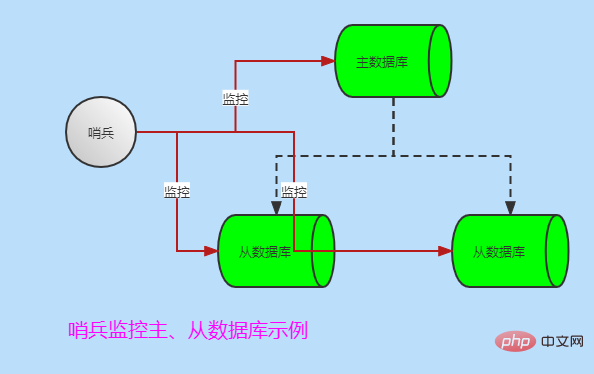
哨兵的作用
当然也有多个哨兵监控主从数据库模式,哨兵之间也会互相监控,如下图:

首先需要建立起一主多从的模型,然后开启配置哨兵。
#主库sentinel monitor master 127.0.0.1 6379 1 #建立配置文件,例如sentinel.confredis-sentinel /opt/path/to/sentinel.conf
关于哨兵就介绍这么多,现在大脑中有印象。至少知道有那么回事,可以和美女面试官多掰扯掰扯。
从Redis3.0开始加入了集群这一特性。
即使使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用内存最小的数据库节点,继而出现木桶效应。正因为Redis所有数据都是基于内存存储,问题已经很突出,尤其是当Redis作为持久化存储服务时。
有这样一种场景。就扩容来说,在客户端分片后,如果像增加更多的节点,需要对数据库进行手动迁移。迁移的过程中,为了保证数据的一致性,需要将进群暂时下线,相对比较复杂。
此时考虑到Redis很小,啊不口误,是轻量的特点。可以采用预分片(presharding)在一定程度上避免问题的出现。换句话说,就是在部署的初期,提前考虑日后的存储规模,建立足够多的实例。
从上面的理论知识来看,哨兵和集群类似,但哨兵和集群是两个独立的功能。如果要进行水平扩容,集群是不错的选择。
配置集群,开启配置文件redis.conf中的cluster-enabled
cluster-enabled yes

配置集群每个节点配置不同工作目录,或者修改持久化文件
cluster-config-file nodes-6379.conf
集群测试大家可以执行配置,参考其他书籍亦可,实现并不难。只要是知其原理。
示例
package com.jedis;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class Test { @org.junit.Test public void demo() { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.set("name", "sky"); String params = jedis.get("jedis"); System.out.println(params); jedis.close(); } @org.junit.Test public void config() { // 获取连接池的配置对象 JedisPoolConfig config = new JedisPoolConfig(); // 设置最大连接数 config.setMaxTotal(30); // 设置最大空闲连接数 config.setMaxIdle(10); // 获取连接池 JedisPool pool = new JedisPool(config, "127.0.0.1", 6379); // 获得核心对象 Jedis jedis = null; try { //通过连接池获取连接 jedis = pool.getResource(); //设置对象 jedis.set("poolname", "pool"); //获取对象 String pools = jedis.get("poolname"); System.out.println("values:"+pools); } catch (Exception e) { e.printStackTrace(); }finally{ //释放资源 if(jedis != null){ jedis.close(); } if(pool != null){ pool.close(); } } }}
最后放一个制作很粗超的思维导图。
推荐学习:《Redis视频教程》、《2022最新redis面试题大全及答案》
Das obige ist der detaillierte Inhalt vonEingehende Analyse des Redis-Einstiegs in die Praxis und der Persistenz (Zusammenfassungsfreigabe). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken? Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis? So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher? Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen? Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?


























