


Python-Webcrawler-Schritte: Bereiten Sie zuerst die erforderlichen Bibliotheken vor und schreiben Sie den Crawler-Planer. Schreiben Sie dann den URL-Manager und den Webseiten-Downloader.

Die Betriebsumgebung dieses Tutorials: Windows 7-System, Python-Version 3.9, DELL G3-Computer.
Python-Webcrawler-Schritte
(1) Bereiten Sie die erforderlichen Bibliotheken vor
Wir müssen eine Open-Source-Bibliothek namens BeautifulSoup (Webseitenanalyse) vorbereiten, um die heruntergeladene Webseite zu analysieren, die wir verwenden. Es handelt sich um eine PyCharm-Kompilierungsumgebung , sodass Sie die Open-Source-Bibliothek direkt herunterladen können.
Die Schritte sind wie folgt:
Select File- & Gt; Einstellungen
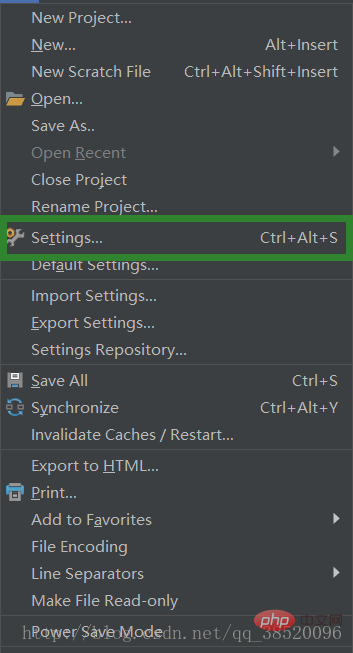
Open
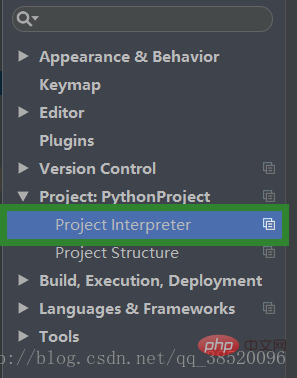
Open
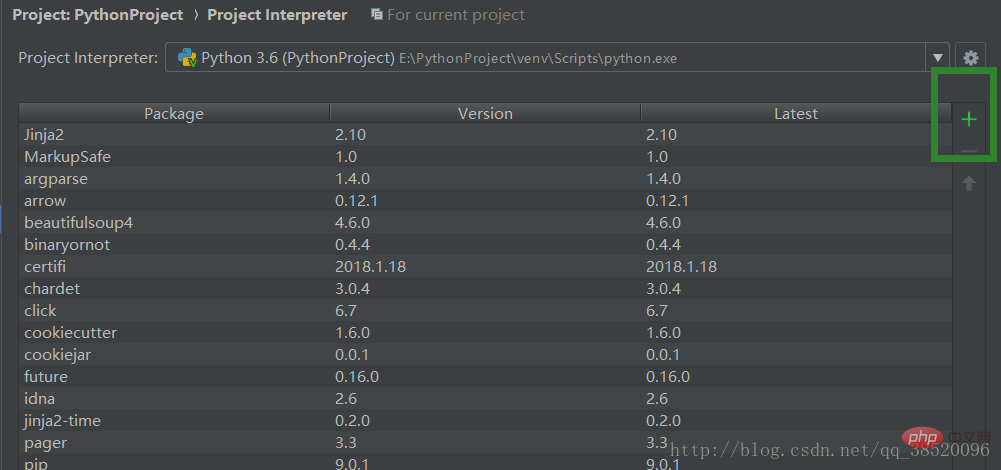
Open des Projektinterpreter Wählen Sie bs4 aus. Klicken Sie auf „Install Packge Download“ (Paket herunterladen). Parser, URL-Ausgabegerät.
# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)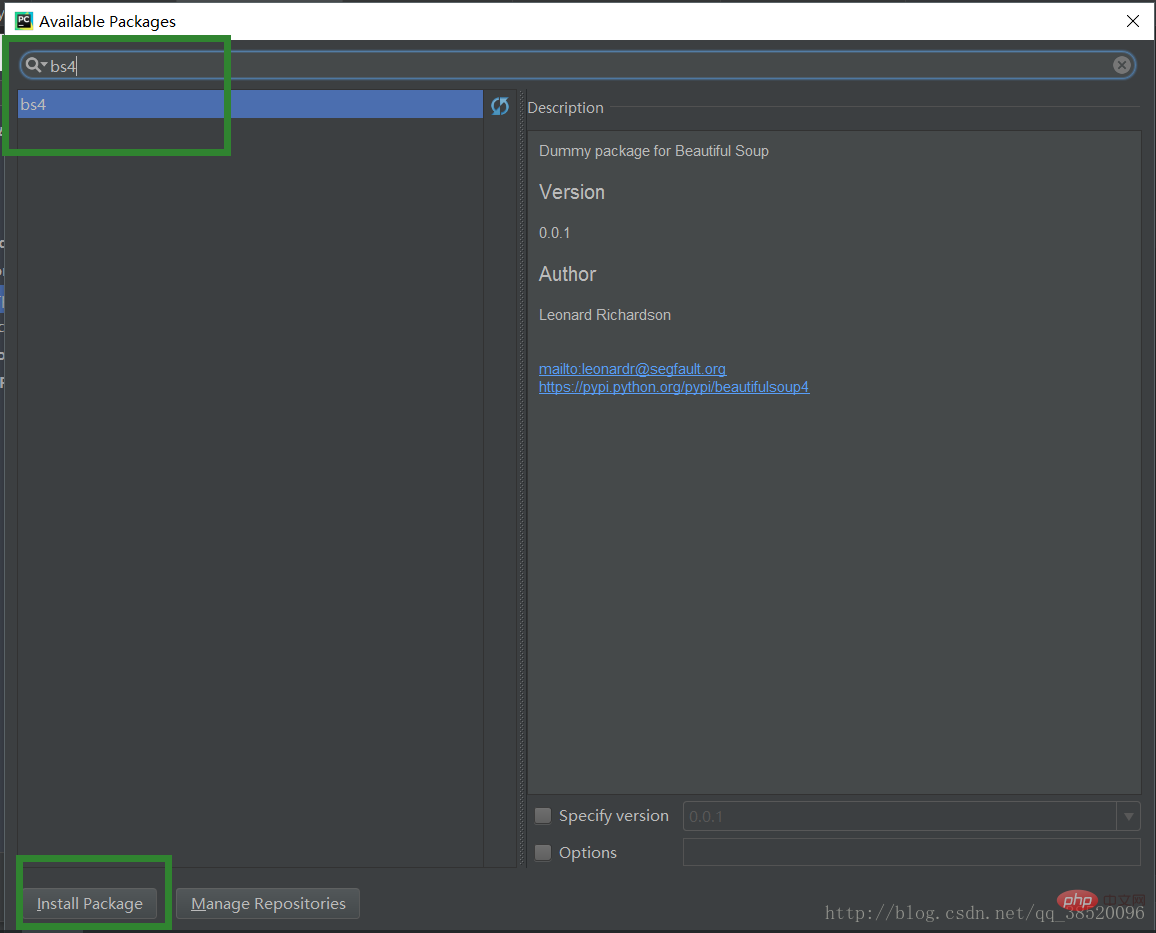 (3) URL-Manager schreiben
(3) URL-Manager schreiben
Wir speichern gecrawlte und nicht gecrawlte URLs getrennt, damit wir einige Webseiten, die bereits gecrawlt wurden, nicht wiederholt crawlen.
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0(4) Schreiben Sie einen Webseiten-Downloader.
Laden Sie die Seite über eine Netzwerkanforderung herunter.# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()Beim Parsen einer Webseite müssen wir wissen, welchen Inhalt sie hat Welche Merkmale wir abfragen möchten, können wir eine Webseite öffnen, mit der rechten Maustaste klicken und die Elemente untersuchen, um zu verstehen, was der gesuchte Inhalt gemeinsam hat.
# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("p", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls(6) Schreiben Sie einen Webseiten-Ausgabeautomaten
Es gibt viele Ausgabeformate. Wir entscheiden uns für die Ausgabe in HTML-Form, damit wir eine HTML-Seite erhalten können.
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("<html>")
fout.write("<meta charset='utf-8'>")
fout.write("<body>")
# 以表格输出
fout.write("<table>")
for data in self.datas:
# 一行
fout.write("<tr>")
# 每个单元行的内容
fout.write("<td>%s</td>" % data["url"])
fout.write("<td>%s</td>" % data["title"])
fout.write("<td>%s</td>" % data["summary"])
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
# 输出完毕后一定要关闭输出器
fout.close()Verwandte kostenlose Lernempfehlungen:
Python-Video-Tutorial
Das obige ist der detaillierte Inhalt vonWas sind die Schritte des Python-Webcrawlers?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



