


Empfohlen (kostenlos): SQL
Zero, Datenbanktreiber
1. Datenbankverbindungspool
3. Der Abfrageparser
4. MySQL-Abfrageoptimierer
IO-Kosten
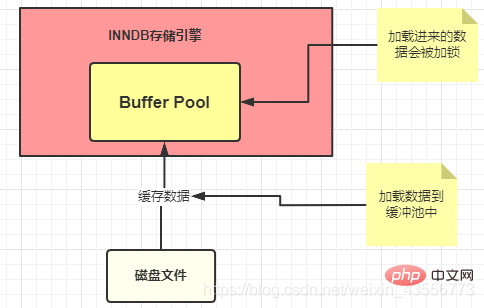
: das heißt, das Laden von Daten von der Festplatte Die Speicherkosten betragen standardmäßig 1. MySQL liest Daten in Form von Seiten. Das heißt, wenn bestimmte Daten verwendet werden, werden diese Daten nicht nur gelesen Lesen Sie auch in den Speicher neben den Daten. Dies ist das berühmte Prinzip der Programmlokalität, sodass MySQL jedes Mal eine ganze Seite liest und die Kosten für eine Seite 1 betragen. Daher hängen die IO-Kosten hauptsächlich mit der Größe der Seite zusammen.Jedes Mal, wenn SQL ausgeführt wird, werden die Daten in den Speicher geladen: Pufferpool
8. Drei Protokolldateien
: Das Erscheinungsbild der Daten aufzeichnen, bevor sie geändert werden 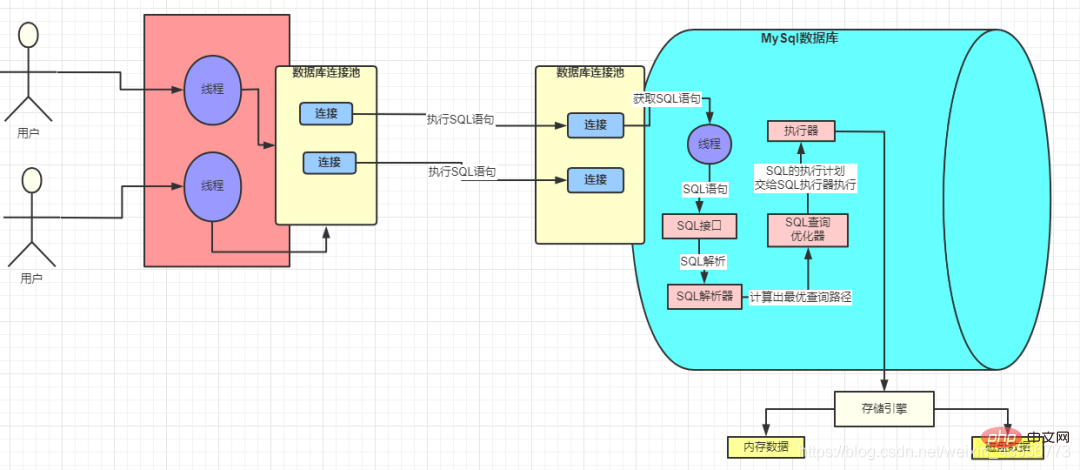
Funktion: Protokolldateien rückgängig machen, um das Transaktions-Rollback abzuschließen
 Redo zeichnet den Wert nach der Datenänderung auf. Unabhängig davon, ob die Transaktion übermittelt wird oder nicht, wird sie aufgezeichnet
Redo zeichnet den Wert nach der Datenänderung auf. Unabhängig davon, ob die Transaktion übermittelt wird oder nicht, wird sie aufgezeichnet
3. Bin-Protokolldatei: Zeichnen Sie den gesamten Vorgang auf
Eigenschaften: Redo-Log log kann übergeben werden. Der Konfigurationsparameter max_bin log_size legt die Größe jeder bin log-Datei fest (es wird jedoch im Allgemeinen nicht empfohlen, sie zu ändern). |
Implementierungsmethode | |
|---|---|---|
| bin-Protokoll wird durch Anhängen aufgezeichnet. Wenn die Dateigröße größer als der angegebene Wert ist, werden nachfolgende Protokolle in neuen Dateien aufgezeichnet. | Nutzungsszenarien. max_bin log_size设置每个bin log文件的大小(但是一般不建议修改)。 |
|
| 实现方式 |
redo log是InnoDB引擎层实现的(也就是说是 Innodb 存储引起过独有的) |
bin log是 MySQL 层实现的,所有引擎都可以使用 bin log日志 |
| 记录方式 | redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 | bin log 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 使用场景 |
redo log适用于崩溃恢复(crash-safe)(这一点其实非常类似与 Redis 的持久化特征) |
bin log |
Das obige ist der detaillierte Inhalt vonAusführung einer SQL-Anweisung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Datenanalysetools gibt es?
Welche Datenanalysetools gibt es?
 Verwendung von „distinct' in SQL
Verwendung von „distinct' in SQL
 So verwenden Sie „months_between' in SQL
So verwenden Sie „months_between' in SQL
 SQL 5120-Fehlerlösung
SQL 5120-Fehlerlösung
 Lösung für den Syntaxfehler der SQL-Prozedur
Lösung für den Syntaxfehler der SQL-Prozedur
 Oracle-Datenbank, die die SQL-Methode ausführt
Oracle-Datenbank, die die SQL-Methode ausführt
 Die Bedeutung von where in SQL
Die Bedeutung von where in SQL
 Was ist die Anweisung zum Löschen einer Tabelle in SQL?
Was ist die Anweisung zum Löschen einer Tabelle in SQL?










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



