



Ein Prozess ist die Startinstanz einer Anwendung. Unabhängige Dateiressourcen, Datenressourcen und Speicherplatz.
Threads gehören zu Prozessen und sind die Ausführer von Programmen. Ein Prozess enthält mindestens einen Hauptthread und kann auch mehrere untergeordnete Threads haben. Für Threads gibt es zwei Planungsstrategien: eine ist Time-Sharing-Planung und die andere ist präventive Planung.
Meine offizielle Pinguingruppe
Coroutinen sind leichte Threads, Coroutinen gehören auch zu Threads und Coroutinen werden in Threads ausgeführt. Die Planung von Coroutinen wird vom Benutzer manuell umgeschaltet und wird daher auch als User-Space-Thread bezeichnet. Das Erstellen, Umschalten, Anhalten und Zerstören von Coroutinen sind allesamt Speichervorgänge, und der Verbrauch ist sehr gering. Die Planungsstrategie von Coroutinen ist: kollaborative Planung.
Swoole4 ist Single-Threaded und Multi-Prozess, und es wird nur eine Coroutine gleichzeitig im selben Prozess ausgeführt.
Der Swoole-Server empfängt Daten und löst den onReceive-Rückruf im Arbeitsprozess aus, um einen Ctrip zu generieren. Swoole erstellt für jede Anfrage einen entsprechenden Ctrip. In Coroutinen können auch Sub-Coroutinen erstellt werden.
Die zugrunde liegende Implementierung der Coroutine ist Single-Threaded, sodass nur eine Coroutine gleichzeitig arbeitet und die Ausführung der Coroutine seriell erfolgt.
Wenn also Multitasking und Multi-Coroutine ausgeführt werden und eine Coroutine ausgeführt wird, funktionieren andere Coroutinen nicht mehr. Die aktuelle Coroutine bleibt hängen, wenn blockierende E/A-Vorgänge ausgeführt werden, und der zugrunde liegende Scheduler tritt in die Ereignisschleife ein. Wenn ein E/A-Abschlussereignis auftritt, nimmt der zugrunde liegende Scheduler die Ausführung der dem Ereignis entsprechenden Coroutine wieder auf. . Daher haben Coroutinen keinen E/A-Zeitverbrauch und eignen sich sehr gut für E/A-Szenarien mit hoher Parallelität. (Wie im Bild unten gezeigt)
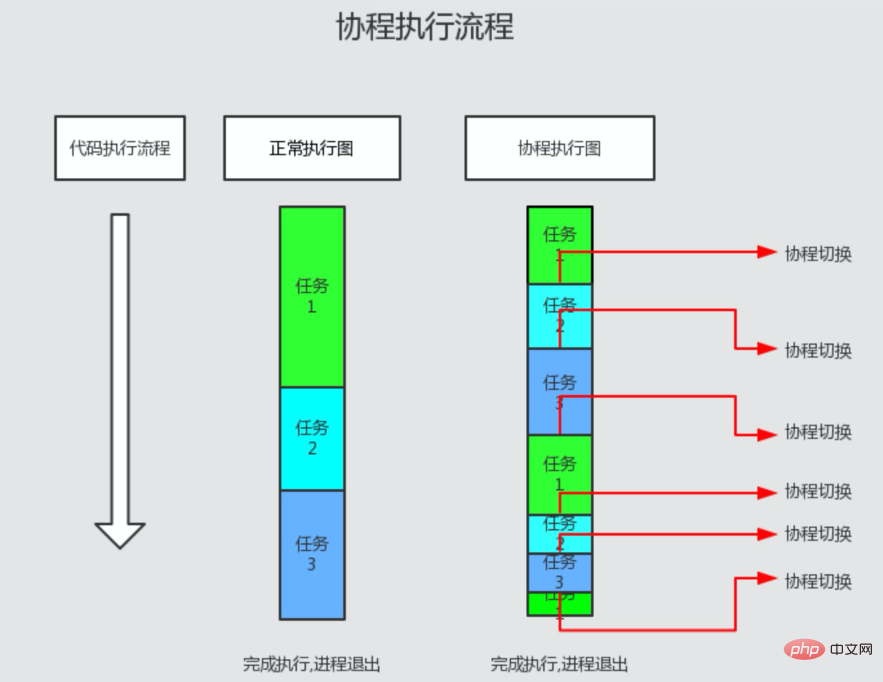
Die Coroutine hat keine E/A und wartet auf die normale Ausführung des PHP-Codes, und es findet kein Wechsel des Ausführungsflusses statt
Die Coroutine trifft auf E/A und wartet auf sofortige Steuerung. Rechtsschnitt. Nachdem die E/A abgeschlossen ist, wechseln Sie den Ausführungsfluss zurück zu dem Punkt, an dem die ursprüngliche Coroutine ausgeschnitten wurde eins
Der verschachtelte Ausführungsprozess der Coroutine von außen nach innen tritt ein, bis IO auftritt, und wechselt dann zur äußeren Coroutine. Die übergeordnete Coroutine wartet nicht auf das Ende der untergeordneten Coroutine. Die Ausführungssequenz der Coroutine
go(function () {
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";}); go() ist die Abkürzung von Co::create(), die zum Erstellen einer Coroutine verwendet wird und akzeptieren Sie den Rückruf als Parameter.
SwooleCoroutine kann als Co
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello go1 hello main hello go2
Das Ausführungsergebnis scheint sich nicht von der Reihenfolge zu unterscheiden, in der wir normalerweise Code schreiben. Tatsächlicher Ausführungsprozess:
go() 是 Co::create() 的缩写, 用来创建一个协程, 接受 callback 作为参数, callback 中的代码, 会在这个新建的协程中执行.
备注: SwooleCoroutine 可以简写为 Co
上面的代码执行结果:
// co.php<?phpsleep (100);
执行结果和我们平时写代码的顺序, 好像没啥区别. 实际执行过程:
运行此段代码, 系统启动一个新进程
遇到 go(), 当前进程中生成一个协程, 协程中输出 heelo go1, 协程退出
进程继续向下执行代码, 输出 hello main
再生成一个协程, 协程中输出heelo go2, 协程退出
运行此段代码, 系统启动一个新进程. 如果不理解这句话, 你可以使用如下代码:
root@b98940b00a9b /v/w/c/p/swoole# php co.php &⏎ root@b98940b00a9b /v/w/c/p/swoole# ps auxPID USER TIME COMMAND 1 root 0:00 php -a 10 root 0:00 sh 19 root 0:01 fish 749 root 0:00 php co.php 760 root 0:00 ps aux ⏎
执行并使用 ps aux 查看系统中的进程:
use Co;go(function () {
Co::sleep(1); // 只新增了一行代码
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});我们来稍微改一改, 体验协程的调度:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go2 hello go1
Co::sleep() 函数功能和 sleep() 差不多, 但是它模拟的是 IO等待(IO后面会细讲). 执行的结果如下:
go(function () {
Co::sleep(1);
echo "hello go1 \n";});echo "hello main \n";go(function () {
Co::sleep(1);
echo "hello go2 \n";});怎么不是顺序执行的呢? 实际执行过程:
go(), 当前进程中生成一个协程Co::sleep() 模拟出的 IO等待), 协程让出控制, 进入协程调度队列hello main
hello go2
hello go1
trifft auf go(), eine Coroutine wird im aktuellen Prozess generiert und wird in der Coroutine ausgegeben. Heelo go1, die Coroutine wird beendet
heelo go2 in der Coroutine aus, die Coroutine wird beendet🎜🎜🎜🎜Führen Sie diesen Code aus und das System startet ein neues Prozess. Wenn Sie diesen Satz nicht verstehen, können Sie den folgenden Code verwenden: 🎜root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go1 hello go2 ⏎
ps aux Sehen Sie sich die Prozesse im System an: 🎜$n = 4;for ($i = 0; $i 🎜 Lassen Sie uns eine kleine Änderung vornehmen und erleben Die Planung von Coroutinen: 🎜<pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ⏎
Co::sleep() Function function und sleep() code> ist fast gleich, simuliert aber das IO-Warten (IO wird in besprochen). Details später). Die Ausführungsergebnisse sind wie folgt: 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;go(function () use ($n) {
for ($i = 0; $i 🎜Warum wird es nicht nacheinander ausgeführt? /code>, und im aktuellen Prozess wird eine Coroutine generiert 🎜🎜Die Coroutine stößt auf eine E/A-Blockierung (hier ist <code>Co::sleep()</code> simuliertes E/A-Warten), die Coroutine gibt die Kontrolle auf und tritt in die Coroutine ein Planungswarteschlange 🎜🎜Der Prozess wird weiter nach unten ausgeführt, gibt <code>hello main</code> aus 🎜🎜führt die nächste Coroutine aus und gibt <code>hello go2 code> aus 🎜🎜Die vorherige Coroutine ist bereit, fahren Sie mit der Ausführung fort, und Ausgabe <code>hello go1</code>🎜🎜🎜An diesem Punkt können wir bereits die Beziehung zwischen der Coroutine und dem Prozess in Swoole sowie die Planung der Coroutine sehen. Wir ändern das Programm gerade:🎜 <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s
user 0m 0.00s
sys 0m 0.02s
⏎</pre><div class="contentsignin">Nach dem Login kopieren</div></div>🎜Ich denke, Sie wissen bereits, wie die Ausgabe aussieht:🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main
hello go1
hello go2
⏎</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>
<h2>协程快在哪? 减少IO阻塞导致的性能损失</h2>
<p>大家可能听到使用协程的最多的理由, 可能就是 协程快. 那看起来和平时写得差不多的代码, 为什么就要快一些呢? 一个常见的理由是, 可以创建很多个协程来执行任务, 所以快. 这种说法是对的, 不过还停留在表面.</p>
<p>首先, 一般的计算机任务分为 2 种:</p>
<ul>
<li>CPU密集型, 比如加减乘除等科学计算</li>
<li>
<li>IO 密集型, 比如网络请求, 文件读写等</li>
</ul>
<p>其次, 高性能相关的 2 个概念:</p>
<ul>
<li>并行: 同一个时刻, 同一个 CPU 只能执行同一个任务, 要同时执行多个任务, 就需要有多个 CPU 才行</li>
<li>
<li>并发: 由于 CPU 切换任务非常快, 快到人类可以感知的极限, 就会有很多任务 同时执行 的错觉</li>
</ul>
<p>了解了这些, 我们再来看协程, 协程适合的是 IO 密集型 应用, 因为协程在 IO阻塞 时会自动调度, 减少IO阻塞导致的时间损失.</p>
<p>我们可以对比下面三段代码:</p>
<ul><li>普通版: 执行 4 个任务</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main
real 0m 4.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><div class="contentsignin">Nach dem Login kopieren</div></div></pre>
<ul><li>单个协程版:</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;go(function () use ($n) {
for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s
user 0m 0.00s
sys 0m 0.02s
⏎</pre><div class="contentsignin">Nach dem Login kopieren</div></div></pre>
<ul><li>多协程版: 见证奇迹的时刻</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965245.5491: hello 01528965245.5498: hello 31528965245.5502: hello 21528965245.5506: hello 1real 0m 1.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><div class="contentsignin">Nach dem Login kopieren</div></div><p>为什么时间有这么大的差异呢:</p></pre>
<ul>
<li><p>普通写法, 会遇到 IO阻塞 导致的性能损失</p></li>
<li><p>单协程: 尽管 IO阻塞 引发了协程调度, 但当前只有一个协程, 调度之后还是执行当前协程</p></li>
<li><p>多协程: 真正发挥出了协程的优势, 遇到 IO阻塞 时发生调度, IO就绪时恢复运行</p></li>
</ul>
<p>我们将多协程版稍微修改一下:</p>
<ul><li>多协程版2: CPU密集型</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965743.4327: hello 01528965744.4331: hello 11528965745.4337: hello 21528965746.4342: hello 3hello main
real 0m 4.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><div class="contentsignin">Nach dem Login kopieren</div></div><p>只是将 <code>Co::sleep() 改成了 sleep(), 时间又和普通版差不多了. 因为:
sleep() 可以看做是 CPU密集型任务, 不会引起协程的调度
Co::sleep() 模拟的是 IO密集型任务, 会引发协程的调度
这也是为什么, 协程适合 IO密集型 的应用.
再来一组对比的例子: 使用 redis
// 同步版, redis使用时会有 IO 阻塞$cnt = 2000;for ($i = 0; $i connect('redis');
$redis->auth('123');
$key = $redis->get('key');}// 单协程版: 只有一个协程, 并没有使用到协程调度减少 IO 阻塞go(function () use ($cnt) {
for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
}});// 多协程版, 真正使用到协程调度带来的 IO 阻塞时的调度for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
});}性能对比:
# 多协程版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 0.54s user 0m 0.04s sys 0m 0.23s ⏎# 同步版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 1.48s user 0m 0.17s sys 0m 0.57s ⏎
接触过 go 协程的 coder, 初始接触 swoole 的协程会有点 懵, 比如对比下面的代码:
package main
import (
"fmt"
"time")func main() {
go func() {
fmt.Println("hello go")
}()
fmt.Println("hello main")
time.Sleep(time.Second)}> 14:11 src $ go run test.go hello main hello go
刚写 go 协程的 coder, 在写这个代码的时候会被告知不要忘了 time.Sleep(time.Second), 否则看不到输出 hello go, 其次, hello go与 hello main 的顺序也和 swoole 中的协程不一样.
原因就在于 swoole 和 go 中, 实现协程调度的模型不同.
上面 go 代码的执行过程:
package main, 然后执行其中的 func mian()
hello main
time.Sleep(time.Second), main 函数执行完, 程序结束, 进程退出, 导致调度中的协程也终止go 中的协程, 使用的 MPG 模型:
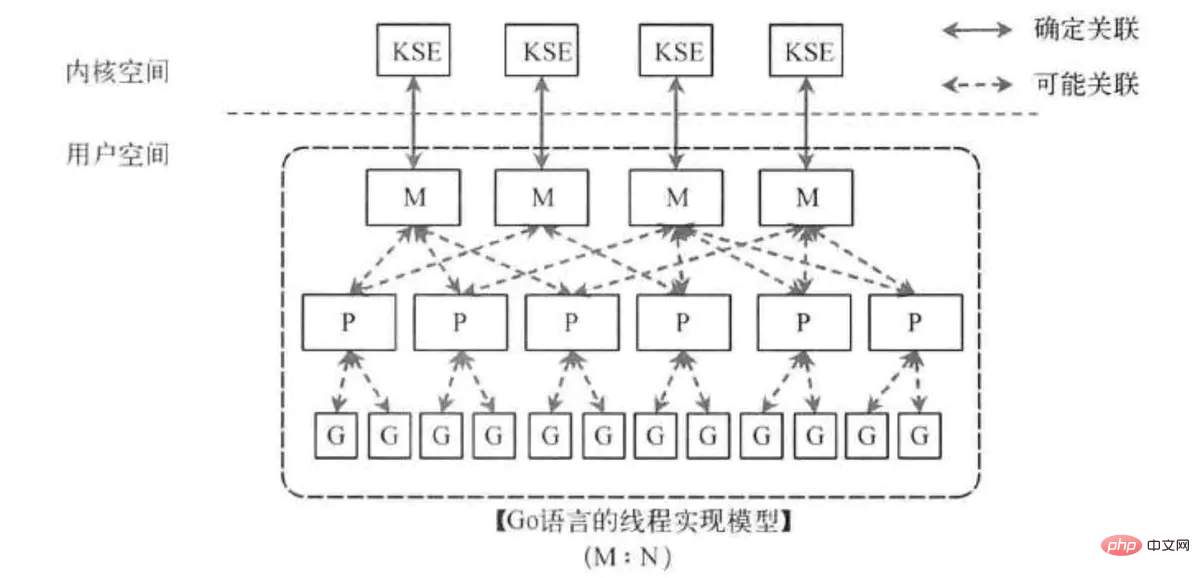
而 swoole 中的协程调度使用 单进程模型, 所有协程都是在当前进程中进行调度, 单进程的好处也很明显 – 简单 / 不用加锁 / 性能也高.
无论是 go 的 MPG模型, 还是 swoole 的 单进程模型, 都是对 CSP理论 的实现.
Das obige ist der detaillierte Inhalt vonAls ich von der Swoole-Coroutine dreimal gefragt wurde, hätte ich fast geweint!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So erstellen Sie ein HTML-Projekt mit vscode
So erstellen Sie ein HTML-Projekt mit vscode
 Software für virtuelle Maschinen
Software für virtuelle Maschinen
 Top 10 Kryptowährungs-Handels-Apps
Top 10 Kryptowährungs-Handels-Apps
 Die Beziehung zwischen Bandbreite und Netzwerkgeschwindigkeit
Die Beziehung zwischen Bandbreite und Netzwerkgeschwindigkeit
 Verwendung der Matlab-Colormap-Funktion
Verwendung der Matlab-Colormap-Funktion
 So verwenden Sie RealVNC
So verwenden Sie RealVNC
 Zu welcher Währung gehört USDT?
Zu welcher Währung gehört USDT?
 So machen Sie Screenshots auf dem Huawei mate60pro
So machen Sie Screenshots auf dem Huawei mate60pro








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



