


 Was den Join von MySQL angeht, müssen Sie viele seiner „Anekdoten“ kennen. Beispielsweise ist für einen Join mit zwei Tabellen eine kleine Tabelle erforderlich, um eine große Tabelle zu steuern. Die Alibaba-Entwicklerspezifikationen verbieten Join-Vorgänge für mehr als drei Tabellen . MySQLs Join-Funktion ist zu schwach und so weiter. Diese Normen oder Bemerkungen können wahr oder falsch sein, manchmal richtig oder manchmal falsch. Um es klar zu verstehen, müssen Sie über ein umfassendes Verständnis von Join verfügen.
Was den Join von MySQL angeht, müssen Sie viele seiner „Anekdoten“ kennen. Beispielsweise ist für einen Join mit zwei Tabellen eine kleine Tabelle erforderlich, um eine große Tabelle zu steuern. Die Alibaba-Entwicklerspezifikationen verbieten Join-Vorgänge für mehr als drei Tabellen . MySQLs Join-Funktion ist zu schwach und so weiter. Diese Normen oder Bemerkungen können wahr oder falsch sein, manchmal richtig oder manchmal falsch. Um es klar zu verstehen, müssen Sie über ein umfassendes Verständnis von Join verfügen.
Werfen wir nun einen umfassenden Blick auf den Join-Vorgang von MySQL.
Text
Beim MySQL-Join gibt es viele Regeln. Wenn Sie nicht aufpassen, kann eine fehlerhafte Join-Anweisung nicht nur eine vollständige Tabellenabfrage einer bestimmten Tabelle verursachen, sondern auch den Cache der Datenbank beeinträchtigen, was zu den meisten Daten-Hotspots führt ersetzt, was die gesamte Datenbankleistung beeinträchtigt.
Daher hat die Branche viele Normen oder Prinzipien für MySQL-Joins zusammengefasst, wie z. B. kleine Tabellen, die große Tabellen steuern, und das Verbot von Join-Vorgängen für mehr als drei Tabellen. Im Folgenden stellen wir der Reihe nach den MySQL-Join-Algorithmus vor, vergleichen ihn mit der Join-Implementierung von Oracle und Spark und geben Antworten darauf, warum die oben genannten Normen oder Prinzipien gebildet werden.
Für die Implementierung von Join-Operationen gibt es wahrscheinlich drei weitere gängige Algorithmen: Nested Loop Join, Hash Join und Sort Merge Join, von denen jeder seine eigenen Vor- und Nachteile sowie anwendbaren Bedingungen hat, die wir der Reihe nach vorstellen werden nächste.
Implementierung von Nested Loop Join in MySQLNested Loop Join scannt die Treibertabelle. Jedes Mal, wenn ein Datensatz gelesen wird, werden die entsprechenden Daten in der gesteuerten Tabelle entsprechend dem Index im zugehörigen Feld des Joins abgefragt. Es eignet sich für Szenarien, in denen die zu verbindende Teilmenge klein ist. Es ist auch die einzige Algorithmusimplementierung von MySQL. Wir werden die Details im Folgenden erläutern.
Index Nested-Loop Join-Algorithmus
Als nächstes initialisieren wir die relevante Tabellenstruktur und die Daten
CREATE TABLE `t1` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`) ) ENGINE=InnoDB; delimiter ;; # 定义存储过程来初始化t1 create procedure init_data() begin declare i int; set i=1; while(i<h4 data-id="heading-2">Aus dem obigen Befehl können wir sehen, dass beide Tabellen eine Primärschlüssel-Index-ID und einen Index a haben und es kein Feld gibt b-Index. Die gespeicherte Prozedur init_data fügt 10.000 Datenzeilen in Tabelle t1 und 500 Datenzeilen in Tabelle t2 ein. </h4><p>Um zu verhindern, dass der MySQL-Optimierer die Tabelle als treibende Tabelle auswählt und den Ausführungsprozess der Analyse von SQL-Anweisungen beeinträchtigt, verwenden wir direkt Straight_Join, damit MySQL eine feste Verbindungstabellenreihenfolge für die Abfrage verwenden kann. In der folgenden Anweisung ist t1 der Fahrtisch und t2 ist der angetriebene Tisch. </p><pre class="brush:php;toolbar:false">select * from t2 straight_join t1 on (t2.a=t1.a);复制代码
Verwenden Sie den in unserem vorherigen Artikel eingeführten Befehl EXPLAIN, um den Ausführungsplan dieser Anweisung anzuzeigen.
Wie Sie im Bild oben sehen können, ist das Feld a in der Tabelle t1 indiziert und der Index wird im Join-Prozess verwendet, sodass der Ausführungsablauf der SQL-Anweisung wie folgt lautet: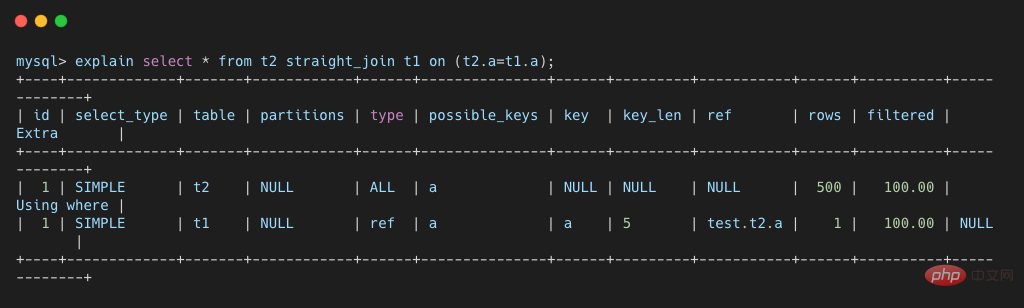
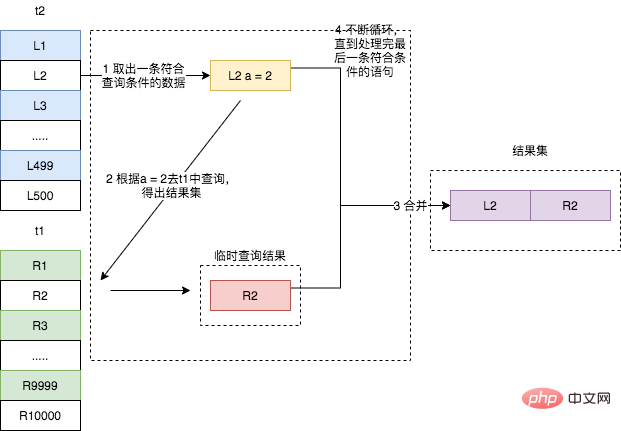 Angenommen, die Anzahl der Zeilen in der Treibertabelle beträgt N und die Anzahl der Zeilen in der Treibertabelle beträgt M. Denn während der Ausführung dieser Join-Anweisung führt die treibende Tabelle einen vollständigen Tabellenscan durch, während die getriebene Tabelle einen Index verwendet und jede Datenzeile in der treibenden Tabelle für die Indexabfrage in der getriebenen Tabelle indiziert werden muss, also der gesamte Join Die ungefähre Komplexität des Prozesses beträgt N
Angenommen, die Anzahl der Zeilen in der Treibertabelle beträgt N und die Anzahl der Zeilen in der Treibertabelle beträgt M. Denn während der Ausführung dieser Join-Anweisung führt die treibende Tabelle einen vollständigen Tabellenscan durch, während die getriebene Tabelle einen Index verwendet und jede Datenzeile in der treibenden Tabelle für die Indexabfrage in der getriebenen Tabelle indiziert werden muss, also der gesamte Join Die ungefähre Komplexität des Prozesses beträgt N
log2M. Offensichtlich hat N einen größeren Einfluss auf die Anzahl der gescannten Zeilen. In diesem Fall sollte daher eine kleine Tabelle als Treibertabelle verwendet werden.
Die Voraussetzung dafür ist natürlich, dass das zugehörige Feld der Verknüpfung a ist und es einen Index für das Feld a der Tabelle t1 gibt. 如果没有索引时,再用上图的执行流程时,每次到 t1 去匹配的时候,就要做一次全表扫描。这也导致整个过程的时间复杂度编程了 N * M,这是不可接受的。所以,当没有索引时,MySQL 使用 Block Nested-Loop Join 算法。 Block Nested-Loop Join的算法,简称 Ist die Join-Funktion von MySQL zu schwach?,它是 MySQL 在被驱动表上无可用索引时使用的 join 算法,其具体流程如下所示: 比如下面这条 SQL 这条语句的 explain 结果如下所示。可以看出 可以看出,这次 join 过程对 t1 和 t2 都做了一次全表扫描,并且将表 t2 中的 500 条数据全部放入内存 join_buffer 中,并且对于表 t1 中的每一行数据,都要去 join_buffer 中遍历一遍,都要做 500 次对比,所以一共要进行 500 * 10000 次内存对比操作,具体流程如下图所示。 主要注意的是,第一步中,并不是将表 t2 中的所有数据都放入 join_buffer,而是根据具体的 SQL 语句,而放入不同行的数据和不同的字段。比如下面这条 join 语句则只会将表 t2 中符合 b >= 100 的数据的 b 字段存入 join_buffer。 join_buffer 并不是无限大的,由 join_buffer_size 控制,默认值为 256K。当要存入的数据过大时,就只有分段存储了,整个执行过程就变成了: 这个流程体现了该算法名称中 Block 的由来,分块去执行 join 操作。因为表 t2 的数据被分成了 5 次存入 join_buffer,导致表 t1 要被全表扫描 5次。 Wie oben gezeigt, hat sich die Anzahl der Speicherbeurteilungen im Vergleich zu den Tabellendaten, die alle im join_buffer gespeichert werden können, nicht geändert. Es ist das Produkt der Zeilennummern der beiden Tabellen, das 10000 * 500 beträgt Die gesteuerte Tabelle wird jedes Mal mehrmals gescannt. Wenn Sie noch einmal speichern, muss die gesteuerte Tabelle erneut gescannt werden, was sich auf die endgültige Ausführungseffizienz auswirkt. Basierend auf den beiden oben genannten Algorithmen können wir die folgende Schlussfolgerung ziehen, die auch der Standard für die meisten MySQL-Join-Anweisungen im Internet ist. Es gibt einen Index für die gesteuerte Tabelle. Das heißt, wenn der Index Nested-Loop Join-Algorithmus verwendet werden kann, kann die Join-Operation verwendet werden. Ob es sich um einen Index Nested-Loop Join-Algorithmus oder einen Block Nested-Loop Join handelt, muss eine kleine Tabelle als Treibertabelle verwendet werden. Da die zeitliche Komplexität der beiden oben genannten Join-Algorithmen mindestens in einer Beziehung erster Ordnung zur Anzahl der Zeilen in den beteiligten Tabellen steht und viel Speicherplatz beansprucht, so die Alibaba-Entwicklerspezifikationen Drei Tabellen strikt verbieten Der obige Join-Vorgang ist ebenfalls verständlich. Aber die beiden oben genannten Algorithmen sind nur einer der Join-Algorithmen. Es gibt auch effizientere Join-Algorithmen wie Hash Join und Sorted Merged Join. Leider sind diese beiden Algorithmen derzeit nicht in der Mainstream-Version von MySQL enthalten, aber Oracle, PostgreSQL und Spark unterstützen sie alle. Aus diesem Grund sind Online-Beschwerden über MySQL so schwach (MySQL-Version 8.0 unterstützt Ist die Join-Funktion von MySQL zu schwach?, 8.0 jedoch noch nicht Mainstream-Version). Tatsächlich sahen die Alibaba-Entwicklerspezifikationen auch vor, dass bei der Migration von Oracle zu MySQL die Leistung des Join-Vorgangs von MySQL zu schlecht war, um den Join-Vorgang von mehr als drei Tabellen zu verhindern. Ist die Join-Funktion von MySQL zu schwach? scannt die Treibertabelle, verwendet die zugehörigen Felder des Joins, um eine Hash-Tabelle im Speicher zu erstellen, und scannt dann die gesteuerte Tabelle, liest jede Datenzeile aus und findet die entsprechenden Daten aus der Hash-Tabelle. Dies ist eine gängige Methode zum Verbinden großer Datensätze. Sie eignet sich für Szenarien, in denen die von der Tabelle gesteuerte Datenmenge gering ist und im Speicher abgelegt werden kann. Sie bietet die beste Leistung für „große Tabellen ohne Indizes“ und parallele Abfragen . . Leider gilt dies nur für Equi-Join-Szenarien, z. B. für a.id = where b.a_id. Es ist immer noch die Join-Anweisung der beiden oben genannten Tabellen. Der Ausführungsprozess ist wie folgt: Aufgrund der Eigenschaften von Hash kann dieser Algorithmus jedoch nur auf entsprechende Verbindungsszenarien angewendet werden, und dieser Algorithmus kann nicht in anderen Verbindungsszenarien verwendet werden. MySQL-TutorialBlock Nested-Loop Join
select * from t2 straight_join t1 on (t2.b=t1.b);复制代码
Nach dem Login kopieren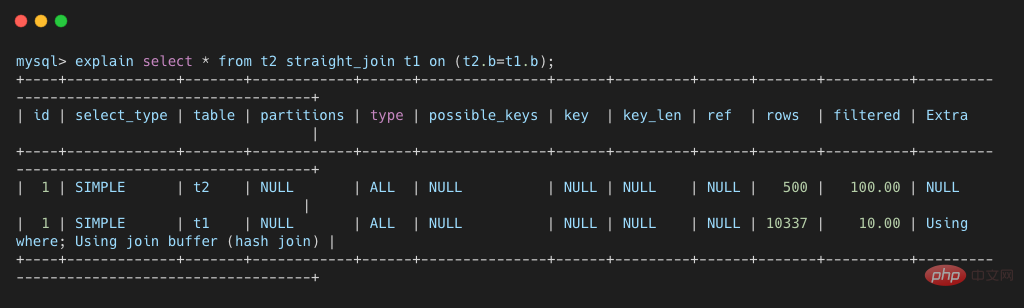
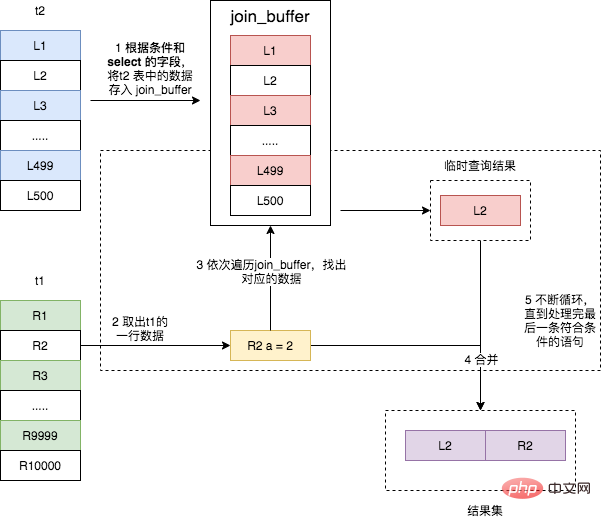
select t2.b,t1.b from t2 straight_join t1 on (t2.b=t1.b) where t2.b >= 100;复制代码
Nach dem Login kopieren
全部存入
分5次存入
内存操作
10000 * 500
10000 * (100 + 100 + 100 + 100 + 100)
扫描行数
10000 + 500
10000 * 5 + 500
Ist die Join-Funktion von MySQL zu schwach?-Algorithmus
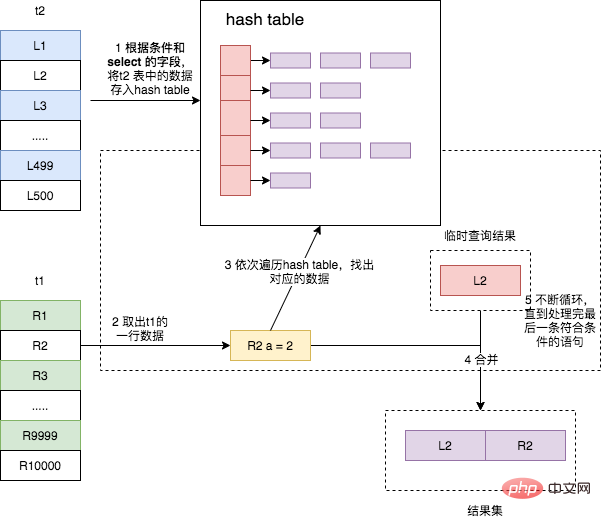
Dieser Algorithmus dem Block Nested-Loop Join ähnelt, mit der Ausnahme, dass der ungeordnete Join-Puffer in eine Hash-Tabelle geändert wird, sodass für den Datenabgleich nicht mehr die Daten im Join-Puffer erforderlich sind Indem wir alles einmal durchlaufen, können wir Hashing direkt verwenden, um die passenden Zeilen mit einer Zeitkomplexität nahe O(1) zu erhalten. Dies verbessert die Geschwindigkeit der Verknüpfung der beiden Tabellen erheblich. 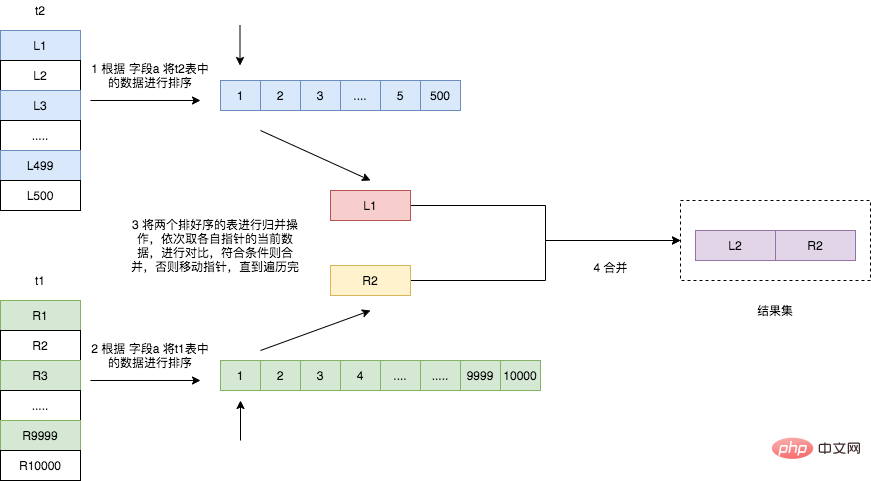 Traverse Tabelle t2, lies die Daten aus, die die Bedingungen erfüllen, und sortiere sie nach dem Wert des Verbindungsfelds a;
Traverse Tabelle t2, lies die Daten aus, die die Bedingungen erfüllen, und sortiere sie nach dem Wert des Verbindungsfelds a; Traverse Tabelle t1, lies die Daten aus, die die Bedingungen erfüllen, und sortiere sie entsprechend dem Wert des Verbindungsfelds a Sortieren;
Lassen Sie uns nun die Unterschiede, Vor- und Nachteile der oben genannten drei Algorithmen zusammenfassen.
Weitere verwandte kostenlose Lernempfehlungen:
Nested Loop Join
Hash Join
Sorted Merge Join
Verbrauch hauptsächlich RessourcenAnwendbar auf jede Bedingung
Nur anwendbar auf Equivalent Join (=)
Äquivalent oder nicht Verbindungen (>, =, '
FunktionenCPU, Festplatten-E/A
Speicher, temporärer Speicherplatz Speicher, temporärer Speicherplatz
Es ist effizienter, wenn ein hochselektiver Index oder eine restriktive Suche vorhanden ist, und es kann schnell die ersten Suchergebnisse zurückgeben.
Wenn ein Index fehlt oder die Indexbedingungen nicht eindeutig sind, ist Hash Join effektiver als Verschachtelte Schleife. Normalerweise schneller als Merge Join. In einer Data Warehouse-Umgebung ist die Effizienz hoch, wenn die Tabelle eine große Anzahl von Datensätzen enthält.
Wenn Indizes fehlen oder die Indexbedingungen nicht eindeutig sind, ist Sort Merge Join effektiver als Nested Loop. Wenn das Verbindungsfeld einen Index hat oder im Voraus sortiert ist, ist es schneller als ein Ist die Join-Funktion von MySQL zu schwach? und unterstützt mehr Verbindungsbedingungen Tabelle erfordert viel Speicher, Kapitel 1 Die einmalige Rückgabe von Ergebnissen ist langsamer
Alle Tabellen müssen sortiert werden. Es ist auf optimalen Durchsatz ausgelegt und gibt keine Daten zurück, bis alle Ergebnisse gefunden wurden.
Indizierung erforderlich Wenn wir über Join-bezogene Algorithmen sprechen, sprechen wir auch über das Geschäftsverständnis des Join-Vorgangs.
Wenn das Geschäft nicht komplex ist, sind die meisten Verknüpfungen nicht unersetzlich. Beispielsweise enthält der Bestelldatensatz im Allgemeinen nur die Benutzer-ID des Bestellbenutzers. Bei der Rückgabe von Informationen muss der Name des Benutzers abgerufen werden. Die möglichen Implementierungslösungen sind wie folgt:
Eine Datenbankoperation unter Verwendung der Join-Operation Tabelle und Benutzertabelle werden mit dem Benutzernamen zusammengeführt. Zwei Datenbankoperationen, zwei Abfragen, das erste Mal, um die Bestellinformationen und die Benutzer-ID abzurufen, das zweite Mal, um den Namen basierend auf der Benutzer-ID abzurufen, verwenden Sie den Code Programm zum Zusammenführen der Informationen; Verwenden Sie redundante Benutzernamen oder von ES usw. Lesen Sie aus einer nicht relationalen Datenbank.
Die oben genannten Lösungen können alle das Problem der Datenaggregation lösen und basieren auf Programmcode, der einfacher zu debuggen und zu optimieren ist als der Datenbankbeitritt. Beispielsweise wird der Benutzername nicht aus der Datenbank abgerufen, sondern an erster Stelle aus dem Cache gesucht.
Natürlich ist der Join-Vorgang nicht unbegründet, daher hat die Technologie ihre eigenen Nutzungsszenarien. Die oben genannten Lösungen oder Regeln werden vom Internet-Entwicklungsteam zusammengefasst und eignen sich für hohe Parallelität, leichtes Schreiben und starkes Lesen, Verteilen und einfaches Die Geschäftslogik stellt im Allgemeinen keine hohen Anforderungen an die Datenkonsistenz und sogar fehlerhafte Lesevorgänge sind zulässig.
In Unternehmensanwendungsszenarien wie Finanzbanking oder Finanzen sind Join-Vorgänge jedoch im Allgemeinen unverzichtbar. Diese Anwendungen weisen im Allgemeinen eine geringe Parallelität auf, schreiben häufig komplexe Daten und sind eher CPU-intensiv als IO-intensiv, und die Hauptgeschäftslogik wird durch verarbeitet Auch Systeme, die eine große Anzahl gespeicherter Prozeduren enthalten und hohe Anforderungen an Konsistenz und Integrität stellen.
Das obige ist der detaillierte Inhalt vonIst die Join-Funktion von MySQL zu schwach?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



