

Nachfolgend erfahren Sie in der Spalte „Redis-Tutorial“, wie Sie eine hohe Parallelität von Redis sicherstellen können. Ich hoffe, dass sie Freunden in Not hilfreich sein wird!
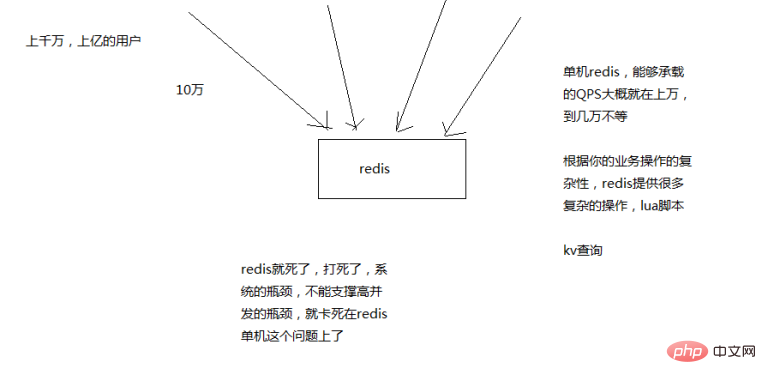 Es ist fast unmöglich, dass ein eigenständiger Redis eine QPS von mehr als 100.000+ hat, normalerweise im Zehntausendbereich.
Es ist fast unmöglich, dass ein eigenständiger Redis eine QPS von mehr als 100.000+ hat, normalerweise im Zehntausendbereich.
Sofern keine besonderen Umstände vorliegen, z. B. wenn die Leistung Ihrer Maschine besonders gut ist, die Konfiguration besonders hoch ist, die physische Maschine besonders gut gewartet ist und Ihr Gesamtbetrieb nicht zu kompliziert ist.
Redis verwendet eine Master-Slave-Architektur, um Lesen und Schreiben zu trennen. Der Master-Knoten ist für das Schreiben und Synchronisieren von Daten mit anderen Slave-Knoten verantwortlich, und die Slave-Knoten sind für das Lesen verantwortlich, wodurch eine hohe Parallelität erreicht wird . 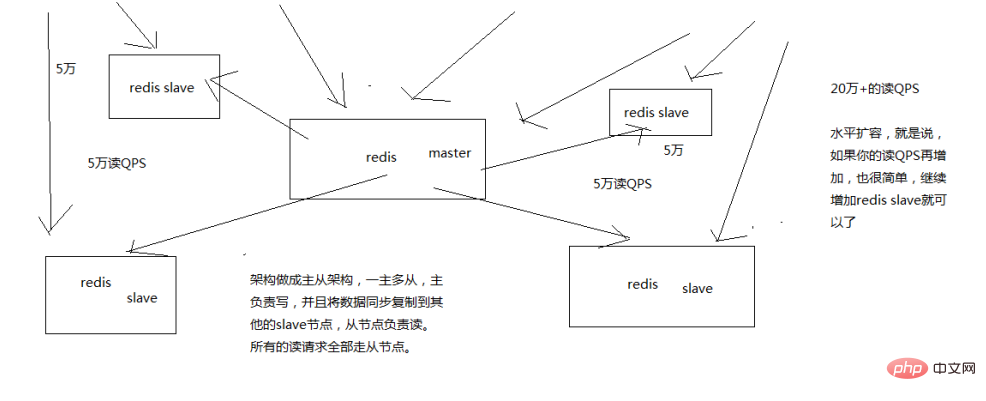
Redis verfügt nicht nur über eine hohe Parallelität, sondern muss auch eine große Datenmenge aufnehmen: einen Master und mehrere Slaves, und jede Instanz bietet Platz für vollständige Daten. Beispielsweise verfügt der Redis-Master nur über 10 GB Speicher. Tatsächlich können nur 10 g Daten gespeichert werden. Wenn Ihr Cache eine große Datenmenge aufnehmen muss, die mehrere zehn Gigabyte oder sogar Hunderte von Gigabyte oder mehrere Tonnen erreicht, dann benötigen Sie einen Redis-Cluster, und mit dem Redis-Cluster können Sie Hunderttausende Daten pro Sekunde bereitstellen. Lesen und schreiben Sie gleichzeitig.
Der Kernmechanismus der Replikation
Redis verwendet eine asynchrone Methode, um Daten auf den Slave-Knoten zu kopieren, aber ab Redis 2.8 bestätigt der Slave-Knoten regelmäßig die Datenmenge, die er jedes Mal kopiert
Ein Master-A-Knoten kann mit mehreren Slave-Knoten konfiguriert werden
Der Slave-Knoten kann sich auch mit anderen Slave-Knoten verbinden
Wenn der Slave-Knoten repliziert, blockiert er nicht die normale Arbeit des Master-Knotens
Wenn der Kopiervorgang abgeschlossen ist, blockiert der Slave-Knoten nicht seinen eigenen Abfragevorgang und verwendet den alten Datensatz zur Bereitstellung von Diensten. Wenn der Kopiervorgang jedoch abgeschlossen ist, muss der alte Datensatz gelöscht und der neue aktualisiert werden Der Datensatz wird geladen und externe Dienste werden zu diesem Zeitpunkt ausgesetzt.
Der Slave-Knoten wird hauptsächlich für die horizontale Erweiterung und Trennung von Lesen und Schreiben verwendet. Der erweiterte Slave-Knoten kann den Lesedurchsatz verbessern der Master-Persistenz für die Sicherheit der Master-Slave-Architektur
Wenn Sie eine Master-Slave-Architektur haben, wird empfohlen, die Persistenz des Masterknotens zu aktivieren!
Es wird nicht empfohlen, den Slave-Knoten als Daten-Hot-Backup des Master-Knotens zu verwenden, da in diesem Fall, wenn Sie die Persistenz des Masters deaktivieren, die Daten möglicherweise leer sind, wenn der Master abstürzt und neu startet. und dann werden die Knotendaten möglicherweise auch gelöscht. Zweitens: Möchten Sie dies tun? Wählen Sie eine RDB aus Backup zum Wiederherstellen des Masters; dies kann sicherstellen, dass der Master startet, wenn Daten vorhanden sind. Der Prozess der Synchronisierung von Daten durch den Master mit dem Slave erfolgt Senden Sie einen PSYNC-Befehl an den Master-Knoten. Wenn dies der Slave-Knoten ist, der sich erneut mit dem Master-Knoten verbindet, kopiert der Master-Knoten nur die fehlenden Daten an den Slave Beim ersten Mal wird eine vollständige Neusynchronisierung ausgelöst
Wenn die vollständige Neusynchronisierung beginnt, startet der Master einen Hintergrundthread, beginnt mit der Generierung einer RDB-Snapshot-Datei und speichert außerdem alle vom Client empfangenen Schreibbefehle im Speicher zwischen.
Nachdem die RDB-Datei generiert wurde, sendet der Master die RDB an den Slave. Der Slave schreibt sie zunächst auf die lokale Festplatte und lädt sie dann von der lokalen Festplatte in den Speicher. Anschließend sendet der Master die im Speicher zwischengespeicherten Schreibbefehle an den Slave und der Slave synchronisiert ebenfalls die Daten.
Wenn der Slave-Knoten einen Netzwerkfehler mit dem Master-Knoten hat und die Verbindung getrennt wird, wird die Verbindung automatisch wiederhergestellt. Wenn der Master feststellt, dass mehrere Slave-Knoten die Verbindung wiederherstellen, startet er lediglich einen RDB-Speichervorgang und versorgt alle Slave-Knoten mit einer Kopie der Daten.
Setzen Sie den Haltepunkt der Master-Slave-Replikation fort
Ab Redis 2.8 wird die Wiederaufnahme der Master-Slave-Replikation am Haltepunkt unterstützt. Wenn die Netzwerkverbindung während des Master-Slave-Replikationsprozesses unterbrochen wird, können Sie mit dem Kopieren an der Stelle fortfahren, an der Sie zuletzt kopiert haben, anstatt am Anfang zu beginnen Der Knoten speichert einen Rückstand im Speicher. Sowohl der Master als auch der Slave speichern einen Replikat-Offset und eine Master-ID.
Wenn die Netzwerkverbindung zwischen Master und Slave getrennt wird, lässt der Slave den Master vom letzten Replikat-Offset weiter kopieren.
Wenn der entsprechende Offset jedoch nicht gefunden wird, wird eine Neusynchronisierung durchgeführt
Diskless-Replikation
Der Master erstellt RDB direkt im Speicher und sendet es dann an den Slave. Die Festplatte wird nicht lokal gespeichert -sync-delay: Warten Sie eine bestimmte Zeit, bevor Sie mit der Replikation beginnen, da Sie darauf warten müssen, dass sich weitere Slaves wieder verbinden Warten Sie, bis der Master den Schlüssel abläuft.
Wenn der Master einen Schlüssel abläuft oder einen Schlüssel über LRU eliminiert, wird ein Del-Befehl simuliert und an den Slave gesendet.
Der vollständige Replikationsprozess
Der Slave-Knoten startet und speichert nur die Informationen des Master-Knotens, einschließlich des Hosts und der IP des Master-Knotens (konfiguriert durch Slaveof in redis.conf). aber der Replikationsprozess startet nicht
Es gibt eine geplante Aufgabe im Slave-Knoten, die jede Sekunde prüft, ob ein neuer Master-Knoten zum Verbinden und Kopieren vorhanden ist, und eine Socket-Netzwerkverbindung mit dem Master herstellt Knoten
Der Slave-Knoten sendet einen Ping-Befehl an den Master-KnotenPasswortauthentifizierung, wenn der Master „requirepass“ festlegt, muss der Slave-Knoten das Masterauth-Passwort zur Authentifizierung senden
Der Masterknoten führt zunächst eine vollständige Replikation durch Zeit und sendet alle Daten an den Slave-Knoten Vollständige Kopie, die ausgeführt wird, wenn der Slave zum ersten Mal eine Verbindung zu msater herstellt, und einige Ihrer detaillierten Mechanismen in diesem Prozess(1) Sowohl Master als auch Slave behalten einen Offset bei
Der Master sammelt kontinuierlich Offsets auf sich selbst , und der Slave sammelt auch kontinuierlich Offsets für sich selbst. Der Slave meldet dem Master jede Sekunde seinen eigenen Offset, und der Master speichert auch den Offset jedes Slaves. Dies bedeutet nicht, dass dies spezifisch ist Wird für die vollständige Replikation verwendet. Der Hauptgrund ist, dass sowohl der Master als auch der Slave den Offset ihrer eigenen Daten kennen müssen, um die Inkonsistenz der Daten untereinander zu erkennen. (2) Rückstand Der Masterknoten hat einen Rückstand, die Standardgröße beträgt 1 MB
Wenn der Master-Knoten Daten auf den Slave-Knoten kopiert, schreibt er auch synchron eine Kopie der Daten in den Rückstand
Der Rückstand wird hauptsächlich für die inkrementelle Replikation bei vollständiger Replikation verwendet ist unterbrochen
(3) Master-Lauf-ID
Infoserver, Sie können die Master-Lauf-ID sehen
Wenn Sie den Master-Knoten anhand von Host + IP finden, ist es unzuverlässig, wenn der Master-Knoten neu startet Wenn sich die Daten ändern, sollte der Slave-Knoten anhand verschiedener Ausführungs-IDs unterschieden werden. Wenn Sie Redis neu starten müssen, ohne die Ausführungs-ID zu ändern, können Sie redis-cli verwenden Debug-Reload-Befehl
(4) psync
Der Slave-Knoten verwendet psync, um den Runid-Offset vom Master-Knoten zu kopieren. Der Master-Knoten gibt Antwortinformationen entsprechend seiner eigenen Situation zurück Runid-Offset, der die vollständige Replikation auslöst, oder es kann sich um eine inkrementelle Kopie handeln
Der Master führt bgsave aus und generiert lokal eine RDB-Snapshot-Datei
Wenn die RDB-Kopierzeit 60 Sekunden überschreitet (Repl-Timeout), berücksichtigt der Slave-Knoten dies Der Kopiervorgang ist fehlgeschlagen. Dieser Parameter kann entsprechend angepasst werden. Bei Computern mit Gigabit-Netzwerkkarten werden im Allgemeinen 100 MB und 6 GB Dateien pro Sekunde übertragen, was wahrscheinlich mehr als 60 Sekunden dauert. Wenn der Masterknoten RDB generiert, wird er zwischengespeichert Alle neuen Schreibbefehle im Speicher. Nachdem der Salve-Knoten die RDB gespeichert hat, kopieren Sie den neuen Schreibbefehl auf den Salve-Knoten
client-output-buffer-limit Slave 256 MB 64 MB 60, wenn der Speicherpuffer weiterhin mehr als 64 MB verbraucht Während des Kopiervorgangs oder einmalig. Wenn die Größe 256 MB überschreitet, wird der Kopiervorgang beendet und der Kopiervorgang schlägt fehl Gleichzeitig werden externe Dienste basierend auf der alten Datenversion bereitgestellt. Wenn der Slave-Knoten AOF aktiviert ist, wird BGREWRITEAOF sofort ausgeführt, um AOF neu zu schreiben. Die Slave-Netzwerkverbindung wird während des vollständigen Kopiervorgangs getrennt. Wenn der Salve dann wieder eine Verbindung zum Master herstellt, löst er eine inkrementelle Replikation aus
Der Master ruft einen Teil der verlorenen Daten direkt aus seinem eigenen Backlog ab und sendet sie an den Slave-Knoten Das Standard-Backlog beträgt 1 MB.
msater erhält Daten aus dem Backlog basierend auf dem vom Slave gesendeten Offset in psync. BHeartBeat
Der Hauptknoten sendet HeartBeat-Informationen Knoten sendet alle 1 Sekunde einen HeartBeat
Jedes Mal, wenn der Master einen Schreibbefehl empfängt, schreibt er nun intern Daten und sendet sie dann asynchron an den Slave-Knoten
Das obige ist der detaillierte Inhalt vonWissen Sie, wie Sie eine hohe Parallelität von Redis sicherstellen können?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?



























