



正则表达式应用的场景也非常多。常见的比如:搜索引擎的搜索、爬虫结果的匹配、文本数据的提取等等都会用到,所以掌握甚至精通正则表达式是一个硬性技能,非常必要。
正则表达式是一个特殊的字符序列,由普通字符和元字符组成。元字符能帮助你方便的检查一个字符串是否与某种模式匹配。
Python中则提供了强大的正则表达式处理模块,即 re 模块, 为Python的内置模块。
下面,我带大家来一个入门demo例子,代码如下:
import rereg_string = "hello9527python@wangcai.@!:xiaoqiang" reg = "hello"result = re.findall(reg,reg_string) print(result)复制代码
这里reg_string就是我们的普通字符,reg就是我们的元字符。
我们使用 re 模块中的findall函数,进行匹配,返回的结果是列表数据类型。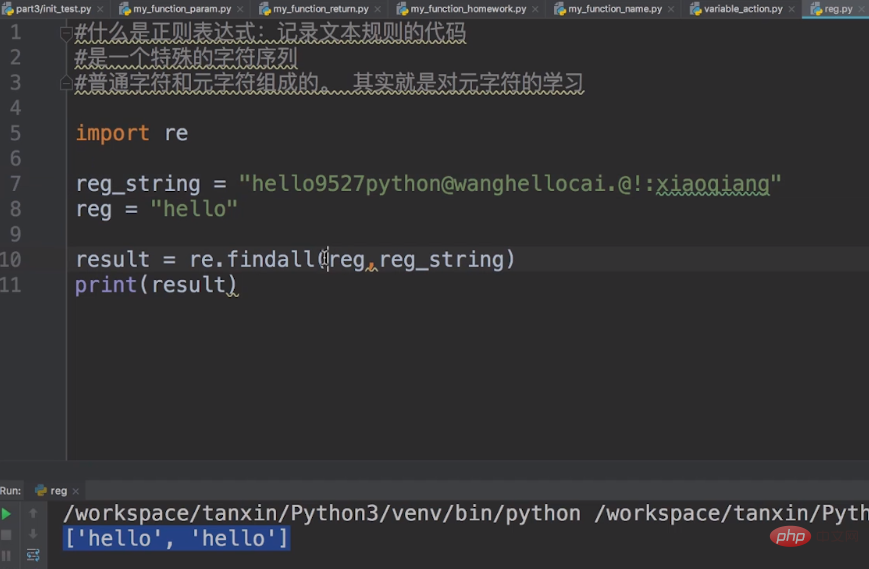
我们使用正则表达式,就是为了在很长的字符串中,找到我们需要的字符串片段。
Python中常见元字符及其含义如下:
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \\\\w | 匹配数字字母下划线汉字 |
| \\\\s | 匹配任意空白符 |
| \\\\d | 匹配所有的数字 |
| \\\\b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的开始结束 |
| 下面,我们具体使用下Python中的常见的元字符。 |
我们还是使用上次的例子,这次我们需要在reg_string匹配出我们的数字,只需要将reg换成\\\\d,代码如下图所示。
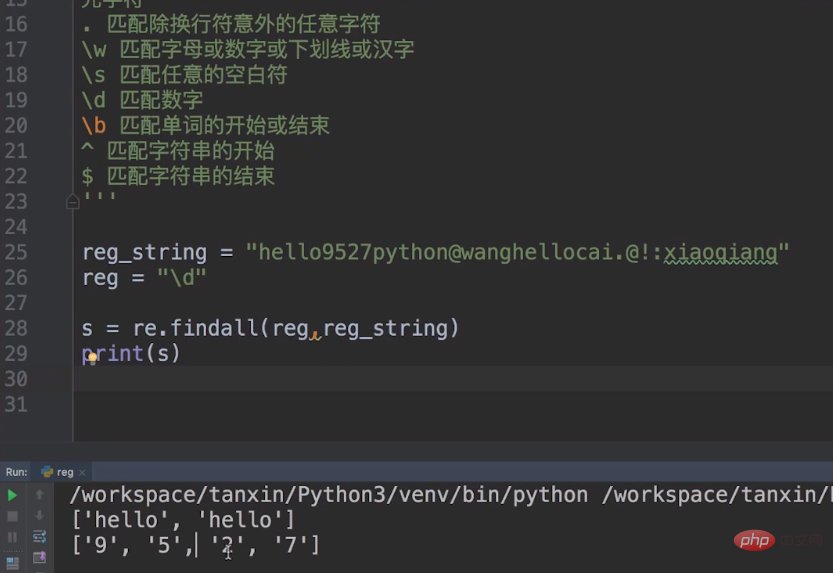 比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
如果,我们把reg换成\\\\w,代码如下图所示。
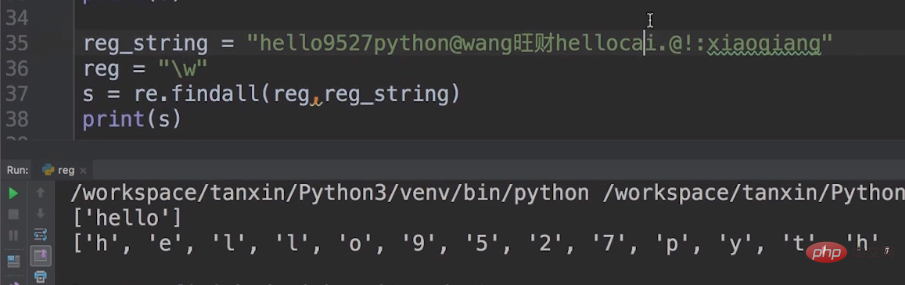
这样就是匹配数字字母下划线,包括我们的汉字。
Python中常见反义代码 及其含义如下:
| 反义代码 | 含义 |
|---|---|
| \\\\W | 匹配任意不是数字字母下划线汉字的字符 |
| \\\\S | 匹配任意不是空白符的字符 |
| \\\\D | 匹配非数字 |
| \\\\B | 匹配不是单词的开始或结束 |
| [^a] | 匹配除了a以外的任意字符 |
| [^abcd] | 匹配除了abcd以外的任意字符 |
其实,记忆很简单,我们是不是知道\\\\d匹配数字,那么\\\\d的大写\\\\D就是匹配非数字,元字符[a]匹配a任意字符,那么[^a]就是匹配除了a以外的任意字符。
下面是具体例子
>>> import re>>> reg_string = "hello9527python@wangcai.@!:xiaoqiang" >>> reg = "\\\\D">>> re.findall(reg,reg_string) ['h', 'e', 'l', 'l', 'o', 'p', 'y', 't', 'h', 'o', 'n', '@', 'w', 'a', 'n', 'g', 'c', 'a', 'i', '.', '@', '!', ':', 'x', 'i', 'a', 'o', 'q', 'i', 'a', 'n', 'g'] >>> reg = "[^a-p]"['9', '5', '2', '7', 'y', 't', '@', 'w', '.', '@', '!', ':', 'x', 'q']复制代码
什么是限定符?就是限定我们匹配的个数的东西。
Python中常见限定符 及其含义如下:
| 限定符 | 含义 |
|---|---|
| * | 重复零次或多次 |
| + | 重复一次或多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n次到m次 {1,3} |
Wir verwenden weiterhin unseren vorherigen reg_string. Dieses Mal beschränken wir das Metazeichen auf \\d{4}, was bedeutet, dass unsere übereinstimmenden Zahlen 4 sein müssen.
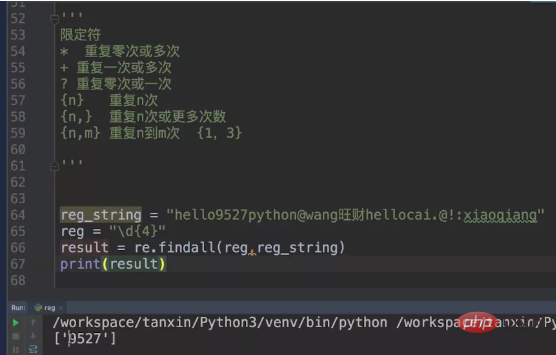
Als nächstes erhöhen wir den Schwierigkeitsgrad und ordnen Buchstaben und Zahlen zu. Das Limit liegt bei 4.
Auf diese Weise können wir [0-9a-z]{4} als unser Metazeichen verwenden, das die zehn Zahlen von 0 bis 9 und die 26 englischen Kleinbuchstaben von a bis z darstellt. [0-9a-z]{4} begrenzt die Anzahl auf 4.
Lassen Sie uns die Ausgabe ausdrucken.
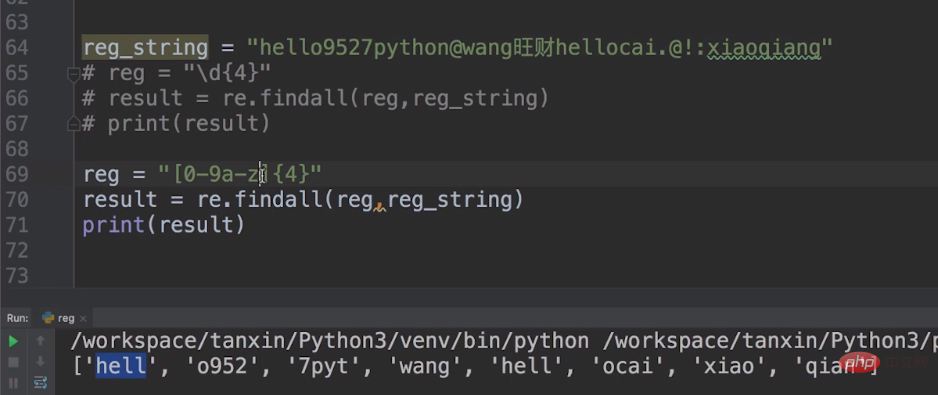
Wenn etwas gefunden wird, das nicht im Bereich von [0-9a-z] liegt, wird es übersprungen, bis die nächsten 4 im Bereich von [0-9a-z] liegen, und ausgedruckt.
Im Internet hat ein Host nur eine IP-Adresse. Die IP-Adresse wird verwendet, um die Adresse jedes Computers im TCP/IP-Kommunikationsprotokoll zu kennzeichnen. Sie wird normalerweise in Dezimalschreibweise ausgedrückt, z. B. 192.168.1.100.
Im Fenstersystem können wir unsere IP über ipconfig überprüfen. In Linux-Systemen können wir unsere IP über ifconfig anzeigen.
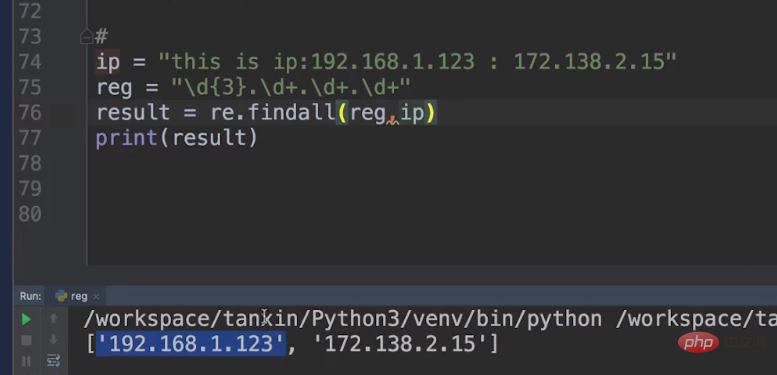
Unser IP-String sieht so aus: ip = "this is ip:192.168.1.123 :172.138.2.15"ip = "this is ip:192.168.1.123 :172.138.2.15"
下面要求使用正则表达式,将ip匹配出来。
其实,我们主要编写元字符。比如:reg = "\d{3}.\d+.\d+.\d+",因为第一个数字必须是三位数开头,我们可以设定\d{3}固定起来。
 我们除了可以使用findall,还可以使用search,我们把元字符
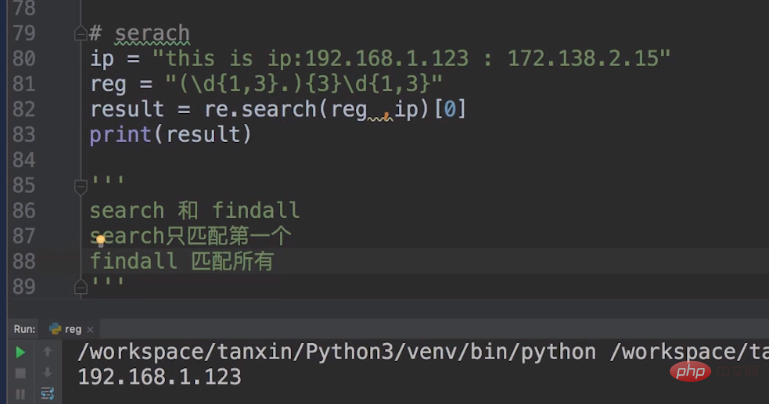
我们除了可以使用findall,还可以使用search,我们把元字符reg = "(\d{1,3}.){3}\d{1,3}"。
这元字符中的\d{1,3}.指定是我们ip前三个数字,后面加{3}就是重复3次。\d{1,3}指的就是我们ip最后一个数字。
但是search和findall是有区别的,search只能匹配第一个,我们需要使用列表取出第一个,而findall匹配所有。
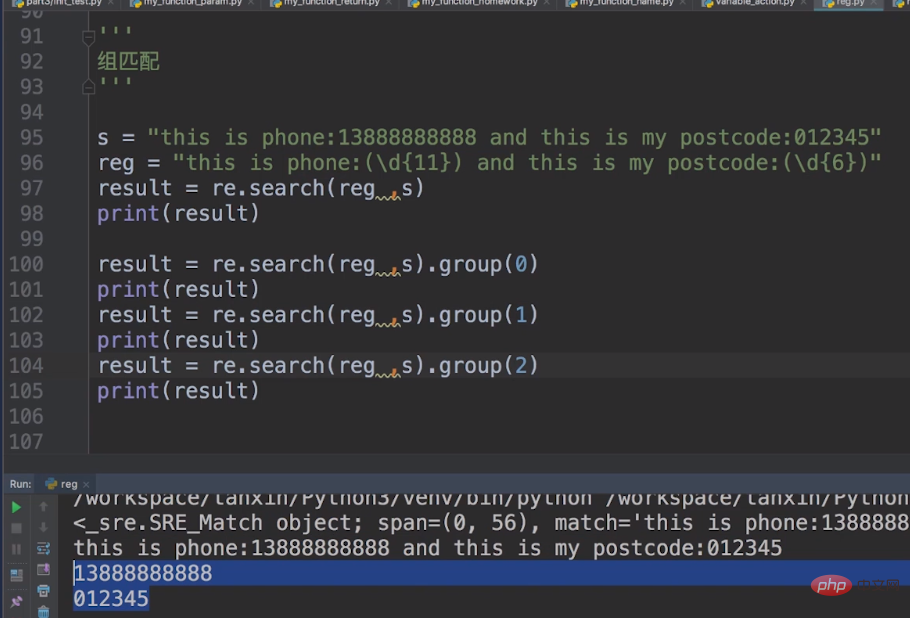
什么是组匹配,比如说这里边我有一个字符串s = this is phone:13888888888 and this is my postcode:012345,我需要你把手机号和验证码匹配出来。
因为,我们要匹配两个,而已每个的元字符都是不一样的。所以,我们需要分组匹配。
正则表达式的括号表示分组匹配,括号中的模式可以用来匹配分组的内容。
于是我们的元字符就变成:reg = this is phone:(\d{11}) and this is my postcode:(\d{6})
我们一般使用search进行分组匹配,上次我是不是说过search需要使用列表取出来,这里的组匹配也是一样,不过这里用的是group()方法。group(1)代表了我们的手机号,group(2)代表了我们的验证码,而group(0)
 Eigentlich schreiben wir hauptsächlich Metazeichen. Zum Beispiel:
Eigentlich schreiben wir hauptsächlich Metazeichen. Zum Beispiel: reg = "\\d{3}.\\d+.\\d+.\\d+",Da die erste Zahl mit einer dreistelligen Zahl beginnen muss, können wir \\d{3}Behoben.
Zusätzlich zu findall können wir auch search verwenden. Wir setzen das Metazeichen reg = "(\\d{1,3}.){3}\\d{1, 3 }".
Der \\d{1,3} in diesem Metazeichen gibt die ersten drei Ziffern unserer IP an, und das Hinzufügen von {3} danach bedeutet, dass es dreimal wiederholt wird. \\d{1,3} bezieht sich auf die letzte Nummer unserer IP.
Aber es gibt einen Unterschied zwischen search und findall. Wir müssen die Liste verwenden, um die erste zu finden, während findall alle findet. 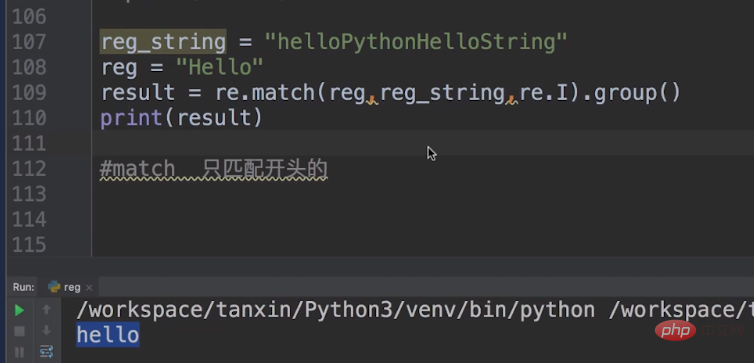
Was ist Gruppenabgleich? Hier habe ich zum Beispiel eine Zeichenfolge s = this is phone:13888888888 und this ist meine Postleitzahl: 012345, ich möchte, dass Sie Ihre Mobiltelefonnummer mit dem Bestätigungscode abgleichen.
Weil wir zwei übereinstimmen müssen und die Metazeichen von jedem unterschiedlich sind. Wir brauchen also eine Gruppenzuordnung.
| Wir verwenden normalerweise die Suche nach Gruppen Matching. Habe ich letztes Mal erwähnt, dass die Suche mithilfe einer Liste abgerufen werden muss? Dasselbe gilt hier für den Gruppen-Matching, aber hier wird die Methode | |
|---|---|
| Die Übereinstimmungsverwendung stimmt nur mit dem Anfang überein und muss auch von group() herausgenommen werden. Das Folgende ist ein Beispiel für eine Übereinstimmung. | Das ist re. Ich meine, die Groß-/Kleinschreibung zu ignorieren. |
| Die Modi „Gierig“ und „Nicht-Gier“ wirken sich auf das Übereinstimmungsverhalten von durch Quantifizierer modifizierten Unterausdrücken aus -greedy-Modus Unter der Voraussetzung, dass der gesamte Ausdruck erfolgreich übereinstimmt, stimmen Sie so wenig wie möglich überein. | Es gibt mehrere sehr wichtige Operatoren für Gierige und Nicht-Gierige. |
| Operator |
比如说这里边我有一个字符串reg_string = pythonnnnnnnnnpythonHelloPytho,我们先使用贪婪的模式下的元字符:reg = "python*"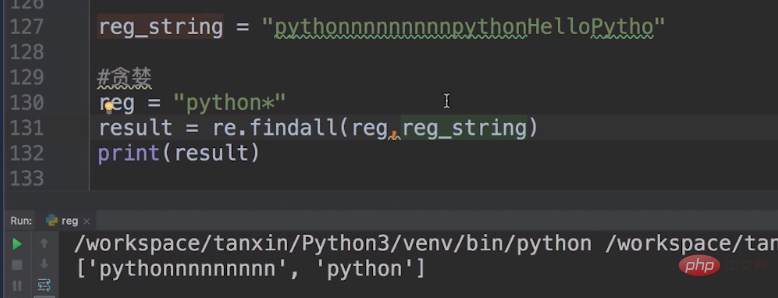
贪婪模式下的reg = "python*",意味着n重复零次或更多次。所以我们看到了第一关结果的pythonnnnnnnnn尽可能多的匹配。
下面使用非贪婪的模式下的元字符:reg = "python*?",reg = "python+?",reg = "python??"。
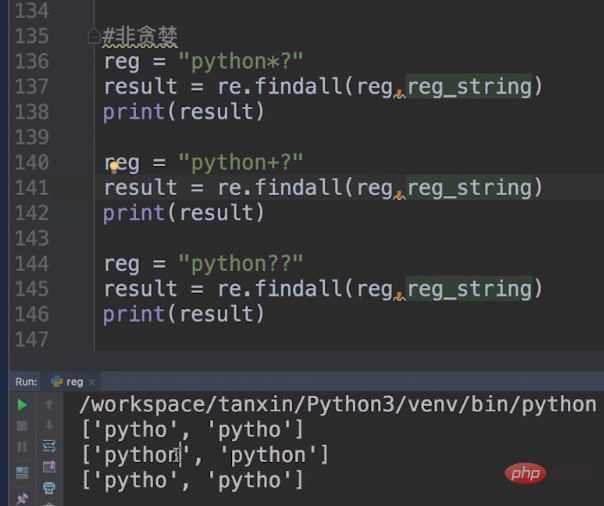 非贪婪模式下的
非贪婪模式下的reg = "python*",意味着n零次或一次,所以我们没有看到pythonnnnnnnnn的结果。
首先,我们要知道我们的手机号码是什么开头的?
移动手机号码开头有16个号段:134、135、136、137、138、139、147、150、151、152、157、158、159、182、187、188。
联通手机号码开头有7种号段:130、131、132、155、156、185、186。
电信手机号码开头有4个号段:133、153、180、189。
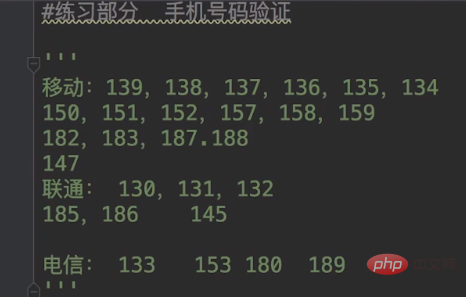
这样我们就可以在开头做事情了,先判断开头是不是上面的号段, regex = "^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\\\\d{8}$",就是我们的元字符,代码如下:
import redef checkCellphone(cellphone): regex = "^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\\\\d{8}$" result = re.findall(regex,cellphone) if result: print("匹配成功") return True
else: print("匹配失败") return Falsecellphone = '13717378202'checkCellphone(cellphone)
匹配成功True复制代码下面,我们进行一个作业,就是来匹配我们的邮箱号码。
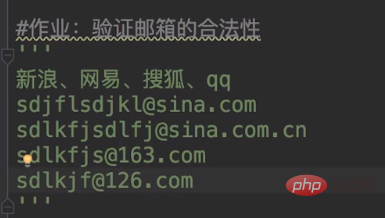
作业的答案如下:
import redef checkEmail(email): regex_1 = '^(\\\\w+)@sina.com$'
regex_2 = '^(\\\\w+)@sina.com.cn$'
regex_3 = '^(\\\\w+)@163.com$'
regex_4 = '^(\\\\w+)@126.com$'
regex_5 = '^[1-9][0,9]{4,}+@qq.com$'
regex = [regex_1 ,regex_2 ,regex_3, regex_4, regex_5]
for i in regex:
result = re.findall(i,email)
if result:
print("匹配成功")
return True else:
print("匹配失败")
return False
email = 'sdjflsdjkl@sina.com'checkEmail(email)复制代码打开开源中国提供的正则表达式测试工具 tool.oschina.net/regex/,输入待匹…
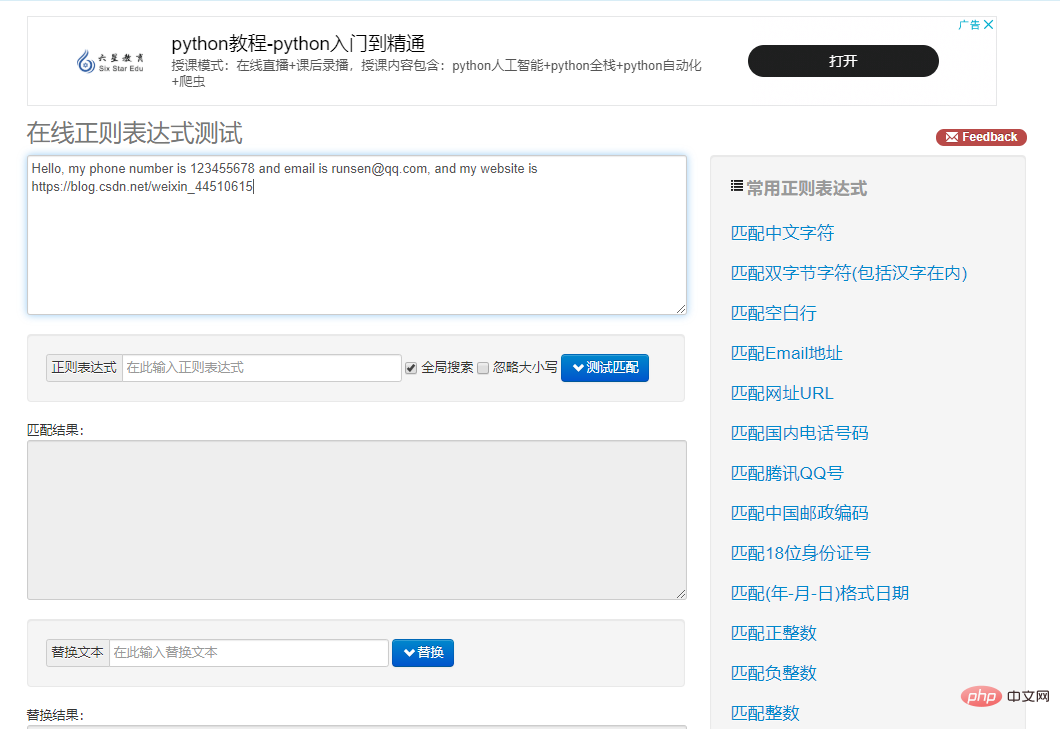
例如,输入下面这段待匹配的文本:
Hello, my phone number is 123455678 and email is runsen@qq.com, and my website is https://blog.csdn.net/weixin_44510615.复制代码
这段字符串中包含了一个电话号码和一个电子邮件,接下来就尝试用正则表达式提取出来,如图所示。
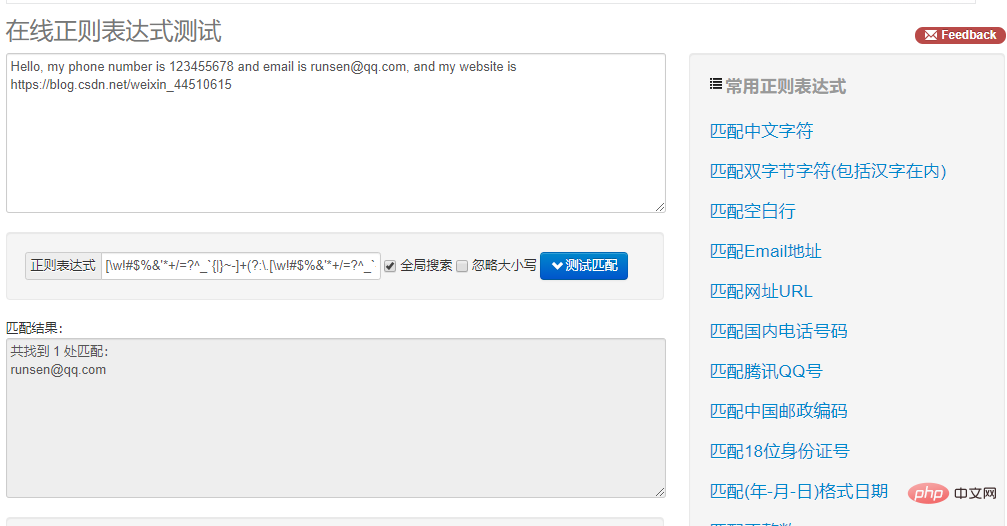
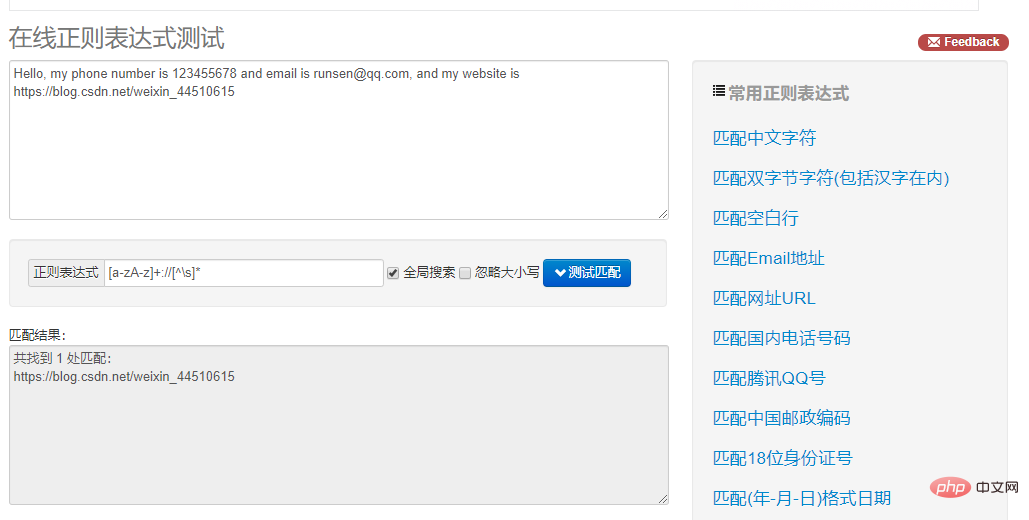
在网页右侧选择 “匹配 Email 地址”,就可以看到下方出现了文本中的 E-mail。如果选择 “匹配网址 URL”,就可以看到下方出现了文本中的 URL。是不是非常神奇?
相关免费学习推荐:python教程(视频)
Das obige ist der detaillierte Inhalt vonDetaillierte Erklärung regulärer Ausdrücke in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



