


REGREATED FREE LERN -Empfehlungen:mysql -Datenbank(Video)
Zuvor haben wir über die zugrunde liegende Datenstruktur und den Algorithmus der MySQL-Datenbank sowie einige Inhalte des MySQL-Leistungsoptimierungsteils gesprochen. Lassen Sie uns noch einmal über die Sperr- und Transaktionsisolationsstufen von MySQL sprechen, aufgeteilt in zwei Artikel. Dieser Artikel konzentriert sich auf die Zeilensperren und Transaktionsisolationsstufen von MySQL.
Lock ist ein Mechanismus für Computer, um den gleichzeitigen Zugriff auf eine Ressource durch mehrere Prozesse oder Threads zu koordinieren.
In der Datenbank sind Daten neben dem Wettbewerb um herkömmliche Computerressourcen (wie CPU, RAM, E/A usw.) auch eine Ressource, die von Benutzern gemeinsam genutzt werden muss. Die Gewährleistung der Konsistenz und Effektivität des gleichzeitigen Datenzugriffs ist ein Problem, das alle Datenbanken lösen müssen. Der „Sperrkonflikt“ ist ebenfalls ein wichtiger Faktor, der sich auf die Leistung des gleichzeitigen Datenbankzugriffs auswirkt. DieSperrklassifizierung
ist hinsichtlich der Leistung inMySQL-Sperren
, diese Art von Sperre wird hauptsächlich fürräumliche Indizes verwendet, die räumliche Daten speichern.
Tabellensperre
# 建表SQLCREATE TABLE mylock ( id INT(11) NOT NULL AUTO_INCREMENT, NAME VARCHAR(20) DEFAULT NULL, PRIMARY KEY(id) ) ENGINE = MyISAM DEFAULT CHARSET = utf8; # 插入数据INSERT INTO`test`.`mylock`(`id`,`NAME`) VALUES ('1','a'); INSERT INTO`test`.`mylock`(`id`,`NAME`) VALUES ('2','b'); INSERT INTO`test`.`mylock`(`id`,`NAME`) VALUES ('3','c'); INSERT INTO`test`.`mylock`(`id`,`NAME`) VALUES ('4','d');复制代码
lock table 表名称 read(write), 表名称2 read(write);复制代码
show open tables;复制代码
unlock tables;复制代码
LOCK TABLE mylock read;复制代码
 Beim Einfügen oder Aktualisieren der gesperrten Tabelle in der aktuellen Sitzung wird ein Fehler gemeldet, während andere Sitzungen auf das Einfügen oder Aktualisieren warten.
Beim Einfügen oder Aktualisieren der gesperrten Tabelle in der aktuellen Sitzung wird ein Fehler gemeldet, während andere Sitzungen auf das Einfügen oder Aktualisieren warten.
LOCK TABLE mylock WRITE;复制代码

 Fallschluss
Fallschluss
Vor dem Ausführen der Abfrageanweisung (SELECT) werden automatisch Lesesperren zu allen beteiligten Tabellen hinzugefügt, bevor Vorgänge zum Hinzufügen, Löschen, Ändern und Abfragen ausgeführt werden Tabellen beteiligt.
Der Lesevorgang (Hinzufügen einer Lesesperre) zur MyISAM-Tabelle blockiert nicht die Leseanforderungen derselben Tabelle durch andere Prozesse, sondern blockiert die Schreibanforderungen derselben Tabelle. Erst wenn die Lesesperre aufgehoben wird, werden die Schreibvorgänge anderer Prozesse ausgeführt.Schreibvorgänge (Hinzufügen von Schreibsperren) zur MyISAM-Tabelle blockieren die Lese- und Schreibvorgänge anderer Prozesse in derselben Tabelle. Erst nachdem die Schreibsperre aufgehoben wurde, werden die Lese- und Schreibvorgänge anderer Prozesse ausgeführt.
Sperrt eine Datenzeile für jeden Vorgang.
InnoDB和 MyISAM 的最大不同点:
事务是由一组 SQL 语句组成的逻辑处理单元,事务具有以下四个属性,通常简称为事务的ACID属性。
当两个或多个事务选择同一行,然后基于最初选定的值更新该行值,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题,最后的更新覆盖来其他事务所做的更新。
一个事务正在对一条记录做修改,在这个事务完成并提交前,这个条记录的数据就处于不一致的状态;这时另外一个事务也来读取同一条记录,如果不加控制,第二个事务读取来这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象的叫做“脏读”。
总结:事务A读取到来事务B已经修改但尚未提交的数据,还在这个数据基础上做来操作。此时,如果事务B回滚,事务A读取的数据无效,不符合一致性要求。
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生来改变、或某些记录已经被删除了,这种现象就叫做“不可重复读”。
总结:事务A读取到了事务B已经提交的修改数据,不符合隔离性。
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
总结:事务A读取到了事务B提交的新增数据,不符合隔离性。
“脏读”、“不可重复读”、“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。
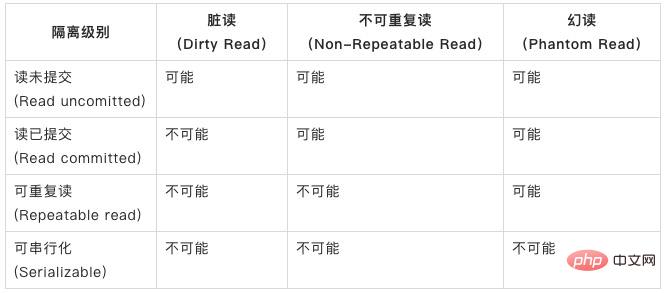
数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。
同时,不同应用对读一致性和事务隔离程度的要求也是不同的,比如许多应用对“不可重复读”和“幻读” 并不敏感,可能更关系数据并发访问的能力。
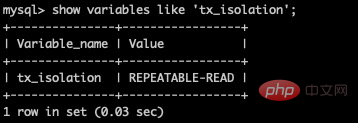
查看当前数据库的事务隔离级别
show variables like 'tx_isolation';复制代码
设置事务隔离级别
set tx_isolation='REPEATABLE-READ';复制代码
数据库版本是5.7,隔离级别是Repeatable-Read(可重复读),不同的数据库版本和隔离级别对语句的执行结果影响很大。所以需要说明版本和隔离级别
BEGIN或START TRANSACTION;显式地开启一个事务;COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改称为永久性的;ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;SAVEPOINT identifier;SAVEPOINT允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT;RELEASE SAVEPOINT identifier;删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;ROLLBACK TO identifier;把事务回滚到标记点;SET TRANSACTION;用来设置事务的隔离级别。InnoDB存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLE。MYSQL 事务处理主要有两种方法:
BEGIN,ROLLBACK,COMMIT来实现
SET AUTOCOMMIT=0禁止自动提交SET AUTOCOMMIT=1``开启自动提交示例表,如下:
CREATE TABLE `user` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `name` VARCHAR (255) DEFAULT NULL, `balance` INT (11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = INNODB DEFAULT CHARSET = utf8;INSERT INTO `test`.`user` (`name`,`balance`) VALUES ('zhangsan','450');INSERT INTO `test`.`user` (`name`,`balance`) VALUES ('lisi', '16000');INSERT INTO `test`.`user` (`name`,`balance`) VALUES ('wangwu','2400');复制代码
一个 session 开启事务更新不提交,另一个 seesion 更新同一条记录会阻塞,更新不同记录u会阻塞。

(1)打开一个客户端A,并设置当前事务模式为read uncommitted(读未提交),查询表 user 的初始化值
set tx_isolation='read-uncommitted';复制代码
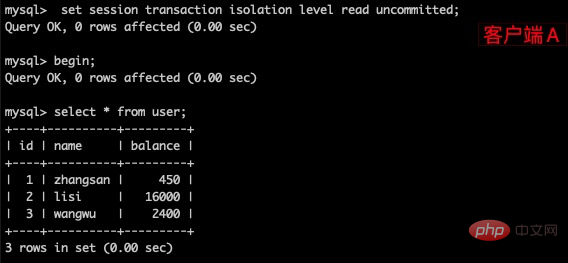
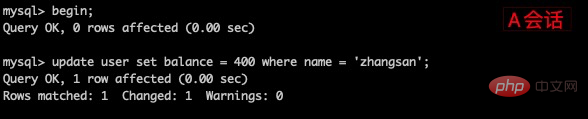
(2)在客户端A的事务提交之前,打开另一个客户端B,更新表 user
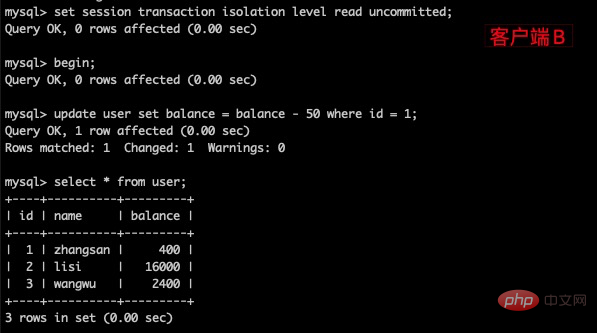
(3)这时,虽然客户端B的事务还没提交,但是在客户端A就可以查询到B已经更新的数据
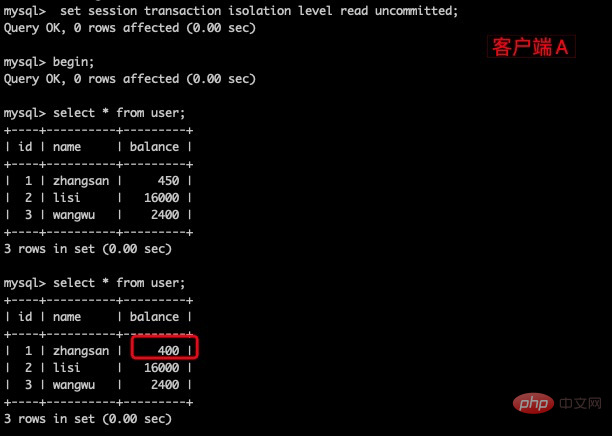
(4)一旦客户端B的事务因为某种原因回滚,所有的操作都将会被撤销,那么客户端A查询到的数据其实就是脏数据。
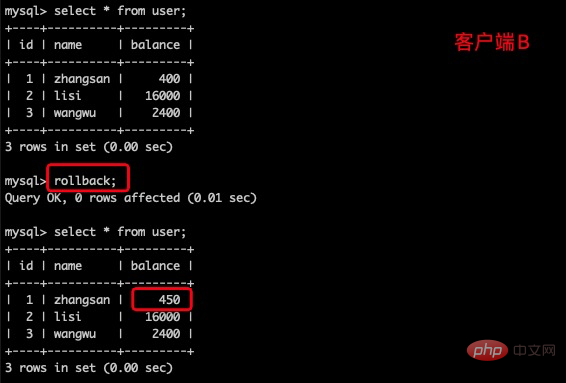
(5)在客户端A执行更新语句update user set balance = balance - 50 where id = 1;zhangsan 的 balance没有变成350,居然是400,是不是很奇怪,数据不一致啊。如果你这么想就太天真了,在应用程序中,我们会用400-50=350,并不知道其他会话回滚了,要想解决这个问题可以采用读已提交的隔离级别。
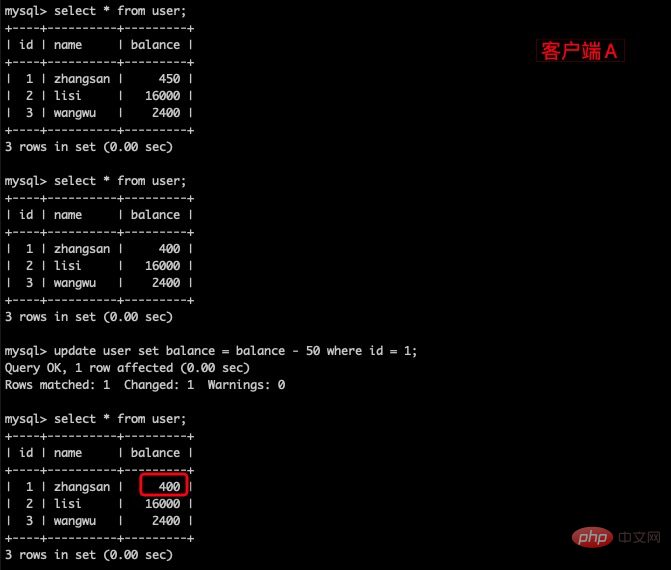
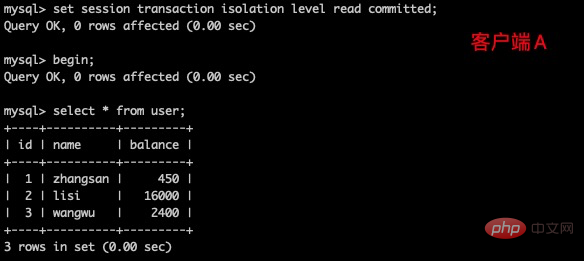
(1)打开一个客户端A,并设置当前事务模式为read committed(读已提交),查询表 user 的所有记录
set tx_isolation='read-committed';复制代码
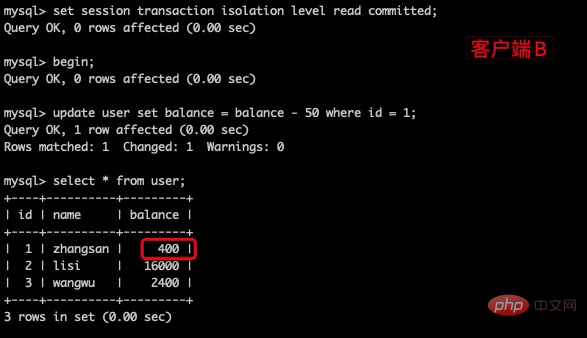
(2)在客户端A的事务提交之前,打开另一个客户端B,更新表 user
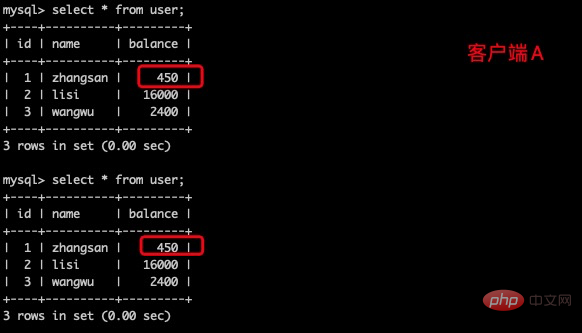
(3)这时,客户端B的事务还没提交,客户端A不能查询到B已经更新的数据,解决了脏读问题。
(4)客户端B的事务提交
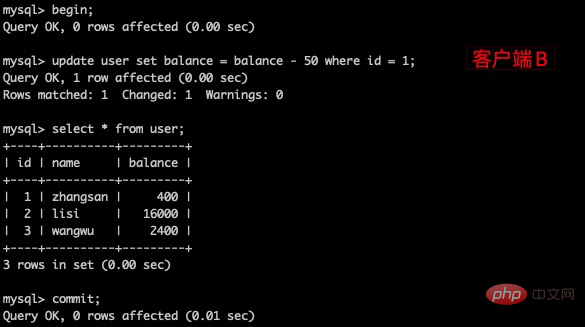
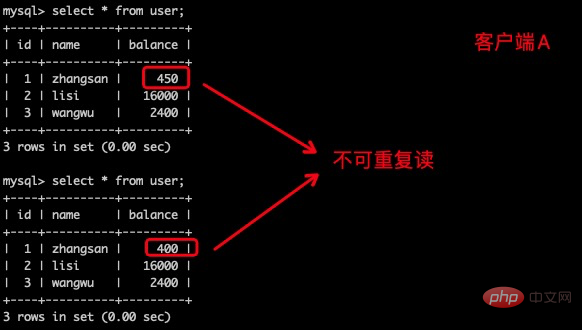
(5)客户端A执行与上一步相同的查询,结果与上一步不一致,即产生了不可重复读的问题。
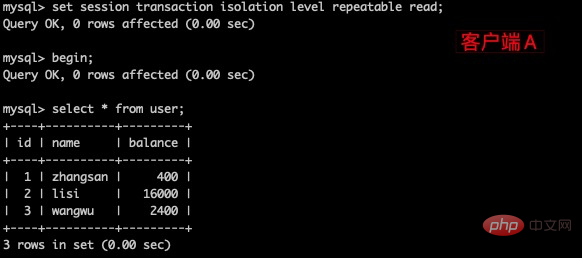
(1)打开一个客户端A,并设置当前的事务模式为repeatable read,查询表 user 的所有记录。
set tx_isolation='repeatable-read';复制代码
(2)在客户端A的事务提交之前,打开另一个客户端B,更新表 user 并提交。
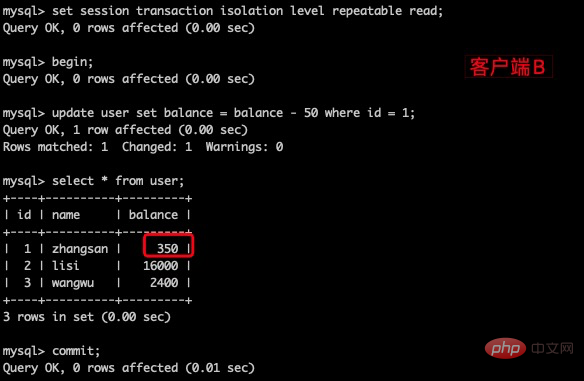
(3)在客户端A查询表 user 的所有记录,与步骤(1)查询结果一直,没有出现不可重复读的问题。
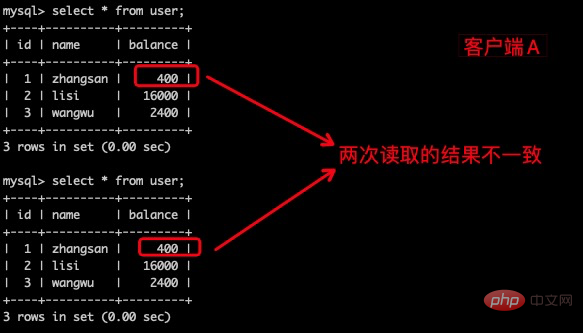
(4)在客户端A,接着执行update user set balance = balance - 50 where id = 1, balance 没有变成 400 - 50 = 350, zhangsan 的 balance 的值用的是步骤(2) 中的 350 来计算的,所以是300,数据的一致性倒是没有被破坏。可重复读的隔离级别下使用了MVCC(multi-version concurrency control)机制,select 操作不会更新版本号,是快照读(历史版本);insert、update、delete 会更新版本号,是当前读(当前版本)。
我们下篇来讲 MVCC。
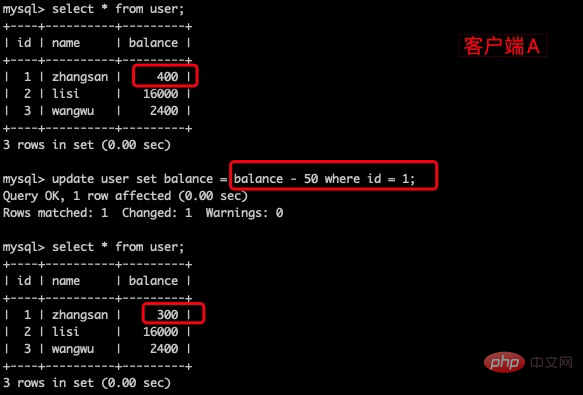
(5)重新打开客户端B,插入一条新数据后提交。
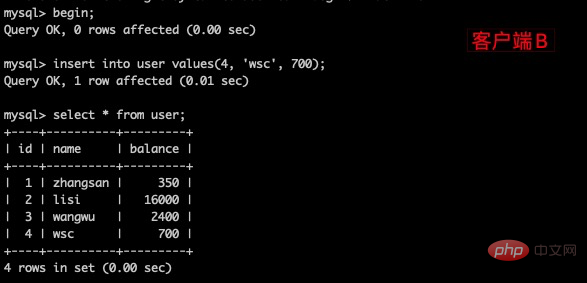
(6)在客户端A查询表user 的所有记录,没有查出新增数据,所以没有出现幻读。

(7)验证幻读 在客户端A执行update user set balance = 8888 where id = 4;,能更新成功,再次查询到客户端B新增的数据。
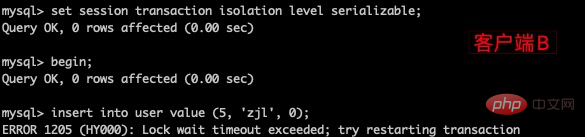
(1)打开一个客户端A,并设置当前事务模式为serializable,查询表 user 的初始值
set tx_isolation='serializable';复制代码
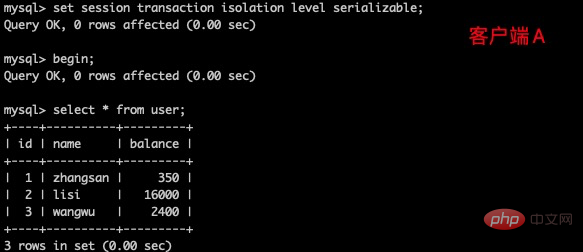
(2)打开一个客户端B,并设置当前事务模式为serializable,插入一条记录报错,表被锁了插入失败,MySQL 中事务隔离级别为serializable时会锁表,因此不会出现幻读的情况,这种隔离级别并发性极低,开发中很少会用到。
InnoDB 存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面所带来的性能损耗可能比表级锁定会更高一下,但是在整体并发处理能力方面要远远优于 MyISAM 的表级锁定的。当系统并发量最高的时候,InnoDB 的整体性能和 MyISAM 相比就会有比较明显的优势。
但是,InnoDB 的行级锁定同样也有其脆弱的一面,当我们使用不当的时候,可能会让 InnoDB 的整体性能表现不仅不能比 MyISAM 高,甚至可能会更差。
通过检查innodb_row_lock状态变量来分析系统上的行锁的竞争情况:
show status like 'innodb_row_lock%';复制代码
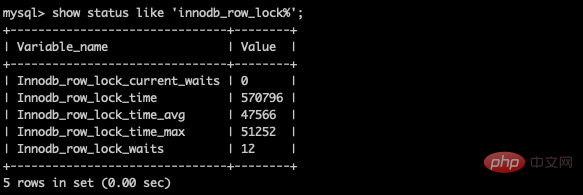
对各个状态量的说明如下:
对于这5个状态变量,比较重要的主要是:
尤其是当等待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统 中为什么会有如此多的等待,然后根据分析结果着手制定优化计划。
set tx_isolation='repeatable-read';复制代码
Session_1执行:select * from user where id=1 for update; Session_2执行:select * from user where id=2 for update; Session_1执行:select * from user where id=2 for update; Session_2执行:select * from user where id=1 for update;复制代码
查看近期死锁日志信息:
show engine innodb status\G;复制代码
大多数情况mysql可以自动检测死锁并回滚产生死锁的那个事务,但是有些情况 mysql没法自动检测死锁
repeatable-read,有什么办法可以解决幻读妈?间隙锁(Gap Lock)在某些情况下可以解决幻读问题,它是 Innodb 在可重复读提交下为解决幻读问题时引入的锁机制。要避免幻读可以用间隙锁在Session_1 下面执行update user set name = 'hjh' where id > 10 and id ,则其他 Session 没法在这个范围锁包含的间隙里插入或修改任何数据。
如:user 表有3条数据,id > 2 and id 会把第三条记录锁住,其他会话对则无法对第三条记录做操作。
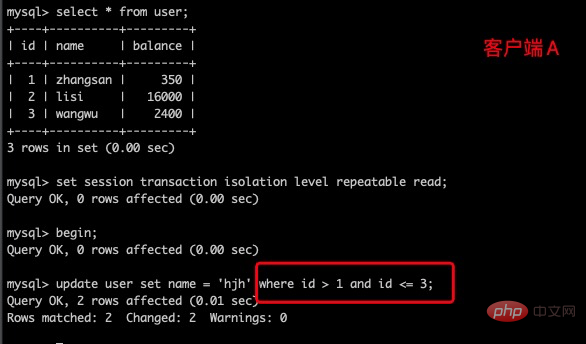
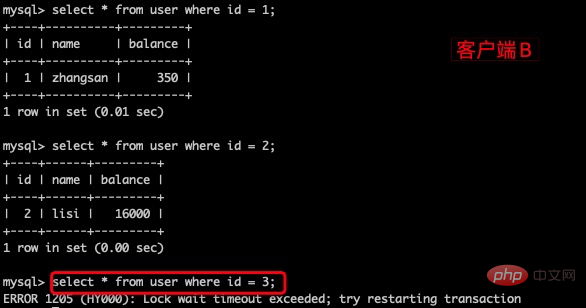
客户端A执行:update user set balance = 800 where name = 'zhangsan';

客户端B对该表任一行执行修改、删除操作都会阻塞

InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁。
local in share mode(共享锁)和for update(排它锁),例如:select * from test_innodb_lock where a = 2 for update;auch verwenden, um eine bestimmte Zeile zu sperren, sodass andere Sitzungen diese Datenzeile nur lesen können und Änderungen blockiert werden, bis die Sitzung, die die Zeile gesperrt hat, übermittelt wird.Das obige ist der detaillierte Inhalt vonKennen Sie die Sperr- und Transaktionsisolationsstufen von MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde MySQL-Datenbank erstellen
MySQL-Datenbank erstellen MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL mysqlPasswort vergessen
mysqlPasswort vergessen


























