



【Verwandte Lernempfehlungen: Video-Tutorial zur Website-Produktion】
Was ist ein Crawler? Vereinfacht und einseitig ausgedrückt ist ein Crawler ein Tool, das automatisch mit einem Server interagiert Daten beschaffen. Das Grundlegendste an einem Crawler ist, die Quellcodedaten einer Webseite abzurufen. Wenn Sie tiefer gehen, haben Sie eine POST-Interaktion mit der Webseite und erhalten die Daten vom Server zurückgegeben, nachdem Sie die POST-Anfrage erhalten haben. Kurz gesagt, der Crawler wird zum automatischen Abrufen von Quelldaten usw. verwendet. In diesem Artikel geht es hauptsächlich um die Datenbeschaffung durch den Crawler. Crawler, bitte achten Sie auf die Robot.txt-Datei der Website. Lassen Sie nicht zu, dass Crawler gegen das Gesetz verstoßen oder der Website Schaden zufügen.
Unangemessene Beispiele für Anti-Crawling- und Anti-Anti-Crawling-Konzepte
Aus vielen Gründen (z. B. Serverressourcen, Datenschutz usw.) schränken viele Websites den Crawler-Effekt ein.
Denken Sie darüber nach: Wenn ein Mensch als Crawler fungiert, wie erhalten wir dann den Quellcode einer Webseite? Die am häufigsten verwendete Methode ist natürlich das Klicken mit der rechten Maustaste auf den Quellcode.
Die Website blockiert den Rechtsklick, was soll ich tun?

Nehmen Sie F12 heraus, das nützlichste Tool in unserem Crawler (willkommene Diskussion)
Drücken Sie gleichzeitig F12, um es zu öffnen (lustig)
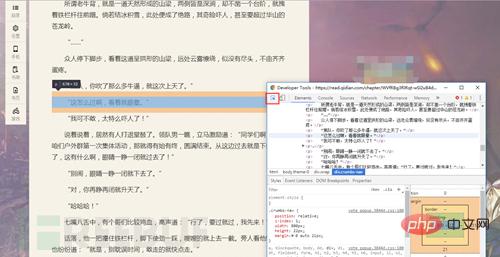
Quellcode Es ist raus!!
Wenn Menschen als Crawler behandelt werden, ist das Blockieren des Rechtsklicks die Anti-Crawling-Strategie und F12 die Anti-Crawling-Methode.
Lassen Sie uns über die formale Anti-Crawling-Strategie sprechen
Tatsächlich muss es Situationen gegeben haben, in denen während des Schreibvorgangs eines Crawlers keine Daten zurückgegeben wurden. In diesem Fall hat der Server möglicherweise den UA-Header (Benutzer) eingeschränkt -agent). Dies ist eine sehr einfache Anti-Crawling-Methode. Fügen Sie einfach den UA-Header hinzu, wenn Sie die Anfrage senden ... Ist das nicht sehr einfach?
Tatsächlich ist es eine einfache und grobe Methode, um alle erforderlichen Elemente hinzuzufügen Header sofort anfordern...
Haben Sie jemals herausgefunden, dass der Bestätigungscode einer Website auch eine Anti-Crawling-Strategie ist? Damit Website-Benutzer echte Menschen sein können, hat der Bestätigungscode wirklich einen großen Beitrag geleistet. Zusammen mit dem Bestätigungscode erschien die Bestätigungscode-Erkennung.
Apropos, ich frage mich, ob die Verifizierungscode-Erkennung oder die Bilderkennung an erster Stelle standen.
Einfache Verifizierungscodes sind jetzt sehr einfach zu erkennen, einschließlich leicht fortgeschrittener Entrauschungskonzepte , Segmentierung und Reorganisation. Aber jetzt ist die Mensch-Maschine-Erkennung auf Websites immer erschreckender geworden, wie zum Beispiel dieses:
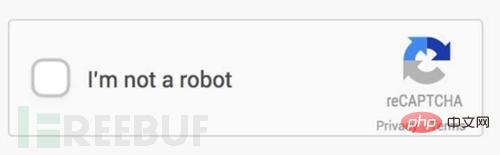
Beschreiben Sie kurz das Konzept der Entrauschung von Binärwerten.
Binärwert, das heißt, das Bild selbst in nur zwei Töne umwandeln Das Beispiel ist Sehr einfach. Dies kann durch
Image.convert("1")
Überlegen Sie, wie Sie diesen Bestätigungscode identifizieren können. Anhand der Eigenschaften des Codes selbst kann die Hintergrundfarbe berechnet werden des Verifizierungscodes und der RGB-Werte außer der Schriftart usw., wandeln Sie diese Werte in eine Farbe um und lassen Sie die Schriftart weg. Der Beispielcode lautet wie folgt, ändern Sie einfach die Farbe
rrree Arr wird von Numpy erhalten. Es handelt sich um eine aus den RGB-Werten des Bildes abgeleitete Matrix. Leser können versuchen, den Code zu verbessern und selbst zu experimentieren. 

Bei der Entwicklung von Verifizierungscodes gibt es relativ klare Zahlen und Buchstaben, einfache Addition, Subtraktion, Multiplikation und Division. Für einige schwierige Zahlen, Buchstaben und chinesische Schriftzeichen können Sie auch Ihre eigenen Räder erstellen (wie oben), aber für mehr Dinge reicht es aus, eine künstliche Intelligenz zu schreiben ... (Es gibt eine Aufgabe, die darin besteht, Bestätigungscodes zu erkennen ...)
Und ein kleiner Tipp: Einige Websites haben Bestätigungscodes auf der PC-Seite, aber nicht auf der Mobiltelefonseite...
Nächstes Thema!
Eine weitere gängige Anti-Crawling-Strategie ist die IP-Blockierung. Normalerweise werden zu viele Besuche in einem kurzen Zeitraum blockiert Ganz einfach. Begrenzen Sie einfach die Häufigkeit der Besuche oder fügen Sie einen IP-Proxy-Pool hinzu. Natürlich kann die Formel auch verwendet werden... Obwohl es nicht viele kostenlose gibt, die genutzt werden können, ist es doch möglich.
Eine weitere Strategie, die auch als Anti-Crawler-Strategie gezählt werden kann, sind asynchrone Daten. Mit der schrittweisen Weiterentwicklung der Crawler (es handelt sich offensichtlich um ein Update der Website!) ist das asynchrone Laden ein Problem, das definitiv auftreten wird Lösung ist immer noch F12. Nehmen Sie als Beispiel die anonyme NetEase Cloud Music-Website, nachdem Sie mit der rechten Maustaste geklickt haben, um den Quellcode zu öffnen.
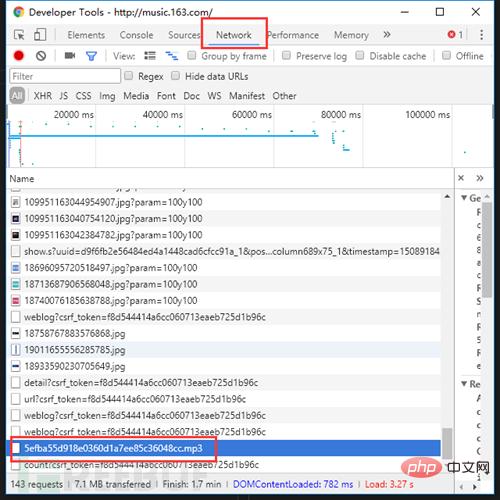
Wo sind die Daten?! . Aber öffnen Sie F12, wechseln Sie zur Registerkarte „Netzwerk“, aktualisieren Sie die Seite und suchen Sie sorgfältig, es gibt kein Geheimnis.
 Übrigens, wenn Sie Musik hören, können Sie sie herunterladen, indem Sie darauf klicken ...
Übrigens, wenn Sie Musik hören, können Sie sie herunterladen, indem Sie darauf klicken ...
 Es dient nur der Popularisierung der Struktur der Website. Bitte widersetzen Sie sich bewusst der Piraterie. Schützen Sie das Urheberrecht und schützen Sie die Interessen des ursprünglichen Urhebers.
Es dient nur der Popularisierung der Struktur der Website. Bitte widersetzen Sie sich bewusst der Piraterie. Schützen Sie das Urheberrecht und schützen Sie die Interessen des ursprünglichen Urhebers.
Was sollten Sie tun, wenn diese Website Sie einschränkt? Wir haben einen letzten Plan, eine unbesiegbare Kombination: Selenium + PhantomJs
Diese Kombination ist sehr leistungsstark und kann das Browserverhalten perfekt simulieren nicht empfehlenswert. Es ist nur für die Populärwissenschaft sehr umständlich.
Das obige ist der detaillierte Inhalt vonEine kurze Diskussion über Crawler und die Umgehung von Website-Anti-Crawling-Mechanismen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Nodejs implementiert Crawler
Nodejs implementiert Crawler
 So öffnen Sie eine Exe-Datei
So öffnen Sie eine Exe-Datei
 So prüfen Sie CNKI auf Plagiate. Detaillierte Schritte zur Plagiatsprüfung auf CNKI
So prüfen Sie CNKI auf Plagiate. Detaillierte Schritte zur Plagiatsprüfung auf CNKI
 Ripple-Markt heute
Ripple-Markt heute
 Die Rolle von Serverlet in Java
Die Rolle von Serverlet in Java
 Eou Web3 Wallet-Tutorial
Eou Web3 Wallet-Tutorial
 Der Unterschied zwischen Mac Air und Pro
Der Unterschied zwischen Mac Air und Pro
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



