


Einführung: Redis ist eine Open-Source-Protokolltyp-Schlüsselwertdatenbank, die in ANSI-C-Sprache geschrieben ist, sich an das BSD-Protokoll hält, das Netzwerk unterstützt, speicherbasiert und persistent sein kann und stellt eine nicht relationale Datenbank mit APIs in mehreren Sprachen bereit.
Besondere Empfehlung: 2020 Redis-Interviewfragen (aktuell)
Traditionelle Datenbanken folgen den ACID-Regeln. Nosql (Abkürzung für Not Only SQL, ein Sammelbegriff für Datenbankverwaltungssysteme, die sich von herkömmlichen relationalen Datenbanken unterscheiden) ist allgemein verbreitet und folgt im Allgemeinen dem CAP-Theorem.
Github-Quellcode: https://github.com/antirez/redis
Offizielle Redis-Website: https://redis.io/
Empfohlen: "Redis-Tutorial》
Welche Datentypen unterstützt Redis?
String:
Format: Schlüsselwert festlegen
Der String-Typ ist binärsicher. Das bedeutet, dass der Redis-String beliebige Daten enthalten kann. Zum Beispiel JPG-Bilder oder serialisierte Objekte.
Der String-Typ ist der grundlegendste Datentyp von Redis und ein Schlüssel kann bis zu 512 MB speichern.
Hash (Hash)
Format: hmset-Name Schlüssel1 Wert1 Schlüssel2 Wert2
Redis-Hash ist ein Satz von Schlüssel-Wert-Paaren (Schlüssel=>Wert).
Redis-Hash ist eine Zuordnungstabelle von Feldern und Werten vom Typ String. Hash eignet sich besonders zum Speichern von Objekten.
Liste (Liste)
Redis-Listen sind einfache Listen von Zeichenfolgen, sortiert in der Einfügereihenfolge. Sie können ein Element zum Kopf (links) oder Ende (rechts) der Liste hinzufügen
Format: lpush-Namenswert
Fügen Sie ein Zeichenfolgeelement zum Kopf der Liste hinzu, das dem Schlüssel entspricht
Format: rpush-Namenswert
String-Elemente am Ende der Liste hinzufügen, die dem Schlüssel entsprechen
Format: lrem-Namensindex
Zählelemente löschen aus die Liste, die dem Schlüssel entspricht, der mit dem Wertelement identisch ist
Format: llen name
Gibt die Länge der dem Schlüssel entsprechenden Liste zurück
Set (set)
Format: sadd name value
Redis' Set ist eine ungeordnete Sammlung von String-Typen.
Sammlungen werden über Hash-Tabellen implementiert, sodass die Komplexität des Hinzufügens, Löschens und Suchens O(1) beträgt.
zset (sortierte Menge: geordnete Menge)
Format: zadd name score value
Redis zset ist wie set auch eine Sammlung von Elementen vom Typ String, und Duplikate sind es nicht erlaubtes Mitglied.
Der Unterschied besteht darin, dass jedem Element eine doppelte Typbewertung zugeordnet ist. Redis verwendet Scores, um die Mitglieder der Sammlung von klein nach groß zu sortieren.
Die Mitglieder von zset sind einzigartig, aber die Ergebnisse können wiederholt werden.
Was ist Redis-Persistenz? Über welche Persistenzmethoden verfügt Redis? Was sind die Vor- und Nachteile?
Persistenz besteht darin, die Speicherdaten auf die Festplatte zu schreiben, um zu verhindern, dass die Speicherdaten verloren gehen, wenn der Dienst ausfällt.
Redis bietet zwei Persistenzmethoden: RDB (Standard) und AOF
RDB:
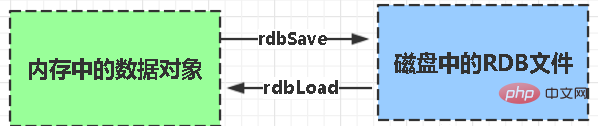
rdb ist die Abkürzung für Redis DataBase
Funktionskernfunktionen rdbSave (RDB-Datei generieren) und rdbLoad (Speicher aus Datei laden), zwei Funktionen
AOF:
Aof ist die Abkürzung für Append-only file
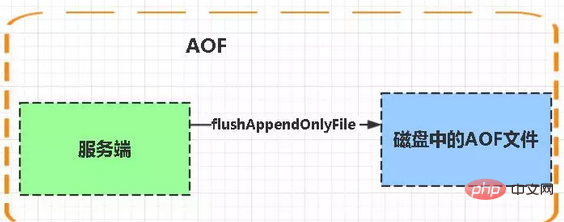
Die Funktion „flushAppendOnlyFile“ wird immer dann aufgerufen, wenn eine (geplante) Serveraufgabe oder -funktion ausgeführt wird. Diese Funktion führt die folgenden zwei Aufgaben aus
aof schreiben und speichern:
WRITE: Je nach Bedingungen den Cache in aof_buf in die AOF-Datei schreiben
SAVE: Je nach Bedingungen die Funktion fsync oder fdatasync aufrufen um die AOF-Datei auf der Festplatte zu speichern.
Speicherstruktur:
Der Inhalt ist eine Befehlstextspeicherung im Redis Communication Protocol (RESP)-Format.
Vergleich:
1. AOF-Dateien werden häufiger aktualisiert als RDB. Verwenden Sie daher zuerst aof, um Daten wiederherzustellen.
2. aof ist sicherer und größer als rdb
3. Wenn beide konfiguriert sind, wird AOF zuerst geladen
Sie haben gerade das Redis-Kommunikationsprotokoll (RESP) erwähnt. Können Sie erklären, was RESP ist? Was sind die Merkmale? (Sie sehen, dass es sich bei vielen Interviews tatsächlich um eine Reihe von Fragen handelt. Der Interviewer wartet tatsächlich darauf, dass Sie diesen Punkt beantworten. Wenn Sie die Frage beantworten, wird Ihrer Bewertung ein weiterer Punkt hinzugefügt.)RESP Es handelt sich um ein Kommunikationsprotokoll, das zuvor vom Redis-Client und -Server verwendet wurde.
Merkmale von RESP: einfache Implementierung, schnelles Parsen und gute Lesbarkeit
Bei einfachen Zeichenfolgen ist das erste Byte der Antwort „+“-Antwort
Bei Fehlern lautet das erste Byte der Antwort „-“ Fehler
Bei Ganzzahlen lautet das erste Byte der Antwort „:“ Ganzzahl
Bei Massen Bei Strings ist das erste Byte der Antwort „$“ String
Bei Arrays ist das erste Byte der Antwort „*“ Array
Welche Architekturmuster hat Redis? Sprechen Sie über ihre jeweiligen EigenschaftenStandalone-Version
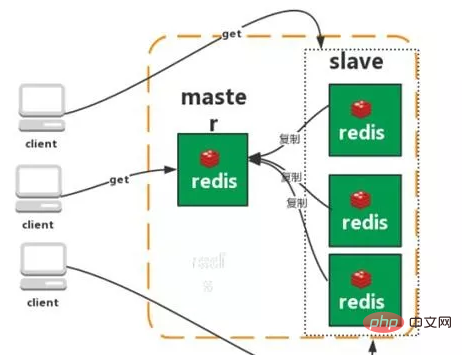
Funktionen: Einfach Probleme: 1. Begrenzte Speicherkapazität 2. Begrenzte Verarbeitungsleistung 3. Keine hohe Verfügbarkeit möglich. Master-Slave-Replikation Mit der Replikationsfunktion von Redis können Benutzer Daten basierend auf einem Redis-Server replizieren Erstellen Sie eine beliebige Anzahl von Replikaten des Servers, wobei der replizierte Server der Master ist und die durch die Replikation erstellten Serverrepliken Slaves sind. Solange die Netzwerkverbindung zwischen dem Master- und dem Slave-Server normal ist, verfügen der Master- und der Slave-Server über dieselben Daten, und der Master-Server aktualisiert und synchronisiert die ihm vorliegenden Daten stets mit dem Slave-Server und stellt so stets sicher, dass dies der Fall ist Die Daten des Master- und Slave-Servers sind gleich. Eigenschaften: 1. Master/Slave-Daten sind gleich 3 Übertragung zur Slave-Datenbank Problem: Hohe Verfügbarkeit kann nicht garantiert werden Der Druck des Master-Schreibens konnte nicht gelöst werden Überwachung: Sentinel überprüft ständig, ob Ihr Master-Server und Slave-Server normal funktionieren. Benachrichtigung: Wenn ein Problem mit einem überwachten Redis-Server auftritt, kann Sentinel über die API Benachrichtigungen an den Administrator oder andere Anwendungen senden. Automatisches Failover: Wenn ein Hauptserver nicht ordnungsgemäß funktionieren kann, startet Sentinel einen automatischen Failover-Vorgang. Funktionen: Gewährleisten Sie eine hohe Verfügbarkeit 2. Überwachen Sie jeden Knoten Nachteile: Hauptsächlich Vom Modus aus dauert es einige Zeit, bis der Wechsel Daten verliert Löst nicht den Druck des Master-Schreibens Twemproxy ist ein schneller/leichtgewichtiger Twitter-Open-Source-Redis- und Memcache-Proxyserver; Twemproxy ist ein schnelles Single-Threaded-Proxy-Programm, das das Memcached ASCII-Protokoll und das Redis-Protokoll unterstützt. 2. Unterstützt das automatische Löschen ausgefallener Knoten 3 Die Sharding-Sharding-Logik auf der Endseite ist für das Unternehmen transparent, und die Lese- und Schreibmethoden der Geschäftsseite stimmen mit dem Betrieb eines einzelnen Redis überein Nachteile: Ein neuer Proxy wird hinzugefügt und seine hohe Verfügbarkeit muss aufrechterhalten werden . Die Failover-Logik muss von Ihnen selbst implementiert werden. Sie kann keine automatische Fehlerübertragung unterstützen und weist eine schlechte Skalierbarkeit auf.
Ab Redis 3.0 wird Redis-Cluster unterstützt Struktur, jeder Knoten speichert Daten und den gesamten Clusterstatus, jeder Knoten ist mit allen anderen Knoten verbunden. 1. Keine zentrale Architektur (kein Knoten beeinträchtigt die Leistung), keine Proxy-Schicht. 2. Daten werden in mehreren Knoten entsprechend den Slots gespeichert und verteilt. Die Daten werden zwischen den Knoten geteilt und die Datenverteilung kann dynamisch angepasst werden. 3. Skalierbarkeit, kann linear auf 1000 Knoten erweitert werden und Knoten können dynamisch hinzugefügt oder gelöscht werden. 4. Hohe Verfügbarkeit, der Cluster ist weiterhin verfügbar, wenn einige Knoten nicht verfügbar sind. Durch das Hinzufügen eines Slaves zum Erstellen einer Sicherungsdatenkopie 5 wird ein automatisches Failover erreicht. Die Knoten tauschen Statusinformationen über das Gossip-Protokoll aus und nutzen den Abstimmungsmechanismus, um die Rollenförderung vom Slave zum Master abzuschließen. Nachteile: 1. Die Ressourcenisolierung ist schlecht und es kann leicht zu gegenseitiger Beeinflussung kommen. 2. Daten werden asynchron kopiert und eine starke Datenkonsistenz ist nicht garantiert Gemeinsame Redis-Befehle? Schlüsselmuster* bedeutet, dass alle beginnend mit Bit zugewiesen werden Überprüfen Sie, ob der Exists-Schlüssel vorhanden ist Setzen Sie Setzen Sie den Wert, der dem Schlüssel entspricht, auf einen Wert vom Typ Zeichenfolge. setnx Setzen Sie den Wert, der dem Schlüssel entspricht, auf einen Wert vom Typ Zeichenfolge. Wenn der Schlüssel bereits vorhanden ist, geben Sie 0 zurück. nx bedeutet, dass er nicht vorhanden ist. Einen Schlüssel löschen Beim ersten Mal 1 zurückgeben, beim Löschen beim zweiten Mal 0 zurückgeben Ablauf Ablaufzeit festlegen (in Sekunden) TTL-Ansicht Wie viel Zeit noch übrig ist Wenn eine negative Zahl zurückgegeben wird, ist der Schlüssel ungültig und der Schlüssel existiert nicht Setex Stellen Sie den entsprechenden Wert ein Schlüssel zu einem Wert vom Typ Zeichenfolge und geben Sie den entsprechenden Wert der Gültigkeitsdauer dieses Schlüssels an. Mset Wenn Sie bei Erfolg die Werte mehrerer Schlüssel gleichzeitig festlegen, bedeutet dies, dass alle Werte festgelegt sind. Bei einem Fehler bedeutet die Rückgabe von 0, dass kein Wert festgelegt ist. Getset Legen Sie den Wert des Schlüssels fest und geben Sie den alten Wert des Schlüssels zurück. Mget Erhalten Sie die Werte mehrerer Schlüssel gleichzeitig. Wenn der entsprechende Schlüssel nicht vorhanden ist, wird entsprechend Null zurückgegeben. Incr Fügt den Wert des Schlüssels hinzu und gibt den neuen Wert zurück. Beachten Sie, dass incr einen Wert zurückgibt, der nicht int ist, einen Fehler zurückgibt. Incr gibt einen nicht vorhandenen Schlüssel aus. Setzen Sie dann den Schlüssel auf 1. incrby ähnelt incr und fügt den angegebenen Wert hinzu , und es wird gesetzt, wenn der Schlüssel nicht existiert, und geht davon aus, dass der ursprüngliche Wert 0 ist. Decr führt eine Subtraktionsoperation für den Wert des Schlüssels durch, wenn decr dies nicht tut existieren, setzen Sie den Schlüssel auf -1 Decrby Dasselbe wie decr, minus dem angegebenen Wert. Anhängen Wert an den Zeichenfolgenwert des angegebenen Schlüssels anhängen und die Länge des neuen Zeichenfolgenwerts zurückgeben. Strlen Ermitteln Sie die Länge des Werts des angegebenen Schlüssels. xxx beibehalten (Ablaufzeit löschen) Datenbank auswählen (Datenbank 0-15) 0 auswählen //Datenbank auswählen Alter verschieben 1// Alter in Bibliothek 1 verschieben Randomkey gibt einen zufälligen Schlüssel zurück Rename rename Type gibt den Datentyp zurück 08 Haben Sie jemals die verteilte Redis-Sperre verwendet? Verwenden Sie zuerst setnx, um die Sperre zu ergreifen. Nachdem Sie sie ergriffen haben, fügen Sie der Sperre mit „expire“ eine Ablaufzeit hinzu, um zu verhindern, dass die Sperre vergisst, sie freizugeben. Was passiert, wenn der Prozess unerwartet abstürzt oder aus Wartungsgründen neu gestartet werden muss, bevor er „expire after setnx“ ausführt? Die Set-Anweisung hat sehr komplexe Parameter. Dadurch sollte es möglich sein, Setnx und Expire gleichzeitig in einer Anweisung zu kombinieren! 09 Haben Sie Redis jemals als asynchrone Warteschlange verwendet? Was sind die Nachteile? Im Allgemeinen wird die Listenstruktur als Warteschlange verwendet, rpush erzeugt Nachrichten und lpop verbraucht Nachrichten. Wenn keine Nachricht von lpop eingeht, schlafen Sie eine Weile und versuchen Sie es erneut. Nachteile: Wenn der Verbraucher offline geht, gehen die produzierten Nachrichten verloren, sodass Sie eine professionelle Nachrichtenwarteschlange wie Rabbitmq verwenden müssen. Kann ich einmal produzieren und mehrmals konsumieren? Mit dem Pub/Sub-Themen-Abonnentenmodus kann eine 1:N-Nachrichtenwarteschlange erreicht werden. 10 Was ist Cache-Penetration? Wie kann man es vermeiden? Was ist eine Cache-Lawine? Wie kann man es vermeiden? Cache-Penetration Allgemeine Cache-System-Cache-Abfragen basierend auf dem Schlüssel. Wenn der entsprechende Wert nicht vorhanden ist, sollte er im Back-End-System (z. B. DB) gesucht werden. Bei einigen böswilligen Anfragen werden absichtlich nicht vorhandene Schlüssel abgefragt. Wenn das Anfragevolumen groß ist, wird das Back-End-System stark belastet. Dies wird als Cache-Penetration bezeichnet. Wie kann man es vermeiden? 1: Das Abfrageergebnis wird auch zwischengespeichert, wenn es leer ist. Die Cache-Zeit wird kürzer eingestellt oder der Cache wird geleert, nachdem die dem Schlüssel entsprechenden Daten eingefügt wurden. 2: Schlüssel filtern, die nicht vorhanden sein dürfen. Sie können alle möglichen Schlüssel in eine große Bitmap einfügen und bei der Abfrage durch die Bitmap filtern. Cache-Lawine Wenn der Cache-Server neu gestartet wird oder eine große Anzahl von Caches in einem bestimmten Zeitraum ausfällt, wird das Back-End-System stark unter Druck gesetzt. was zum Absturz des Systems führt. Wie kann man es vermeiden? 1: Steuern Sie nach Ablauf des Caches die Anzahl der Threads, die die Datenbank lesen und in den Cache schreiben, indem Sie Sperren oder Warteschlangen verwenden. Beispielsweise darf nur ein Thread Daten abfragen und Cache für einen bestimmten Schlüssel schreiben, während andere Threads warten. 2: Erstellen Sie einen Cache der zweiten Ebene. A1 ist der Original-Cache, A2 ist der Kopier-Cache. Wenn A1 ausfällt, können Sie auf A2 zugreifen. Die Cache-Ablaufzeit von A1 ist auf kurzfristig eingestellt A2 ist auf Langzeit eingestellt 3 : Unterschiedliche Schlüssel, unterschiedliche Ablaufzeiten festlegen, damit die Cache-Ungültigmachungszeit möglichst gleichmäßig ist. 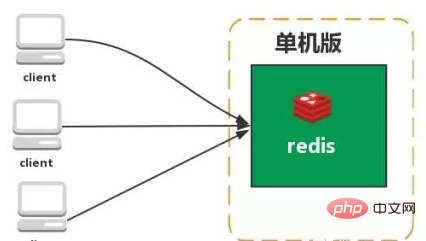
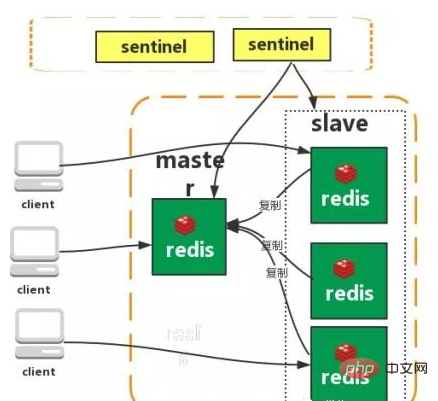 Redis Sentinel ist ein verteiltes System, das Redis-Master- und -Slave-Server überwacht und automatisch ein Failover durchführt, wenn der Master-Server offline geht. Drei der Funktionen:
Redis Sentinel ist ein verteiltes System, das Redis-Master- und -Slave-Server überwacht und automatisch ein Failover durchführt, wenn der Master-Server offline geht. Drei der Funktionen: 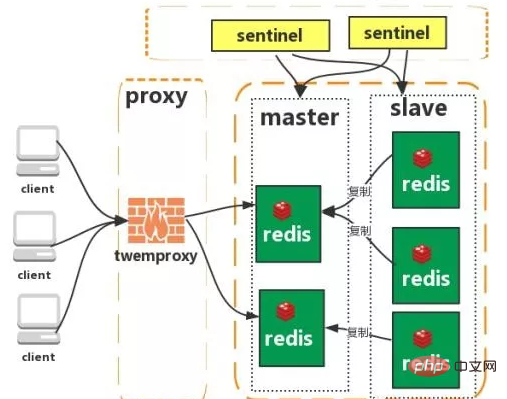 Funktionen: 1. Mehrere Hash-Algorithmen: MD5, CRC16, CRC32, CRC32a, hsieh, murmur, Jenkins
Funktionen: 1. Mehrere Hash-Algorithmen: MD5, CRC16, CRC32, CRC32a, hsieh, murmur, Jenkins 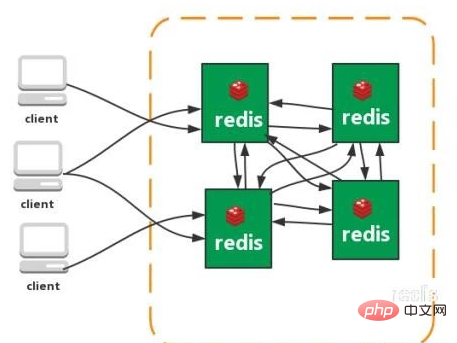 Funktionen:
Funktionen:
Das obige ist der detaillierte Inhalt vonTeilen Sie häufig gestellte Fragen zu Redis-Interviews. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist der Unterschied zwischen Sonnenfinsternis und Idee?
Was ist der Unterschied zwischen Sonnenfinsternis und Idee?
 So schließen Sie Secure Boot
So schließen Sie Secure Boot
 Der Unterschied zwischen Win10-Ruhezustand und Ruhezustand
Der Unterschied zwischen Win10-Ruhezustand und Ruhezustand
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 ich sage
ich sage
 Software zur Website-Erstellung
Software zur Website-Erstellung
 Win11 überspringt das Tutorial, um sich beim Microsoft-Konto anzumelden
Win11 überspringt das Tutorial, um sich beim Microsoft-Konto anzumelden
 Eigenschaften der Zweierkomplementarithmetik
Eigenschaften der Zweierkomplementarithmetik











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



