


Eine einzelne Tabellenabfrage bezieht sich auf die Abfrage von Daten in einer Tabelle. Die Ausführungsreihenfolge lautet „von->wo->gruppieren nach->mit->eindeutig->Reihenfolge nach- >limit-“. >auswählen".

Bei Datenbankoperationen dient die Einzeltabellenabfrage dazu, Daten in einer Tabelle abzufragen. Die detaillierte Syntax lautet:
select distinct 字段1,字段2... from 表名 where 分组之前的过滤条件 group by 分组字段 having 分组之后的过滤条件 order by 排序字段 limit 显示的条数;
Die Grammatik ist in dieser Reihenfolge, aber ihre Ausführungsreihenfolge basiert nicht auf der Reihenfolge der Grammatik, sondern auf dieser Reihenfolge.
von--->wo--->gruppieren nach--->mit-->eindeutig--->sortieren nach--->limit--- >wählen
Was den Grund für eine solche Ausführungssequenz betrifft, werde ich ihn nicht sagen, und ich habe nicht das Vertrauen, ihn klar zu erklären. Wenn Sie ein Anfänger sind, müssen Sie sich nur diese Ausführungssequenz merken. Wenn Sie mehr erfahren möchten, können Sie zu Google gehen.
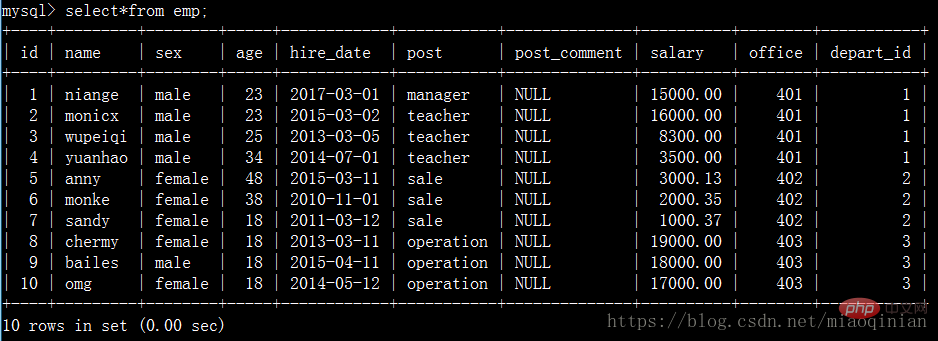
Bevor wir die Einzeltabellenabfrage verstehen, erstellen wir zunächst eine Mitarbeitertabelle:
emp表: 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int
Erstellen Sie die Tabelle:
create table emp( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, depart_id int );
Daten einfügen:
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('niange','male',23,'20170301','manager',15000,401,1), ('monicx','male',23,'20150302','teacher',16000,401,1), ('wupeiqi','male',25,'20130305','teacher',8300,401,1), ('yuanhao','male',34,'20140701','teacher',3500,401,1), ('anny','female',48,'20150311','sale',3000.13,402,2), ('monke','female',38,'20101101','sale',2000.35,402,2), ('sandy','female',18,'20110312','sale',1000.37,402,2), ('chermy','female',18,'20130311','operation',19000,403,3), ('bailes','male',18,'20150411','operation',18000,403,3), ('omg','female',18,'20140512','operation',17000,403,3);
kann in Where-Klauseln verwendet werden:
1. !=.
2. zwischen 1 und 5 Der Wert liegt zwischen 1 und 5.
3. Der Wert in(1,3,8) ist 1 oder 3 oder 8.
4. wie „monicx%“
% steht für eine beliebige Anzahl von Zeichen
_ steht für ein Zeichen
5. Logische Operatoren können direkt in mehreren Bedingungen verwendet werden , oder, nicht.
6. Regulärer Ausdruck
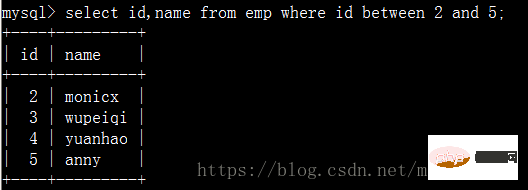
Suchen Sie die Namen von Mitarbeitern mit IDs zwischen 2 und 5:
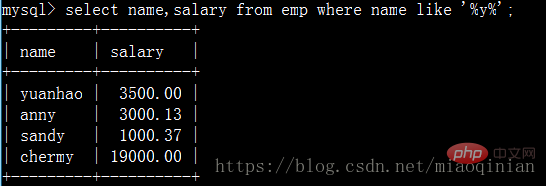
Fragen Sie die Namen von Mitarbeitern ab, deren Namen den Buchstaben y enthalten, und deren Gehälter:
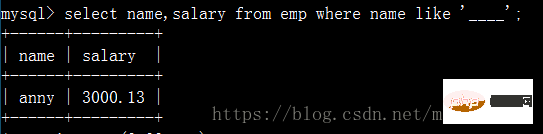
Fragen Sie die Namen von Mitarbeitern ab, deren Namen aus vier Zeichen bestehen Und sein Gehalt:
Fragen Sie den Mitarbeiternamen und den Positionsnamen mit leerer Stellenbeschreibung ab:
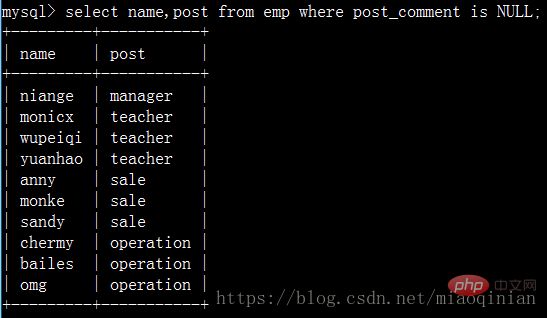
Suchen Sie nach Mitarbeitern, deren Namen mit dem Buchstaben m beginnen und mit dem Buchstaben e oder x enden! Sie können derzeit reguläre Ausdrücke verwenden. MySQL bietet reguläre Ausdrücke, um reguläre Ausdrücke auszudrücken.

Setzen Sie zunächst den sql_mode von mysq auf only_full_group_by, was bedeutet, dass in Zukunft nur noch die Basis für Gruppierung kann erhalten werden.
set global sql_mode="strict_trans_tables,only_full_group_by";
Die Gruppierung erfolgt nach wo, d. h. die Gruppierung basiert auf den nach wo erhaltenen Datensätzen.
Gruppierung bezieht sich auf die Kategorisierung aller Datensätze nach demselben Feld, z. B. Positionsgruppierung für Mitarbeiterinformationstabellen oder Gruppierung nach Geschlecht usw.
Wie gruppiert man?
Zum Beispiel: Nehmen Sie das höchste Gehalt jeder Abteilung.
Zum Beispiel: Ermitteln Sie die Anzahl der Mitarbeiter in jeder Abteilung.
Das Feld nach dem Wort „every“ ist die Grundlage für unsere Gruppierung.
Hinweis: Wir können nach jedem Feld gruppieren, aber nach der Gruppierung, z. B. nach Beitrag gruppieren, können wir nur das Beitragsfeld anzeigen.
Aber wenn Sie die Informationen innerhalb der Gruppe anzeigen möchten, müssen Sie die Aggregation verwenden (zusammenfassen, um einen Inhalt zu synthetisieren) Funktion
每个部门的最高工资 select post,max(salary) from emp group by post; 每个部门的最底工资 select post,min(salary) from emp group by post; 每个部门的平均工资 select post,avg(salary) from emp group by post; 每个部门的工资总合 select post,sum(salary) from emp group by post; 每个部门的总人数 select post,count(id) from emp group by post;
group_concat (wird nach der Gruppierung verwendet, um den Inhalt der Felder in der Gruppe abzurufen.)
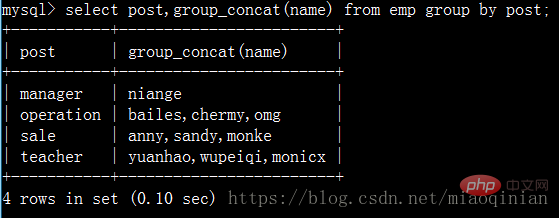
Und es kann auch so sein Sub-Use:
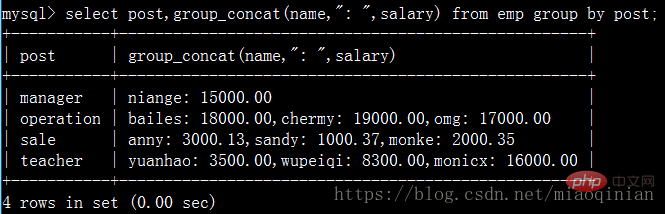
Du kannst es selbst mit folgendem Code ausprobieren:
select post,group_concat(name) from emp group by post; select post,group_concat(name,"_NB") from emp group by post; select post,group_concat(name,": ",salary) from emp group by post; select post,group_concat(salary) from emp group by post;
Das werden weise Mitschüler sagen Können Sie es ohne Gruppierung verwenden? NEIN! Aber MySQL bietet eine andere Möglichkeit zum Betrieb. Es ist konkat.
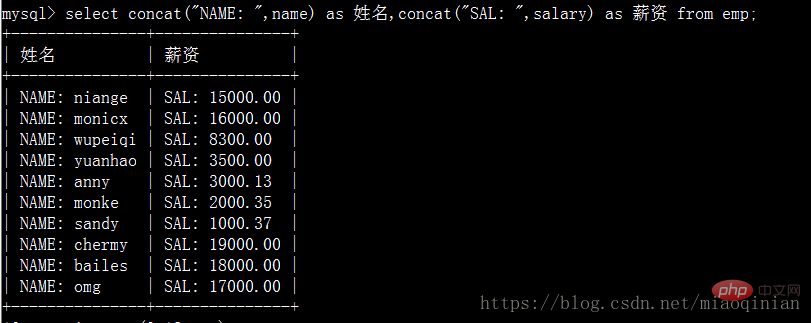
# 补充as语法
mysql> select emp.id,emp.name from emp as t1; # 报错
mysql> select t1.id,t1.name from emp as t1;Gruppe nach Das ist alles. Wenn Sie es immer noch nicht verstehen, können Sie die folgenden kleinen Übungen machen.
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(id) from emp group by post;
3. 查询公司内男员工和女员工的个数
select sex,count(id) from emp group by sex;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
8、统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age >= 30 group by post;Das Syntaxformat von have ist genau das gleiche wie where, außer dass have nach der Gruppierung weiter gefiltert wird.
where不能用聚合函数,但having是可以用聚合函数,这也是它们最大的区别。
统计各部门年龄在24岁以上的员工平均工资,并且保留平均工资大于4000的部门。
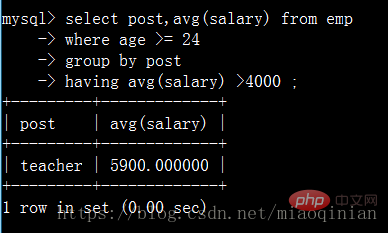
注意:having只能与 select 语句一起使用。
having通常在 group by 子句中使用。
如果不使用 group by子句,不会报错,但会出现以下的情况。

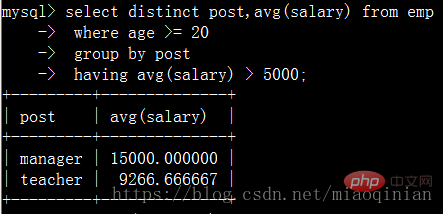
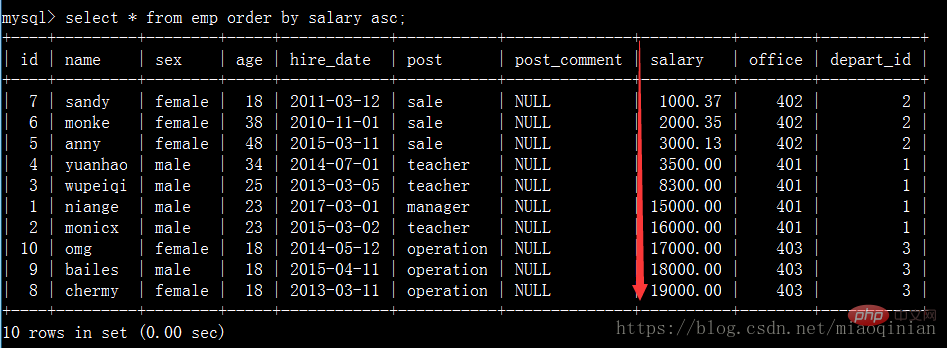
select * from emp order by salary asc; #默认升序排 select * from emp order by salary desc; #降序排 select * from emp order by age desc; #降序排 select * from emp order by age desc,salary asc; #先按照age降序排,再按照薪资升序排
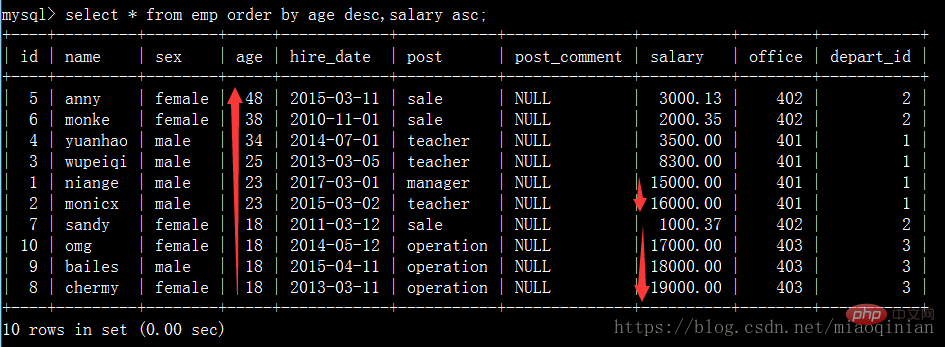

如查要获取工资最高的员工的信息,我们可以用order by和limit也可以做到。

如果查一个表数据量大的话可以用limit分页显示。
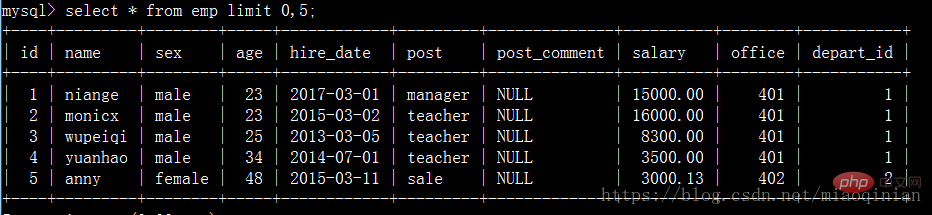
select * from emp limit 0,5;
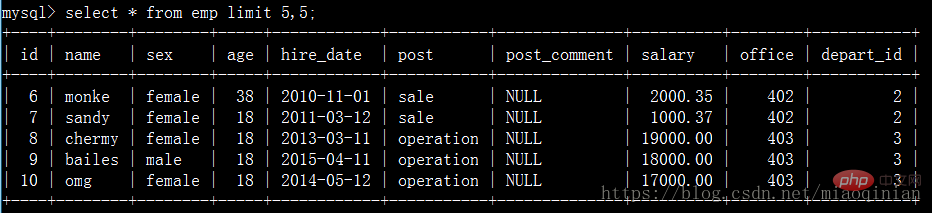
select * from emp limit 5,5;
ps:看到这里如果上面的东西你都明白的话,单表查询你基本上已经熟悉它了。
Das obige ist der detaillierte Inhalt vonWas ist eine einzelne Tabellenabfrage?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Win10-Tutorial zum Abrufen von Arbeitsplatzsymbolen
Win10-Tutorial zum Abrufen von Arbeitsplatzsymbolen
 Linux-Netzwerkkarte anzeigen
Linux-Netzwerkkarte anzeigen
 Welche Börse ist EDX?
Welche Börse ist EDX?
 Kostenloser Quellcode für persönliche Websites
Kostenloser Quellcode für persönliche Websites
 So verwenden Sie die Sortierfunktion
So verwenden Sie die Sortierfunktion
 So aktivieren Sie das Win7 Professional-Versionssystem
So aktivieren Sie das Win7 Professional-Versionssystem
 Verwendung von UpdatePanel
Verwendung von UpdatePanel
 Anforderungen an die Computerkonfiguration für die Python-Programmierung
Anforderungen an die Computerkonfiguration für die Python-Programmierung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



