


Die Grundidee des Lastausgleichs ist einfach: Die Last in einem Servercluster so weit wie möglich mitteln. Basierend auf dieser Idee besteht unser üblicher Ansatz darin, einen Load Balancer am Frontend des Servers einzurichten. Die Rolle des Load Balancers besteht darin, angeforderte Verbindungen an den inaktivsten verfügbaren Server weiterzuleiten.
Abbildung 1 zeigt die Einrichtung eines großen Website-Lastausgleichs. Einer ist für den HTTP-Verkehr verantwortlich und der andere für den MySQL-Zugriff.
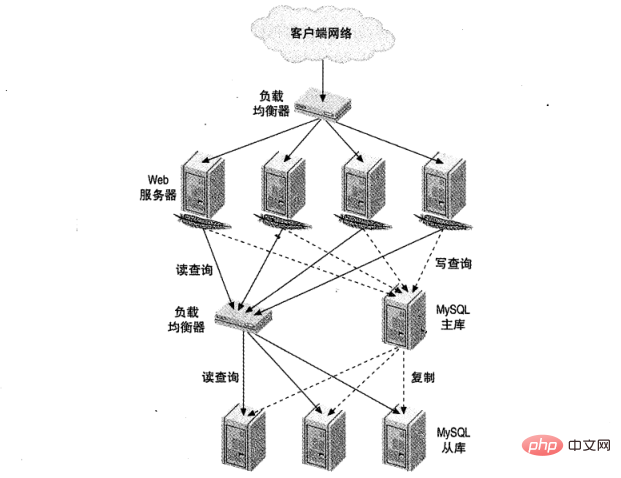
Lastausgleich hat fünf gemeinsame Zwecke:
Für die Implementierung des Lastausgleichs gibt es im Allgemeinen zwei Möglichkeiten: direkte Verbindung und Einführung von Middleware.
Verwandte Tutorials: MySQL-Video-Tutorial
Manche Leute denken, dass beim Lastausgleich etwas direkt zwischen der Anwendung und MySQL konfiguriert werden soll Server, aber tatsächlich ist dies nicht die einzige Lastausgleichsmethode. Als Nächstes besprechen wir gängige Anwendungsdirektverbindungsmethoden und entsprechende Vorsichtsmaßnahmen.
Bei dieser Methode tritt häufig eines der größten Probleme auf: schmutzige Daten. Ein typisches Beispiel ist, wenn ein Benutzer einen Blog-Beitrag kommentiert und dann die Seite neu lädt, den neuen Kommentar jedoch nicht sieht.
Natürlich können wir die Lese-/Schreibtrennung nicht nur wegen des Problems schmutziger Daten aufgeben. Tatsächlich kann die Toleranz für schmutzige Daten bei vielen Anwendungen relativ hoch sein, und diese Methode kann zu diesem Zeitpunkt mutig eingeführt werden.
Wie kann man also bei Anwendungen, die eine geringe Toleranz gegenüber schmutzigen Daten haben, Lesen und Schreiben trennen? Als nächstes werden wir weiter zwischen Lese- und Schreibtrennung unterscheiden. Ich glaube, dass Sie immer eine Strategie finden können, die zu Ihnen passt.
1) Basierend auf der Abfragetrennung
Wenn die Anwendung nur über eine kleine Datenmenge verfügt, die schmutzige Daten nicht tolerieren kann, können wir alle Lese- und Schreibvorgänge zuordnen, die dies nicht tolerieren schmutzige Daten an den Master. Andere Leseabfragen werden auf dem Slave zugewiesen. Diese Strategie ist einfach zu implementieren, aber wenn es relativ wenige Abfragen gibt, die schmutzige Daten tolerieren, ist es wahrscheinlich, dass die Standby-Datenbank nicht effektiv genutzt werden kann.
2) Trennung basierend auf schmutzigen Daten
Dies ist eine kleine Verbesserung der abfragebasierten Trennungsstrategie. Es sind einige zusätzliche Arbeiten erforderlich, z. B. muss die Anwendung die Replikationslatenz prüfen, um festzustellen, ob die Standby-Daten aktuell sind. Viele Berichtsanwendungen können diese Strategie verwenden: Sie müssen nur die nachts geladenen Daten auf die Standby-Datenbankschnittstelle kopieren, und es ist ihnen egal, ob sie die Hauptdatenbank vollständig eingeholt haben.
3) Sitzungsbasierte Trennung
Diese Strategie geht tiefer als die Strategie zur Trennung schmutziger Daten. Es bestimmt, ob der Benutzer die Daten geändert hat. Der Benutzer muss nicht die neuesten Daten anderer Benutzer sehen, sondern nur seine eigenen Aktualisierungen.
Insbesondere kann in der Sitzungsschicht ein Flag-Bit gesetzt werden, um anzuzeigen, ob der Benutzer ein Update durchgeführt hat. Sobald der Benutzer ein Update durchführt, wird die Anfrage des Benutzers für einen bestimmten Zeitraum an die Hauptdatenbank weitergeleitet .
Diese Strategie stellt einen guten Kompromiss zwischen Einfachheit und Wirksamkeit dar und ist eine empfehlenswertere Strategie.
Wenn Sie überlegt genug sind, können Sie natürlich die sitzungsbasierte Trennungsstrategie mit der Strategie zur Überwachung der Replikationslatenz kombinieren. Wenn der Benutzer die Daten vor 10 Sekunden aktualisiert hat und alle Verzögerungen in der Standby-Datenbank innerhalb von 5 Sekunden liegen, können Sie problemlos Daten aus der Standby-Datenbank lesen. Es ist zu beachten, dass Sie für die gesamte Sitzung dieselbe Standby-Datenbank auswählen müssen. Andernfalls kann es zu Problemen für Benutzer kommen, sobald die Verzögerungen mehrerer Standby-Datenbanken inkonsistent sind.
4) Basierend auf globaler Versions-/Sitzungstrennung
Bestätigen Sie, ob die Standby-Datenbank aktualisierte Daten hat, indem Sie die Protokollkoordinaten der Hauptdatenbank aufzeichnen und sie mit den kopierten vergleichen Koordinaten der Standby-Datenbank. Wenn die Anwendung auf einen Schreibvorgang zeigt, führen Sie nach dem Festschreiben der Transaktion einen SHOW MASTER STATUS-Vorgang aus und speichern Sie dann die Master-Protokollkoordinaten im Cache als Versionsnummer des geänderten Objekts oder der geänderten Sitzung. Wenn die Anwendung eine Verbindung zur Standby-Datenbank herstellt, führen Sie SHOW SLAVE STATUS aus und vergleichen Sie die Koordinaten in der Standby-Datenbank mit der Versionsnummer im Cache. Wenn die Standby-Datenbank neuer als der Hauptdatenbank-Eintragspunkt ist, bedeutet dies, dass die Standby-Datenbank die entsprechenden Daten aktualisiert hat und sicher verwendet werden kann.
Tatsächlich erfordern viele Strategien zur Lese-Schreib-Trennung eine Überwachung der Replikationslatenz, um die Zuordnung von Leseabfragen zu bestimmen. Es ist jedoch zu beachten, dass der von SHOW SLAVE STATUS erhaltene Wert der Spalte Seconds_behind_master die Verzögerung nicht genau wiedergibt. Wir können das pt-heartbeat-Tool im Percona Toolkit verwenden, um die Latenz besser zu überwachen.
Für einige einfachere Anwendungen kann DNS für verschiedene Zwecke erstellt werden. Die einfachste Methode besteht darin, einen DNS-Namen für den schreibgeschützten Server (read.mysql-db.com) und einen anderen DNS-Namen für den Server zu verwenden, der für Schreibvorgänge verantwortlich ist (write.mysql-db.com). Wenn die Standby-Datenbank mit der Primärdatenbank mithalten kann, verweisen Sie den schreibgeschützten DNS-Namen auf die Standby-Datenbank, andernfalls auf die Primärdatenbank.
Diese Strategie ist sehr einfach umzusetzen, es gibt jedoch ein großes Problem: Sie kann DNS nicht vollständig kontrollieren.
Diese Strategie ist gefährlicher. Auch wenn das Problem, dass DNS nicht vollständig kontrolliert werden kann, durch Ändern der Datei /etc/hosts vermieden werden kann, ist es dennoch eine ideale Strategie.
Erreichen Sie einen Lastausgleich durch die Übertragung virtueller Adressen zwischen Servern. Fühlt es sich ähnlich an, als würde man DNS ändern? Aber in Wirklichkeit sind es völlig verschiedene Dinge. Durch die Übertragung der IP-Adresse bleibt der DNS-Name unverändert. Wir können erzwingen, dass die Änderung der IP-Adresse schnell und atomar dem lokalen Netzwerk über den ARP-Befehl mitgeteilt wird (ich weiß nichts über ARP, siehe hier).
Eine praktische Technik besteht darin, jedem physischen Server eine feste IP-Adresse zuzuweisen. Diese IP-Adresse ist auf dem Server festgelegt und ändert sich nicht. Sie können dann für jeden logischen „Dienst“ (der als Container verstanden werden kann) eine virtuelle IP-Adresse verwenden.
Auf diese Weise kann IP problemlos zwischen Servern übertragen werden, ohne dass die Anwendung neu konfiguriert werden muss, und die Implementierung ist einfacher.
Bei den oben genannten Strategien wird davon ausgegangen, dass die Anwendung mit dem MySQL-Server verbunden ist. Bei vielen Lastausgleichssystemen wird jedoch eine Middleware als Proxy für die Netzwerkkommunikation eingeführt. Es akzeptiert die gesamte Kommunikation auf der einen Seite, verteilt diese Anfragen an den angegebenen Server auf der anderen Seite und sendet die Ausführungsergebnisse zurück an den anfragenden Rechner. Abbildung 2 veranschaulicht diese Architektur. 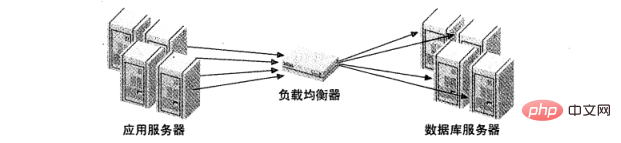
Es gibt viele Load-Balancing-Hardware und -Software, aber nur wenige sind speziell für MySQL-Server konzipiert. Webserver haben im Allgemeinen einen größeren Bedarf an Lastausgleich, daher unterstützen viele universelle Lastausgleichsgeräte HTTP und verfügen nur über wenige grundlegende Funktionen für andere Zwecke.
MySQL-Verbindungen sind nur normale TCP/IP-Verbindungen, sodass Sie einen Mehrzweck-Load-Balancer auf MySQL verwenden können. Aufgrund des Fehlens von MySQL-spezifischen Funktionen wird es jedoch einige weitere Einschränkungen geben:
Es gibt viele Algorithmen, die verwendet werden, um zu entscheiden, welcher Server die nächste Verbindung akzeptiert. Jeder Hersteller hat seinen eigenen Algorithmus und die folgenden gängigen Methoden sind:
Unter den oben genannten Methoden gibt es keine beste, sondern nur die am besten geeignete, abhängig von der spezifischen Arbeitsbelastung.
Außerdem beschreiben wir den Algorithmus nur für die sofortige Verarbeitung. Manchmal kann es jedoch effizienter sein, einen Warteschlangenalgorithmus zu verwenden. Beispielsweise könnte ein Algorithmus nur eine bestimmte Datenbankserver-Parallelität aufrechterhalten und nicht mehr als N aktive Transaktionen gleichzeitig zulassen. Wenn zu viele aktive Transaktionen vorhanden sind, werden neue Anfragen in eine Warteschlange gestellt und von der Liste der verfügbaren Server bearbeitet.
Die häufigste Replikationsstruktur ist eine Master-Datenbank plus mehrere Backup-Datenbanken. Diese Architektur weist eine schlechte Skalierbarkeit auf, aber wir können bessere Ergebnisse erzielen, indem wir sie mit einigen Methoden zum Lastausgleich kombinieren.
Wir können und sollten nicht gleich zu Beginn der Anwendung darüber nachdenken, die Architektur wie Alibaba zu gestalten. Der beste Weg besteht darin, das zu implementieren, was Ihre Anwendung heute eindeutig benötigt, und im Voraus zu planen für ein mögliches schnelles Wachstum.
Außerdem ist es sinnvoll, ein numerisches Ziel für die Skalierbarkeit zu haben, genauso wie wir ein genaues Ziel für die Leistung haben und 10.000 oder 100.000 Parallelität erreichen. Dadurch kann vermieden werden, dass Overhead-Probleme wie Serialisierung oder Interoperabilität durch relevante Theorien in unsere Anwendungen einfließen.
Wenn eine typische Anwendung eine sehr große Größe erreicht, wird im Hinblick auf die MySQL-Erweiterungsstrategie in der Regel zunächst von einem einzelnen Server auf eine Scale-out-Architektur mit Standby-Datenbanken und dann auf Daten-Sharding oder funktionale Partitionierung umgestellt . An dieser Stelle ist zu beachten, dass wir Ratschläge wie „so früh wie möglich splittern, so viel wie möglich splittern“ nicht befürworten. Tatsächlich ist Sharding komplex und kostspielig, und was am wichtigsten ist: Viele Anwendungen benötigen es möglicherweise überhaupt nicht. Anstatt viel Geld für Sharding auszugeben, ist es besser, einen Blick auf die Änderungen in neuer Hardware und neuen Versionen von MySQL zu werfen. Vielleicht werden Sie diese neuen Änderungen überraschen.
ist ein quantitativer Indikator für Skalierbarkeit.
Abschließend hoffe ich, dass dieser Artikel für Sie hilfreich ist.
Das obige ist der detaillierte Inhalt vonMySQL erklärt den Lastausgleich in einfachen Worten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



