


Dieser Artikel bietet Ihnen eine kurze Einführung in die Vorverarbeitung und Heatmaps in Python. Ich hoffe, dass er für Freunde hilfreich ist.
Es gibt immer noch viele Dinge in der Datenanalyse. Nachdem ich diesen Aspekt verstanden habe, kann ich hoffen, dass dies für alle hilfreich ist.
Dieses Mal verwenden wir immer noch den Iris-Datensatz in sklearn und zeigen ihn über eine Heatmap an.
Vorverarbeitung
sklearn.preprocessing ist ein Vorverarbeitungsmodul in der Bibliothek für maschinelles Lernen, das die Daten standardisieren, regulieren usw. und je nach Bedarf verwenden kann. Hier wird seine standardisierte Methode zur Organisation der Daten verwendet. Andere Methoden können Sie selbst abfragen.
Standardisierung: Passen Sie die Verteilung der Merkmalsdaten an eine Standardnormalverteilung an, auch Gaußsche Verteilung genannt, was bedeutet, dass der Mittelwert der Daten 0 und die Varianz 1 beträgt.
Der Grund für die Standardisierung besteht darin, dass eine zu große Varianz einiger Merkmale die Zielfunktion dominiert und den Parameterschätzer daran hindert, andere Merkmale korrekt zu lernen.
Der Standardisierungsprozess besteht aus zwei Schritten: Dezentralisierung des Mittelwerts (der Mittelwert wird zu 0); Skalierung der Varianz (die Varianz wird zu 1).
stellt eine Skalierungsmethode in sklearn.preprocessing bereit, um die oben genannten Funktionen zu erreichen.
Nehmen wir ein Beispiel:
from sklearn import preprocessing
import numpy as np
# 创建一组特征数据,每一行表示一个样本,每一列表示一个特征
xx = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
# 将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
xx_scale = preprocessing.scale(xx)
xx_scaleDas Ergebnis nach der Normalisierung der Daten in jeder Spalte ist:
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])Wie Sie sehen können, sind die darin enthaltenen Daten passiert. Die Änderungen, die Zahlenwerte sind relativ klein, vielleicht kann jemand es auf einen Blick erkennen, aber es macht nichts, wenn er es nicht sehen kann. Python kann einige seiner Statistiken leicht berechnen.
# 测试一下xx_scale每列的均值方差 print('均值:', xx_scale.mean(axis=0)) # axis=0指列,axis=1指行 print('方差:', xx_scale.std(axis=0))
Oben wurde bereits erläutert, in was die Standardisierung umgewandelt werden soll, und die Ergebnisse sind tatsächlich konsistent. Die Ergebnisse der Berechnung des Mittelwerts und der Varianz pro Spalte sind:
均值: [0. 0. 0.] 方差: [1. 1. 1.]
Natürlich für Standardisierung, Varianz und Mittelwert. Manchmal möchte man beispielsweise nur von einer der Methoden profitieren:
with_mean, with_std sind boolesche Parameter, die standardmäßig beide „true“ sind, aber auch auf „false“ angepasst werden können. Das bedeutet, dass die Varianz nicht zentriert oder nicht auf 1 skaliert werden soll >
Ich werde die Heatmap hier nur kurz erwähnen, da es im Internet bereits viele detaillierte Informationen dazu gibt. In einer Heatmap liegen die Daten in Form einer Matrix vor und der Attributbereich wird durch einen Farbverlauf dargestellt. Hier wird pcolor zum Zeichnen der Heatmap verwendet.
Little Lizi
Beginnen Sie mit der Importbibliothek, laden Sie dann den Datensatz, verarbeiten Sie die Daten, zeichnen Sie dann das Bild, machen Sie einige Anmerkungen und Dekorationen auf dem Bild usw. Ich bin es gewohnt, im Code Kommentare abzugeben. Wenn Sie etwas nicht verstehen, können Sie eine Nachricht hinterlassen und ich werde rechtzeitig antworten.
# 导入后续所需要的库 from sklearn.datasets import load_iris from sklearn.preprocessing import scale import numpy as np import matplotlib.pyplot as plt # 加载数据集 data = load_iris() x = data['data'] y = data['target'] col_names = data['feature_names'] # 数据预处理 # 根据平均值对数据进行缩放 x = scale(x, with_std=False) x_ = x[1:26,] # 选取其中25组数据 y_labels = range(1, 26) # 绘制热图 plt.close('all') plt.figure(1) fig, ax = plt.subplots() ax.pcolor(x_, cmap=plt.cm.Greens, edgecolors='k') ax.set_xticks(np.arange(0, x_.shape[1])+0.5) # 设置横纵坐标 ax.set_yticks(np.arange(0, x_.shape[0])+0.5) ax.xaxis.tick_top() # x轴提示显示在图形上方 ax.yaxis.tick_left() # y轴提示显示在图形的左侧 ax.set_xticklabels(col_names, minor=False, fontsize=10) # 传递标签数据 ax.set_yticklabels(y_labels, minor=False, fontsize=10) plt.show()
Wie sieht das gezeichnete Bild aus:
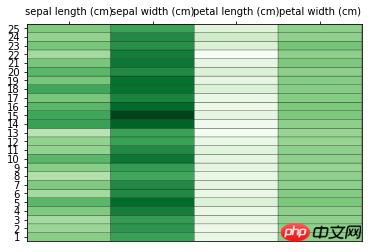 Nur ein paar einfache Schritte oben Ein intuitives Bild wird natürlich nicht so einfach sein, wenn es tatsächlich verwendet wird, und es muss mehr Wissen erweitert werden.
Nur ein paar einfache Schritte oben Ein intuitives Bild wird natürlich nicht so einfach sein, wenn es tatsächlich verwendet wird, und es muss mehr Wissen erweitert werden.
Das obige ist der detaillierte Inhalt vonEine kurze Einführung in die Vorverarbeitung und Heatmaps in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



