


本篇文章给大家带来的内容是关于NotePad++正则表达式如何进行替换(图文),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
NotePad++ 正则表达式替换 高级用法
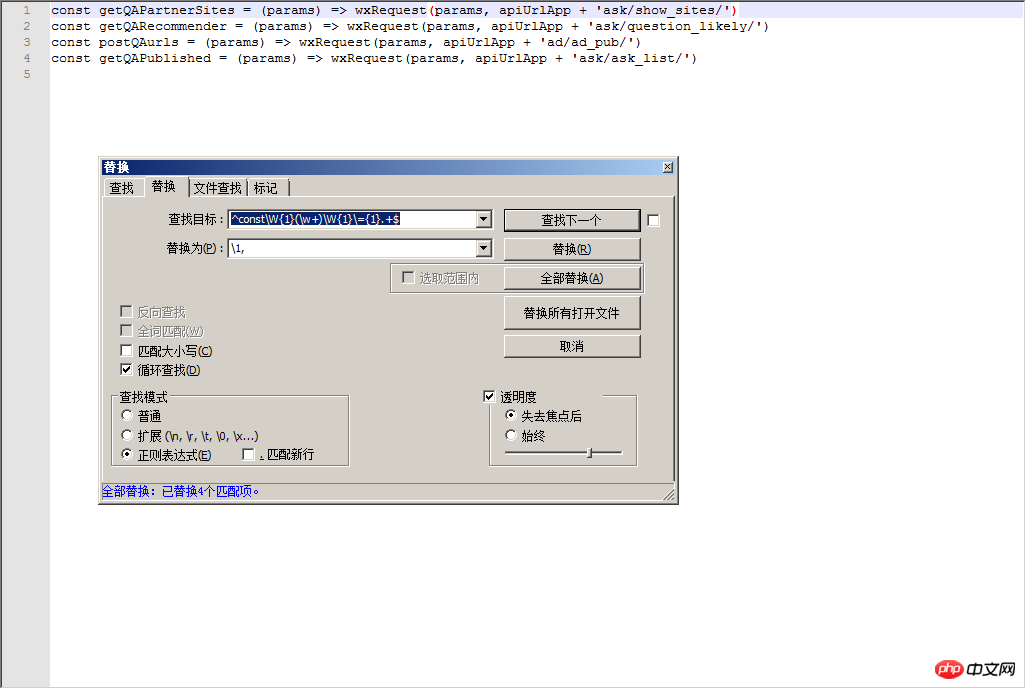
const getQAPartnerSites = (params) => wxRequest(params, apiUrlApp + 'ask/show_sites/') const getQARecommender = (params) => wxRequest(params, apiUrlApp + 'ask/question_likely/') const postQAurls = (params) => wxRequest(params, apiUrlApp + 'ad/ad_pub/') const getQAPublished = (params) => wxRequest(params, apiUrlApp + 'ask/ask_list/')
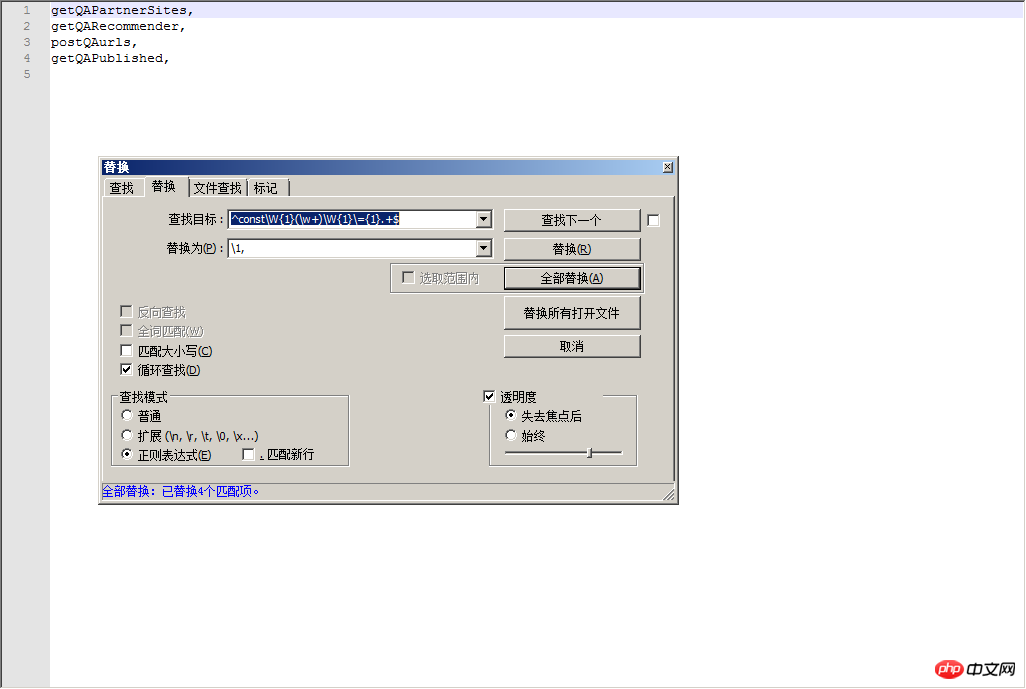
^const\W{1}(\w+)\W{1}\={1}.+$
\1,getQAPartnerSites, getQARecommender, postQAurls, getQAPublished,
在我们处理文件时,很多时候会用到查找与替换。当我们想将文件中某一部分替换替换文件中另一部分时,怎么办呢? 下面正则表达式 给我提供方法。
正则表达式,提供复杂 并且弹性的查找与替换
注意: 不支持多行表达式 (involving \n, \r, etc).
| 符号 | 解释 |
|---|---|
| . | 匹配任意字符,除了新一行(\n)。也就是说 “.”可以匹配 \r ,当文件中同时含有\r and \n时,会引起混乱。要匹配所有的字符,使用\s\S。 |
| (…) | 这个匹配一个标签区域. 这个标签可以被访问,通过语法 \1访问第一个标签, \2 访问第二个, 同理 \3 \4 … \9。 这些标签可以用在当前正则表达式中,或则替search和replace中的换字符串。 |
| \1, \2, etc | 在替换中代表1到9的标签区域(\1 to \9)。例如, 查找字符串 Fred([1-9])XXX 并替换为字符串 Sam\1YYY的方法,当在文件中找到Fred2XXX的字符串时,会替换为Sam2YYY。注意: 只有9个区域能使用,所以我们在使用时很安全,像\10\2 表示区域1和文本”0”以及区域2。 |
| […] | 表示一个字符集合, 例如 [abc]表示任意字符 a, b or c.我们也可以使用范围例如[a-z] 表示所以的小写字母。 |
| [^…] | 表示字符补集. 例如, [^A-Za-z] 表示任意字符除了字母表。 |
| ^ | 匹配一行的开始(除非在集合中, 如下). |
| $ | 匹配行尾. |
| * | 匹配0或多次, 例如 Sa*m 匹配 Sm, Sam, Saam, Saaam 等等. |
| + | 匹配1次或多次,例如 Sa+m 匹配 Sam, Saam, Saaam 等等. |
| ? | 匹配0或者1次, 例如 Sa?m 匹配 Sm, Sam. |
| {n} | 匹配确定的 n 次.例如, ‘Sa{2}m’ 匹配 Saam. |
| {m,n} | 匹配至少m次,至多n次(如果n缺失,则任意次数).例如, ‘Sa{2,3}m’ 匹配 Saam or Saaam. ‘Sa{2,}m’ 与 ‘Saa+m’相同 |
| *?, +?, ??, {n,m}? | 非贪心匹配,匹配第一个有效的匹配,通常 ‘<.>’ 会匹配整个 ‘content’字符串 –但 ‘<.?>’ 只匹配 ” .这个标记一个标签区域,这些区域可以用语法\1 \2 等访问多个对应1-9区域。 |
| 符号 | 解释 |
|---|---|
| (…) | 一组捕获. 可以通过\1 访问第一个组, \2 访问第二个. |
| (?:…) | 非捕获组. |
| (?=…) | 非捕获组 – 向前断言. 例如’(.*)(?=ton)’ 表达式,当 遇到’Appleton’字符串时,会匹配为’Apple’. |
| (?<=…) | 非捕获组 – 向后断言. 例如’(?<=sir) (.*)’ 表示式,当遇到’sir William’ 字符串时,匹配为’ William’. |
| (?!…) | 非捕获组 – 消极的向前断言. 例如’.(?!e)’ 表达式,当遇到’Apple’时,会找到每个字母除了 ‘l’,因为它紧跟着 ‘e’. |
| (? | 非捕获组 – 消极向后断言. 例如 ‘(? |
| (?P…) | 命名所捕获的组. 提交一个名称到组中供后续使用,例如’(?PA[^\s]+)\s(?P=first)’ 会找到 ‘Apple Apple’. 类似的 ‘(A[^\s]+)\s\1’ 使用组名而不是数字. |
| (?=name) | 匹配名为name的组. (?P…). |
| (?#comment) | 批注 –括号中的内容在匹配时将被忽略。 |
| 符号 | 解释 |
|---|---|
| s | 匹配空格. 注意,会匹配标记的末尾. 使用 [[:blank:]] 来避免匹配新一行。 |
| S | 匹配非空白 |
| w | 匹配单词字符 |
| W | 匹配非单词字符 |
| d | 匹配数字字符 |
| D | 匹配非数字字符 |
| b | 匹配单词边界. ‘bWw+’ 找到W开头的单词 |
| B | 匹配非单词边界. ‘BeB+’ – 找到位于单子中间的字母’e’ |
| < | This matches the start of a word using Scintilla’s definitions of words. |
| > | This matches the end of a word using Scintilla’s definition of words. |
| x | 运行用x来表达可能具有其他意思的字符。例如, [ 用来插入到文本中作为[ 而不是作为字符集的开始. |
| 符号 | 解释 |
|---|---|
| [[:alpha:]] | 匹配字母字符: [A-Za-z] |
| [[:digit:]] | 匹配数字字符: [0-9] |
| [[:xdigit:]] | 匹配16进制字符: [0-9A-Fa-f] |
| [[:alnum:]] | 匹配字母数字字符: [0-9A-Za-z] |
| [[:lower:]] | 匹配小写字符: [a-z] |
| [[:upper:]] | 匹配大写字符: [A-Z] |
| [[:blank:]] | 匹配空白 (空格 or tab):[ t] |
| [[:space:]] | 匹配空白字符:[ trnvf] |
| [[:punct:]] | 匹配标点字符: [-!”#$%&’()*+,./:;<=>?@[]_`{ |
| [[:graph:]] | 匹配图形字符: [x21-x7E] |
| [[:print:]] | 匹配可打印的字符 (graphical characters and spaces) |
| [[:cntrl:]] | 匹配控制字符 |
Verwenden Sie reguläre Ausdrucks-Tags, um die gewünschten Zeichen zu umgeben, und ersetzen Sie sie dann Zeichenfolge mit 1, dem ersten passenden Text.
Zum Beispiel:
| Text body | Search string | Replace string | Result |
|---|---|---|---|
| Hi my name is Fred | my name is (.+) | my name is not 1 | Hi my name is not Fred |
| The quick brown fox jumped over the fat lazy dog | brown (.+) jumped over the (.+) | brown 2 jumped over the 1 | The quick brown fat jumped over the fox lazy dog |
Die Unterstützung für reguläre Ausdrücke in PN2 ist derzeit begrenzt, die unterstützten Muster und Syntax sind eine sehr kleine Teilmenge der leistungsstarken Ausdrücke Unterstützt von Perl. Die größte Einschränkung besteht darin, dass reguläre Ausdrücke nur mit einer einzelnen Zeile übereinstimmen und nicht im Mehrzeilen-Matching ausgedrückt werden können. Stattdessen können Backslash-Ausdrücke verwendet werden.
Der Plan besteht darin, die PCRE-Bibliothek (die an anderer Stelle in PN2 verwendet wird) zur Unterstützung der Dokumentsuche zu verwenden.
Das obige ist der detaillierte Inhalt vonSo ersetzen Sie reguläre Ausdrücke in NotePad++ (Bild und Text). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



