


Dieser Artikel stellt hauptsächlich das Python-Verifizierungscode-Erkennungs-Tutorial unter Verwendung der Projektionsmethode und der verbundenen Domänenmethode zum Segmentieren von Bildern vor. Jetzt kann ich es mit Ihnen teilen.
Vorwort
Der heutige Artikel befasst sich hauptsächlich mit der Aufteilung des Bestätigungscodes. Die wichtigsten verwendeten Bibliotheken sind Pillow und das Bildverarbeitungstool GIMP unter Linux. Nehmen Sie zunächst ein Beispiel mit fester Position und Breite, ohne Haftung und ohne Interferenzen an, um zu erfahren, wie Sie mit Pillow Bilder ausschneiden.
Nachdem Sie das Bild mit GIMP geöffnet haben, drücken Sie das Pluszeichen, um das Bild zu vergrößern, und klicken Sie dann auf „Ansicht->Raster anzeigen“, um die Rasterlinien anzuzeigen:
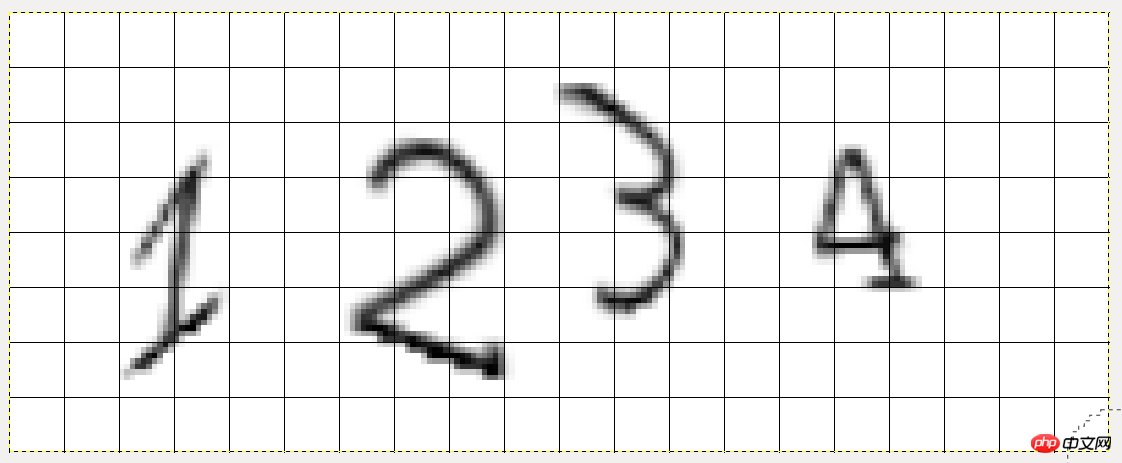
Unter diesen beträgt die Seitenlänge jedes Quadrats 10 Pixel, sodass die Schnittkoordinaten von Nummer 1 20 links, 20 oben, 40 rechts und 70 unten sind. Analog können Sie die Schnittpositionen der verbleibenden 3 Zahlen kennen.
Der Code lautet wie folgt:
from PIL import Image
p = Image.open("1.png")
# 注意位置顺序为左、上、右、下
cuts = [(20,20,40,70),(60,20,90,70),(100,10,130,60),(140,20,170,50)]
for i,n in enumerate(cuts,1):
temp = p.crop(n) # 调用crop函数进行切割
temp.save("cut%s.png" % i)Nach dem Schneiden erhält man 4 Bilder:

Was passiert also, wenn die Zeichenposition nicht festgelegt ist? Nehmen wir nun einen Fall mit zufälliger Positionsbreite, ohne Adhäsion und ohne störende Linien an.
Die erste und einfachste Methode heißt „Projektionsmethode“. Das Prinzip besteht darin, das binarisierte Bild in vertikaler Richtung zu projizieren und nach der Projektion die Segmentierungsgrenze basierend auf den Extremwerten zu bestimmen. Hier verwende ich zur Demonstration noch das Verifizierungscode-Bild oben:
def vertical(img): """传入二值化后的图片进行垂直投影""" pixdata = img.load() w,h = img.size ver_list = [] # 开始投影 for x in range(w): black = 0 for y in range(h): if pixdata[x,y] == 0: black += 1 ver_list.append(black) # 判断边界 l,r = 0,0 flag = False cuts = [] for i,count in enumerate(ver_list): # 阈值这里为0 if flag is False and count > 0: l = i flag = True if flag and count == 0: r = i-1 flag = False cuts.append((l,r)) return cuts p = Image.open('1.png') b_img = binarizing(p,200) v = vertical(b_img)
Durch die vertikale Funktion erhalten wir nach der Projektion auf die X-Achse ein Diagramm, das alle schwarzen Pixel enthält Die Position des linken und rechten Rands. Da das Captcha nichts stört, ist mein Schwellenwert auf 0 gesetzt. Bezüglich der Binarisierungsfunktion können Sie auf den vorherigen Artikel verweisen
Die Ausgabe ist wie folgt:
[(21, 37), (62, 89), (100, 122), (146, 164)]
Wie Sie sehen können Die Projektionsmethode gibt die linken und rechten Grenzen an. Sie kommt dem sehr nahe, was wir durch manuelle Inspektion erhalten können. Wenn Sie faul sind, können Sie für die oberen und unteren Grenzen direkt 0 und die Höhe des Bildes verwenden oder es in horizontaler Richtung projizieren. Freunde, die hier interessiert sind, können es selbst versuchen.
Wenn es jedoch zu einer Haftung zwischen Zeichen kommt, führt die Projektionsmethode zu Aufteilungsfehlern, wie im vorherigen Artikel:

Nachdem der Schwellenwert auf 5 geändert wurde, lauten die durch die Projektionsmethode angegebenen linken und rechten Grenzen:
[(5, 27), (33, 53), (59, 108)]
Offensichtlich sind es die letzten 6 und 9 Zahlen nicht geschnitten.
Ändern Sie den Schwellenwert auf 7, und das Ergebnis ist:
[(5, 27), (33, 53), (60, 79), (83, 108)]
Bei einfachen Adhäsionssituationen kann es also auch möglich sein, den Schwellenwert anzupassen gelöst werden.
Die zweite Methode wird als CFS-Verbindungsdomänensegmentierungsmethode bezeichnet. Das Prinzip besteht darin, davon auszugehen, dass jedes Zeichen aus einer separaten verbundenen Domäne besteht, mit anderen Worten, es gibt keine Adhäsion. Suchen Sie ein schwarzes Pixel und beginnen Sie mit der Beurteilung, bis alle verbundenen schwarzen Pixel durchlaufen und markiert wurden, um die Segmentierungsposition des Zeichens zu bestimmen . Der Algorithmus lautet wie folgt:
Durchlaufen Sie das binarisierte Bild von links nach rechts und von oben nach unten. Wenn ein schwarzes Pixel gefunden wird und dieses Pixel zuvor noch nicht besucht wurde, drücken Sie dieses Pixel auf den Stapel und markieren Sie es als besucht.
Wenn der Stapel nicht leer ist, fahren Sie mit der Erkennung der umgebenden 8 Pixel fort und führen Sie Schritt 2 aus. Wenn der Stapel leer ist, bedeutet dies, dass ein Zeichenblock erkannt wurde.
Die Erkennung wird beendet und somit die Anzahl der Zeichen ermittelt.
Der Code lautet wie folgt:
import queue
def cfs(img):
"""传入二值化后的图片进行连通域分割"""
pixdata = img.load()
w,h = img.size
visited = set()
q = queue.Queue()
offset = [(-1,-1),(0,-1),(1,-1),(-1,0),(1,0),(-1,1),(0,1),(1,1)]
cuts = []
for x in range(w):
for y in range(h):
x_axis = []
#y_axis = []
if pixdata[x,y] == 0 and (x,y) not in visited:
q.put((x,y))
visited.add((x,y))
while not q.empty():
x_p,y_p = q.get()
for x_offset,y_offset in offset:
x_c,y_c = x_p+x_offset,y_p+y_offset
if (x_c,y_c) in visited:
continue
visited.add((x_c,y_c))
try:
if pixdata[x_c,y_c] == 0:
q.put((x_c,y_c))
x_axis.append(x_c)
#y_axis.append(y_c)
except:
pass
if x_axis:
min_x,max_x = min(x_axis),max(x_axis)
if max_x - min_x > 3:
# 宽度小于3的认为是噪点,根据需要修改
cuts.append((min_x,max_x))
return cutsDas Ausgabeergebnis nach dem Aufruf ist das gleiche wie bei Verwendung der Projektionsmethode . Außerdem habe ich gesehen, dass es im Internet eine Methode namens „Flood Fill“ gibt, die mit verbundenen Domänen identisch zu sein scheint.
Verwandte Empfehlungen:
Das obige ist der detaillierte Inhalt vonTutorial zur Erkennung von Python-Verifizierungscodes: Segmentieren von Bildern mithilfe der Projektionsmethode und der Methode der verbundenen Domäne. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



