

Dieses Mal werde ich Ihnen eine detaillierte Erklärung der Schritte zur Implementierung der Huffman-Codierung/Decodierung in PHP geben. Was sind die Vorsichtsmaßnahmen für die Implementierung der Huffman-Codierung/Decodierung in PHP? ein Blick.
In diesem Artikel wird PHP zum Üben der Huffman-Kodierung und -Dekodierung verwendet.
1. Kodierung
Wortzählung
Der erste Schritt der Huffman-Kodierung besteht darin, das Vorkommen jedes Zeichens zu zählen In den Dokumentzeiten kann die integrierte Funktion count_chars() von PHP Folgendes tun:
$input = file_get_contents('input.txt'); $stat = count_chars($input, 1);
Huffman-Baum erstellen
Weiter , Konstruieren Sie den Huffman-Baum basierend auf den statistischen Ergebnissen. Die Konstruktionsmethode ist in Wikipedia ausführlich beschrieben. Hier ist eine einfache, in PHP geschriebene Version:
$huffmanTree = [];
foreach ($stat as $char => $count) {
$huffmanTree[] = [
'k' => chr($char),
'v' => $count,
'left' => null,
'right' => null,
];
}
// 构造树的层级关系,思想见wiki:https://zh.wikipedia.org/wiki/%E9%9C%8D%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81
$size = count($huffmanTree);
for ($i = 0; $i !== $size - 1; $i++) {
uasort($huffmanTree, function ($a, $b) {
if ($a['v'] === $b['v']) {
return 0;
}
return $a['v'] < $b['v'] ? -1 : 1;
});
$a = array_shift($huffmanTree);
$b = array_shift($huffmanTree);
$huffmanTree[] = [
'v' => $a['v'] + $b['v'],
'left' => $b,
'right' => $a,
];
}
$root = current($huffmanTree);Nach der Berechnung zeigt $root auf den Wurzelknoten des Huffman-Baums
Generieren Sie ein Codierungswörterbuch basierend auf dem Huffman-Baum
Mit dem Huffman-Baum können Sie ein Wörterbuch zum Kodieren generieren:
function buildDict($elem, $code = '', &$dict) {
if (isset($elem['k'])) {
$dict[$elem['k']] = $code;
} else {
buildDict($elem['left'], $code.'0', $dict);
buildDict($elem['right'], $code.'1', $dict);
}
}
$dict = [];
buildDict($root, '', $dict);Datei schreiben
Verwenden Sie das Wörterbuch, um den Dateiinhalt zu kodieren und schreiben Sie Importieren Sie die Datei. Beim Schreiben der Huffman-Codierung in eine Datei sind mehrere Dinge zu beachten:
Nachdem das Codierungswörterbuch und der Codierungsinhalt zusammen in die Datei geschrieben wurden, ist es unmöglich, ihre Grenzen zu unterscheiden, daher müssen sie geschrieben werden der Anfang der Datei. Anzahl der belegten Bytes
Die von PHP bereitgestellte Funktion fwrite() kann jeweils 8 Bit (ein Byte) oder ein ganzzahliges Vielfaches von 8 Bit schreiben. Bei der Huffman-Codierung kann ein Zeichen jedoch nur durch 1 Bit dargestellt werden, und PHP unterstützt nicht den Vorgang, bei dem nur 1 Bit in die Datei geschrieben wird. Daher müssen wir die Codierung selbst zusammenfügen und die Datei erst schreiben, nachdem alle 8 Bit erhalten wurden.
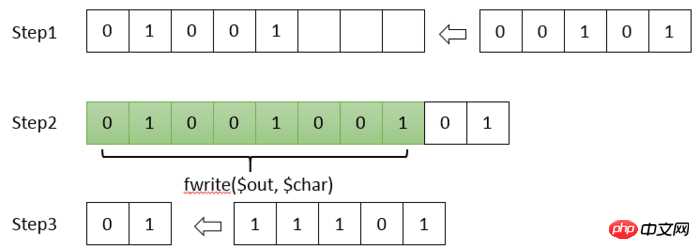
Alle 8-Bit-Daten schreiben
Ähnlich wie beim zweiten Element muss die endgültige Dateigröße ein ganzzahliges Vielfaches von 8-Bit sein. Wenn also die Größe der gesamten Kodierung 8001 Bit beträgt, müssen am Ende 7 Nullen hinzugefügt werden Rufen Sie das Codierungswörterbuch ab und dekodieren Sie dann die Originalzeichen gemäß dem Wörterbuch.
Während des Dekodierungsprozesses gibt es ein Problem, das beachtet werden muss: Da wir während des Kodierungsprozesses mehrere 0-Bits am Ende der Datei hinzugefügt haben, sollten diese 0-Bits zufällig die Kodierung sein ein bestimmtes Zeichen im Wörterbuch. Dies führt zu einer falschen Dekodierung. Wenn also während des Dekodierungsvorgangs die Anzahl der dekodierten Zeichen die Dokumentlänge erreicht, wird die Dekodierung gestoppt.
$dictString = serialize($dict);
// 写入字典和编码各自占用的字节数
$header = pack('VV', strlen($dictString), strlen($input));
fwrite($outFile, $header);
// 写入字典本身
fwrite($outFile, $dictString);
// 写入编码的内容
$buffer = '';
$i = 0;
while (isset($input[$i])) {
$buffer .= $dict[$input[$i]];
while (isset($buffer[7])) {
$char = bindec(substr($buffer, 0, 8));
fwrite($outFile, chr($char));
$buffer = substr($buffer, 8);
}
$i++;
}
// 末尾的内容如果没有凑齐 8-bit,需要自行补齐
if (!empty($buffer)) {
$char = bindec(str_pad($buffer, 8, '0'));
fwrite($outFile, chr($char));
}
fclose($outFile);Wir haben den HTML-Code der Huffman-Coding-Wiki-Seite lokal gespeichert und den Huffman-Coding-Test durchgeführt:
Vor der Kodierung: 418.504 Bytes
Nach der Kodierung: 280.127 BytesDer Platz wird um 33 % gespart Die Huffman-Kodierung kann 50 % darüber erreichen.Zusätzlich zum Textinhalt versuchen wir, eine Binärdatei, wie zum Beispiel das f.lux-Installationsprogramm, mit Huffman zu kodieren. Die Testergebnisse sind wie folgt:Vor der Kodierung: 770.384 Bytes Nach der Kodierung: 773.076 Bytes
Nach der Kodierung nimmt es zum einen mehr Platz ein, weil wir keinen zusätzlichen Speicherplatz benötigen Die Verarbeitung beim Speichern des Wörterbuchs nimmt viel Platz ein. Andererseits ist in Binärdateien die Wahrscheinlichkeit, dass jedes Zeichen auftritt, relativ gleichmäßig und die Vorteile der Huffman-Codierung können nicht genutzt werden. Ich glaube, dass Sie die Methode beherrschen, nachdem Sie den Fall in diesem Artikel gelesen haben. Weitere spannende Informationen finden Sie in anderen verwandten Artikeln auf der chinesischen PHP-Website! Empfohlene Lektüre:Detaillierte Erläuterung der Schritte zur Verwendung des PHP-Schnellsortierungsalgorithmus
Detaillierte Erläuterung des Iterators Von PHP basierend auf SPL implementierte Schritte
Das obige ist der detaillierte Inhalt vonDetaillierte Erklärung der Huffman-Kodierungs-/Dekodierungsschritte in PHP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie eine PHP-Datei
So öffnen Sie eine PHP-Datei
 So entfernen Sie die ersten paar Elemente eines Arrays in PHP
So entfernen Sie die ersten paar Elemente eines Arrays in PHP
 Was tun, wenn die PHP-Deserialisierung fehlschlägt?
Was tun, wenn die PHP-Deserialisierung fehlschlägt?
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So laden Sie HTML hoch
So laden Sie HTML hoch
 So lösen Sie verstümmelte Zeichen in PHP
So lösen Sie verstümmelte Zeichen in PHP
 So öffnen Sie PHP-Dateien auf einem Mobiltelefon
So öffnen Sie PHP-Dateien auf einem Mobiltelefon












