


Dieser Artikel stellt hauptsächlich die detaillierte Erklärung des PyTorch-Batch-Trainings und des PyTorch-Optimierers vor. Es ist von großem praktischem Wert.
1. PyTorch-Batch-Training
1. Übersicht
PyTorch bietet eine Möglichkeit, Daten für Batch zu packen Schulung Schulungstool - DataLoader. Wenn wir es verwenden, müssen wir unsere Daten zunächst nur in die Tensorform von Torch umwandeln, sie dann in ein Datensatzformat konvertieren, das Torch erkennen kann, und dann den Datensatz in den DataLoader einfügen.
import torch
import torch.utils.data as Data
torch.manual_seed(1) # 设定随机数种子
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(0.5, 5, 10)
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE, # 批大小
# 若dataset中的样本数不能被batch_size整除的话,最后剩余多少就使用多少
shuffle=True, # 是否随机打乱顺序
num_workers=2, # 多线程读取数据的线程数
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch:', epoch, '|Step:', step, '|batch_x:',
batch_x.numpy(), '|batch_y', batch_y.numpy())
'''''
shuffle=True
Epoch: 0 |Step: 0 |batch_x: [ 6. 7. 2. 3. 1.] |batch_y [ 3. 3.5 1. 1.5 0.5]
Epoch: 0 |Step: 1 |batch_x: [ 9. 10. 4. 8. 5.] |batch_y [ 4.5 5. 2. 4. 2.5]
Epoch: 1 |Step: 0 |batch_x: [ 3. 4. 2. 9. 10.] |batch_y [ 1.5 2. 1. 4.5 5. ]
Epoch: 1 |Step: 1 |batch_x: [ 1. 7. 8. 5. 6.] |batch_y [ 0.5 3.5 4. 2.5 3. ]
Epoch: 2 |Step: 0 |batch_x: [ 3. 9. 2. 6. 7.] |batch_y [ 1.5 4.5 1. 3. 3.5]
Epoch: 2 |Step: 1 |batch_x: [ 10. 4. 8. 1. 5.] |batch_y [ 5. 2. 4. 0.5 2.5]
shuffle=False
Epoch: 0 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 0 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 1 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 1 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 2 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 2 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
'''2. TensorDataset
classtorch.utils.data.TensorDataset(data_tensor, target_tensor)
TensorDataset-Klasse To Packen Sie die Proben und ihre Beschriftungen in einen Torch-Datensatz. data_tensor und target_tensor sind beide Tensoren.
3. DataLoader
Code kopieren Der Code lautet wie folgt:
classtorch.utils .data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,num_workers=0, collate_fn=
dataset is Das Dataset-Format-Objekt von Torch ist die Anzahl der Stichproben für jeden Trainingsstapel. Die Standardeinstellung ist, dass num_workers die Anzahl der Threads zum Lesen von Stichproben angibt.
2. PyTorchs Optimierer
Erstellen Sie in diesem Experiment zunächst einen Satz Datensätze, konvertieren Sie das Format und platzieren Sie ihn im DataLoader. Ersatzteil. Definieren Sie ein standardmäßiges neuronales Netzwerk mit einer festen Struktur und erstellen Sie dann ein neuronales Netzwerk für jeden Optimierer. Der Unterschied zwischen den einzelnen neuronalen Netzwerken besteht nur im Optimierer. Durch die Aufzeichnung des Verlustwerts während des Trainingsprozesses wird der Optimierungsprozess jedes Optimierers schließlich im Bild dargestellt.
Code-Implementierung:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 定义超参数
LR = 0.01 # 学习率
BATCH_SIZE = 32 # 批大小
EPOCH = 12 # 迭代次数
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
#plt.scatter(x.numpy(), y.numpy())
#plt.show()
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
# 为每个优化器创建一个Net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# 初始化优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
# 定义损失函数
loss_function = torch.nn.MSELoss()
losses_history = [[], [], [], []] # 记录training时不同神经网络的loss值
for epoch in range(EPOCH):
print('Epoch:', epoch + 1, 'Training...')
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_history):
output = net(b_x)
loss = loss_function(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data[0])
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_history):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()Experimentelle Ergebnisse:
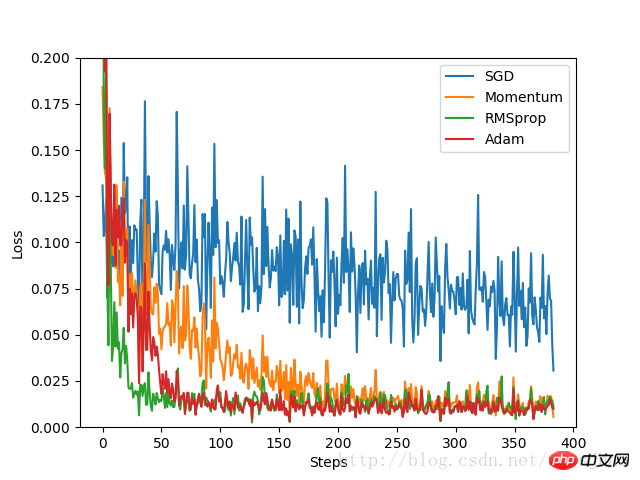
Wie zu sehen ist Den experimentellen Ergebnissen zufolge ist der Optimierungseffekt von SGD am schlechtesten und die Geschwindigkeit ist sehr langsam. Als verbesserte Version von SGD ist die Leistung von Momentum im Vergleich zu RMSprop und Adam sehr gut. Im Experiment wurden für verschiedene Optimierungsprobleme die Auswirkungen verschiedener Optimierer verglichen, bevor entschieden wurde, welcher verwendet werden sollte.
3. Andere Ergänzungen
1. Die Zip-Funktion von Python
Zip-Funktion akzeptiert alle Multiples (einschließlich 0 und 1) Sequenzen werden als Parameter verwendet und eine Tupelliste zurückgegeben.
x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] xyz = zip(x, y, z) print xyz [(1, 4, 7), (2, 5, 8), (3, 6, 9)] x = [1, 2, 3] x = zip(x) print x [(1,), (2,), (3,)] x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print xy [(1, 4), (2, 5), (3, 6)]
Verwandte Empfehlungen:
Mnist-Klassifizierungsbeispiel für den Einstieg in Pytorch
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des PyTorch-Batch-Trainings und des Optimierervergleichs. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist Optimierung?
Was ist Optimierung?
 Keyword-Optimierungssoftware von Baidu
Keyword-Optimierungssoftware von Baidu
 Baidu SEO-Methode zur Optimierung des Keyword-Rankings
Baidu SEO-Methode zur Optimierung des Keyword-Rankings
 So verwenden Sie die Shift-Hintertür
So verwenden Sie die Shift-Hintertür
 psrpc.dll keine Lösung gefunden
psrpc.dll keine Lösung gefunden
 So löschen Sie Array-Elemente in JavaScript
So löschen Sie Array-Elemente in JavaScript
 Checken Sie den virtuellen Standort auf DingTalk ein
Checken Sie den virtuellen Standort auf DingTalk ein
 Der Geschwindigkeitsunterschied zwischen USB2.0 und 3.0
Der Geschwindigkeitsunterschied zwischen USB2.0 und 3.0








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



