


Dieser Artikel stellt hauptsächlich die automatische Reservierungsfunktion des Bibliothekslernraums in Python vor. Er hat einen gewissen Referenzwert.
Dieser Artikel teilt die Python-Implementierung mit allen Die automatische Reservierung des Lernraums der Bibliothek dient als Referenz. Der spezifische Inhalt lautet wie folgt:
Einführung
Viele Schulen bieten den Schülern mittlerweile eine sehr gute Lernumgebung. Dies spiegelt sich in der Regel in der Ausstattung und Ausstattung der Selbstlern-Klassenzimmer wider. Was ich dazu erwähnen muss, ist die Bibliothek unserer Schule. Mit dem Bau der neuen Bibliothek wurden in der Bibliothek mehrere Funktionsbereiche eingerichtet. Jede Etage ist in vier Bereiche unterteilt: A, B, C und D Im Norden und Süden sind die Flure miteinander verbunden und eine Wendeltreppe führt durch die erste bis fünfte Etage. Bereich A ist ein Selbstlernbereich; Bereiche B und C sind sozialwissenschaftliche und naturwissenschaftliche Bibliotheken, die Sammlung und Lesen integrieren; Bereich D ist ein spezieller Funktionsbereich, einschließlich Film- und Fernsehsaal, Erlebniszentrum für digitale Medien, Smart-Training-Klassenzimmer und Cloud-Desktop-Lesesaal usw.; in den Ost-West-Korridoren der Bereiche B und C gibt es zwölf große und kleine Lernräume; in den Nord-Süd-Korridoren gibt es Freizeitlesebereiche.
Ich habe den obigen Absatz von der offiziellen Website der Bibliothek kopiert, aber ich muss der Schulbibliothek wirklich einen Daumen hoch geben. Um auf das Thema dieses Artikels zurückzukommen: Die Schule stellt Lehrern und Schülern kostenlos komfortable, hochwertige und gut ausgestattete Lernräume zur Verfügung. Diese Lernräume erfordern jedoch eine Online-Reservierung, bevor sie genutzt werden können. Reservierungen für den nächsten Tag beginnen jeden Tag um 00:00 Uhr. Wenn Sie also innerhalb eines bestimmten Zeitraums (3 Stunden) einen Termin für einen Lernraum vereinbaren möchten um „das Mitternachtsöl zu verbrennen“. Natürlich sind schnelle Hände bei diesem Prozess von großem Vorteil. Wenn Sie früh abends zu Bett gehen und Ihre Handgeschwindigkeit nicht schnell ist, können Sie grundsätzlich keinen Termin im Lernzimmer vereinbaren. Ich habe kürzlich zufällig einen kleinen Python-Crawler gelernt und möchte diesen Crawler verwenden, um diese mühsame Aufgabe zu erledigen. Ha ha ha ha! (ps: Um böswilligen Zugriff zu verhindern, werden nicht alle Links veröffentlicht)
Python-Implementierungsideen
Die Idee ist ganz einfach, wenn man darüber nachdenkt. Es ist nichts Mehr als sich bei Ihrem Konto anzumelden und nach einem Zimmer zu suchen, reichen Sie die Reservierung ein. Dann probieren wir es aus:
Konto anmelden
Öffnen Sie zunächst die Login-Schnittstelle für unsere Lernraumreservierung, der Link lautet: U2FsdGVkX19NdfJkghN54Msvy1zl7AucRur/ct0nz4orPI7uLkSDsvuFMgr0fGcO
rn9Z/f8h3bds9w==
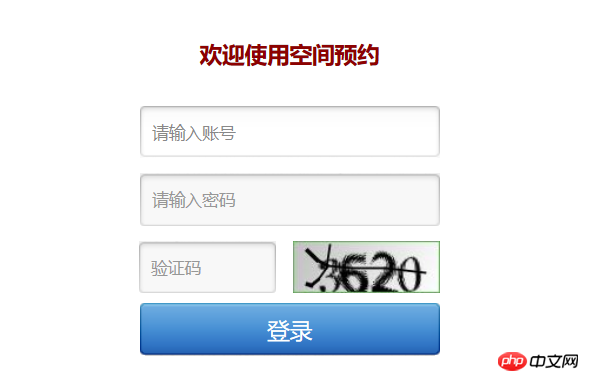
Okay, dieser erste Schritt der Anmeldung bei Ihrem Konto ist für mich als Neuling ein Test, aber ich darf nicht schüchtern sein. Unter Bezugnahme auf die von einigen anderen großen Jungs verwendete Methode besteht es darin, den Firebug von Firefox zu öffnen (Strg + Umschalt + E), um die Netzwerksituation zu überprüfen, und in diesem Fall eine normale Anmeldung durchzuführen.

Sie können sehen, dass wir hier einen Beitrag haben, und dann können Sie die Methode „requests.post“ in Python verwenden.
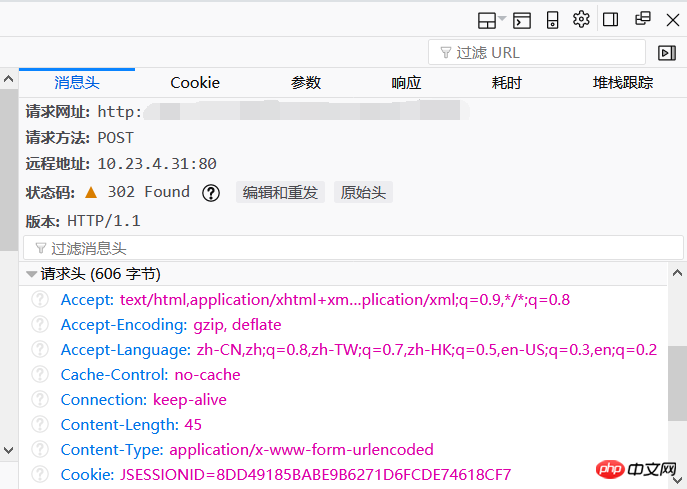
Um sich erfolgreich anzumelden, müssen Sie Ihre Identität als Crawler verbergen. Im Nachrichtenheader können Sie einfach alle Parameter kopieren form Own headers = {…} um den Server auszutricksen.
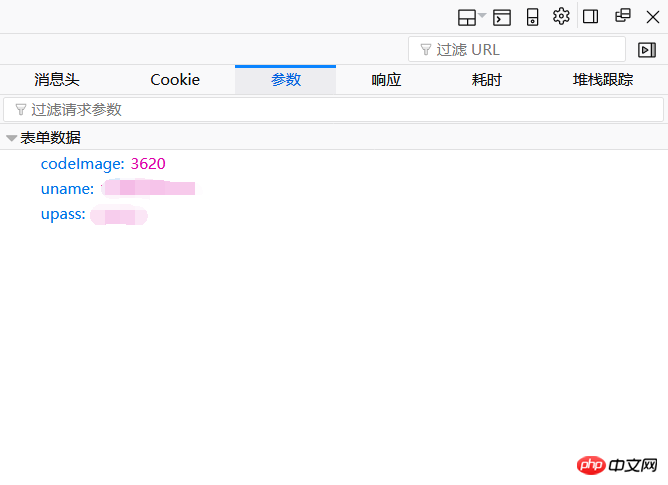
Schauen Sie sich die Parameterseite an. Hier gibt es nur drei Formulardaten, die dem Bestätigungscode, der Kontonummer und dem Passwort entsprechen. Kopieren Sie die Parameter hier, um unsere Daten zu bilden = {…}. Was unsere Aufmerksamkeit erfordert, ist dieser Bestätigungscode. Unabhängig davon, ob er manuell oder automatisch von einer Maschine erkannt werden kann, muss der Bestätigungscode als lokale Datei gespeichert werden. Daher liegt bei jedem Zugriff auf den Server ein Problem vor. Lassen Sie uns nun sorgfältig darüber nachdenken. Zuerst müssen wir den Bestätigungscode abrufen und ihn lokal speichern. Dazu müssen wir unsere Parameter eingeben, um uns anzumelden. Dieses Mal besuchen wir den Server die Verifizierung Der Verifizierungscode und der von uns erhaltene Verifizierungscode sind nicht mehr derselbe Verifizierungscode. Im ersten Versuch konnte ich mich trotzdem nicht am Server anmelden, da die beiden Verifizierungscodes nicht übereinstimmten. Wie kann der zum ersten Mal erhaltene Bestätigungscode mit dem Bestätigungscode bei der Übermittlung in Einklang gebracht werden?
Hier wird das gleiche Cookie benötigt. Auf den mehreren Bildern oben können wir alle sehen, dass es einen Cookie-Wert gibt. Um die Synchronisierung sicherzustellen, müssen wir sicherstellen, dass der Cookie-Wert beim Erhalten des Bestätigungscodes mit dem Cookie-Wert bei der Übermittlung des Kontokennworts übereinstimmt. Daher besteht der erste Schritt in meinem Programm darin, einen Cookie-Wert abzurufen und diesen Cookie-Wert dann als Parameter in den Headern zu verwenden. Dies ist die Idee des Anmeldens. Ich möchte hinzufügen, dass ich den Bestätigungscode hier manuell identifiziert habe >﹏<.
Suchen Sie ein Zimmer
这个步骤其实是一个无用的步骤,为什么有这个步骤,按照人为预约习惯,我们会产生怎么一个步骤,但是如果使用爬虫,只要成功登录之后就可以直接提交预约的表单。当然,如果要使得自动预约程序更加智能,便可以添加这个步骤,可以查看那些房间是还可以预约的,在这里自定义的补充一些规则。我就略过了。。。
提交预约
同登录一样,我们也手动的提交一次,去查看网络情况,便可以用python模拟这一个过程。在这里我就不在贴图进行解释,这里提交也是用requests.post的方法。不过一点要注意的是,这里的headers和登录时的headers是不一样的,所以在此提醒各位,如果在其他类似的预约程序中可以注意看看不同内容post时的headers是否一致。我在这里就被坑了一会。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : 2018/4/10
# @Author : 圈圈烃
# @File : reservation_4.py
import requests
import re
import json
import datetime
import time
def get_cookies():
"""获得cookies"""
url = 'http://**************'
s = requests.session()
s.get(url)
ck_dict = requests.utils.dict_from_cookiejar(s.cookies) # 将jar格式转化为dict
ck = 'JSESSIONID=' + ck_dict['JSESSIONID'] # 重组cookies
"""获得二维码"""
path = './code.png'
get_cookies_headers = {
'user-anget': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Cookie': ck}
get_cookies_url = 'http://**************'
code_image = requests.get(get_cookies_url, headers=get_cookies_headers)
with open(path, 'wb') as fn:
fn.write(code_image.content)
fn.close()
print('验证码保存成功')
return ck
def login(cookies, hour, minute):
login_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '45',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
login_url = 'http://**************'
login_data = {
'codeImage': input('请输入验证码:'),
'uname': '**************',
'upass': '**************'
}
requests.post(login_url, data=login_data, headers=login_headers)
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
value_h = re.findall(reg_h, res.text)
"""定时"""
counter = 0
while (True):
now = datetime.datetime.now() # 获取当前系统时间
if now.hour == hour and now.minute == minute:
break
time.sleep(0.5)
# print(now)
counter = counter + 1
if counter == 240:
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
reg_t = r'(\d{4}-\d{2}-\d{2})' # 匹配可提供预约的日期
value_h = re.findall(reg_h, res.text)
value_t = re.findall(reg_t, res.text)
with open('./con_log.txt', 'a') as fjs:
fjs.write(eval(value_h[-1])+' '+value_t[-1]+' '+str(now)+' \n')
fjs.close()
print('保存成功')
counter = 0
return str(eval(value_h[-1]))
def reservation(day_hash, cookies, stime, etime):
reservation_data = {
'_etime': etime, # 结束时间11点,其值为11*60=660
'_roomid': '1285b3ca77594b3095c7b89d4922553c', # 房间Id
'_seatno': '',
'_stime': stime, # 开始时间8点,其值为8*60=480
'_subject': '学习', # 研讨主题
'_summary': '学习', # 研讨大纲
'ruleId': day_hash,
'usercount': 3, # 预约人数
'users': '**************', # 学号
'UUID': '**************'
}
reservation_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '239',
'Content-Type': 'application/json',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
reservation_js = json.dumps(reservation_data)
reservation_url = 'http://**************'
status = requests.post(reservation_url, data=reservation_js, headers=reservation_headers)
# print(stime, etime)
# print(status)
print(status.text)
def main():
"""预约策略一:11:20-20.40"""
full_stime = ['1060', '870', '680']
full_etime = ['1240', '1050', '860']
"""预约策略二:10:00-13:00;13:50-16:50;17:40-20:40"""
stime = ['1060', '830', '600']
etime = ['1240', '1010', '780']
cookies = get_cookies()
day_hash = login(cookies, 0, 0) # 设定定时时间
for i in range(0, 3):
reservation(day_hash, cookies, stime[i], etime[i])
if __name__ == '__main__':
main()实现效果
自从学了python,妈妈再也不用担心我抢不到研习室了。在程序中加几行定时的程序之后,便可以在00:00自动帮我预约研习室了。通过测试发现,预约时很大程度上是能够约到房间的,例如在4-12号,约好三个时间段是用了7秒,但是在4-13号居然花了21秒,而且使得一个时间段被其他同学约走了。当然这个程序还需要进一步改进,实现完胜“手速”。
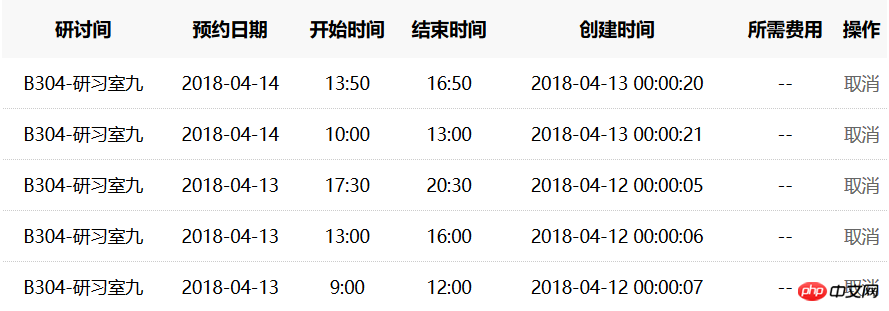
补在最后
还有不足,欢迎交流。
相关推荐:
Das obige ist der detaillierte Inhalt vonPython implementiert die automatische Reservierungsfunktion für den Lernraum der Bibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



