


Der Inhalt dieses Artikels ist eine detaillierte Erklärung der Klassifizierungsbewertungsindikatoren und der Python-Code-Implementierung. Jetzt kann ich ihn mit Ihnen teilen .
Leistungsmessungsindikatoren (Bewertung) werden hauptsächlich in zwei Kategorien unterteilt:
1) Klassifizierungsbewertungsindikatoren (Klassifizierung), hauptsächlich Analyse, diskret, Ganzzahl. Zu seinen spezifischen Indikatoren gehören Genauigkeit (Genauigkeit), Präzision (Präzision), Rückruf (Rückruf), F-Wert, P-R-Kurve, ROC-Kurve und AUC.
2) Der Regressionsbewertungsindex (Regression) analysiert hauptsächlich die Beziehung zwischen ganzen Zahlen und reellen Zahlen. Zu seinen spezifischen Indikatoren gehören explianed_variance_score, mittlerer absoluter Fehler MAE (mean_absolute_error), mittlerer quadratischer Fehler MSE (mean-squared_error), quadratischer Mittelwert der Differenz RMSE, Kreuzentropieverlust (Log-Verlust, Kreuzentropieverlust), R-Quadrat-Wert (Bestimmungskoeffizient). , r2_score).
Gehen Sie davon aus, dass es nur zwei Kategorien gibt – positiv und negativ. Normalerweise ist die Kategorie von Besorgnis die positive Kategorie und die anderen Kategorien sind die negativen Kategorien. mehrere Arten von Problemen können auch in zwei Kategorien zusammengefasst werden)
Die Verwirrungsmatrix lautet wie folgt
| Tatsächliche Kategorie | Vorhergesagte Kategorie | |||||||||||||||||||||||
|
Positiv | Negativ | Zusammenfassung | td > |
||||||||||||||||||||
| Positiv | TP | FN | P (tatsächlich positiv) | |||||||||||||||||||||
| Negativ | FP | TN | N (eigentlich negativ) | |||||||||||||||||||||
| 度量 | Accuracy(准确率) | Precision(精确率) | Recall(召回率) | F值 |
| 定义 | 正确分类的样本数与总样本数之比(预测为垃圾短信中真正的垃圾短信的比例) | 判定为正例中真正正例数与判定为正例数之比(所有真的垃圾短信被分类求正确找出来的比例) | 被正确判定为正例数与总正例数之比 | 准确率与召回率的调和平均F-score |
| 表示 | accuracy=
|
precision=
|
recall=
|
F - score =
|
| Messung | Genauigkeit | Präzision | Rückruf (Rückrufrate) td> | F-Wert |
| Definition | Das Verhältnis der Anzahl korrekt klassifizierter Proben zur Gesamtzahl der Proben (Vorhersage ist Anteil der Wahrheit). Spam-Textnachrichten unter Spam-Textnachrichten) | Das Verhältnis der Anzahl der wirklich positiven Beispiele unter den positiven Beispielen und der Anzahl der positiven Beispiele (alle echten Spam-Textnachrichten werden klassifiziert und der Anteil der richtigen wird ermittelt ) | Das Verhältnis der Anzahl korrekt beurteilter positiver Fälle zur Gesamtzahl positiver Fälle | Der harmonische Durchschnitt F-score td> |
| Darstellung | accuracy= | precision= | Recall= | F - score = |
1. Präzision wird oft auch als Präzisionsrate bezeichnet, und Rückruf wird als Rückrufrate bezeichnet
2. Am häufigsten wird F1 verwendet,
Python3.6-Code Implementierung:
#调用sklearn库中的指标求解from sklearn import metricsfrom sklearn.metrics import precision_recall_curvefrom sklearn.metrics import average_precision_scorefrom sklearn.metrics import accuracy_score#给出分类结果y_pred = [0, 1, 0, 0]
y_true = [0, 1, 1, 1]
print("accuracy_score:", accuracy_score(y_true, y_pred))
print("precision_score:", metrics.precision_score(y_true, y_pred))
print("recall_score:", metrics.recall_score(y_true, y_pred))
print("f1_score:", metrics.f1_score(y_true, y_pred))
print("f0.5_score:", metrics.fbeta_score(y_true, y_pred, beta=0.5))
print("f2_score:", metrics.fbeta_score(y_true, y_pred, beta=2.0))1) P-R-Kurve
Schritte:
1. Stellen Sie die Punktzahl von hoch ein zu niedrig „Werte werden sortiert und wiederum als Schwellenwerte verwendet;
2. Für jeden Schwellenwert gelten Testproben mit einem „Score“-Wert größer oder gleich diesem Schwellenwert als positive Beispiele, andere als negative Beispiele. Dadurch entsteht eine Reihe von Prognosezahlen.
z. B. 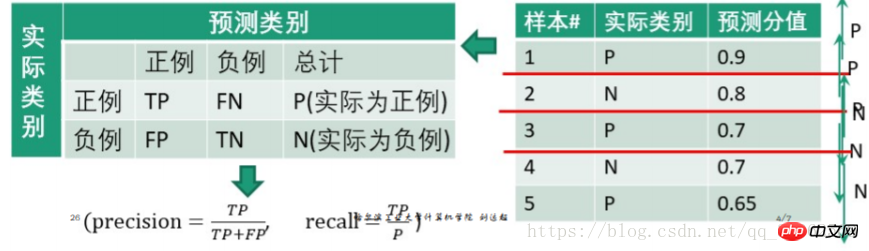
Stellen Sie 0,9 als Schwellenwert ein, dann ist die erste Testprobe ein positives Beispiel und 2, 3, 4 und 5 sind negative Beispiele
Erhalten Sie
| 预测为正例 | 预测为负例 | 总计 | |
| 正例(score大于阈值) | 0.9 | 0.1 | 1 |
| 负例(score小于阈值) | 0.2+0.3+0.3+0.35 = 1.15 | 0.8+0.7+0.7+0.65 = 2.85 | 4 |
| precision= recall= | |||
#precision和recall的求法如上
#主要介绍一下python画图的库
import matplotlib.pyplot ad plt
#主要用于矩阵运算的库
import numpy as np#导入iris数据及训练见前一博文
...
#加入800个噪声特征,增加图像的复杂度
#将150*800的噪声特征矩阵与150*4的鸢尾花数据集列合并
X = np.c_[X, np.random.RandomState(0).randn(n_samples, 200*n_features)]
#计算precision,recall得到数组
for i in range(n_classes):
#计算三类鸢尾花的评价指标, _作为临时的名称使用
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:,i])#plot作图plt.clf()
for i in range(n_classes):
plt.plot(recall[i], precision[i])
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.show()
recall=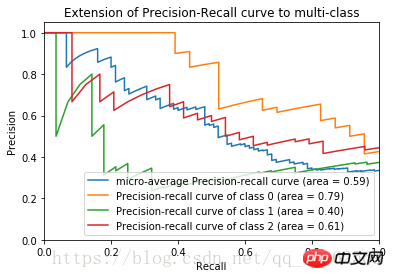
Der Teil unterhalb des Schwellenwerts ist der Wert des vorhergesagten negativen Beispiels und der korrekte vorhergesagte Wert. Wenn es sich also um ein positives Beispiel handelt, wird TP verwendet. Wenn es sich um ein negatives Beispiel handelt, wird TN verwendet , beides sind Vorhersagewerte.
Python implementiert Pseudocode
Nach Abschluss des obigen Codes wird die P-R-Kurve des Irisblütendatensatzes erhalten
Vertikale Achse: Wahre Rate tp-Rate = TP/N
Schritte:  1. Sortieren Sie die „Score“-Werte von hoch nach niedrig und verwenden Sie sie als Schwellenwerte nacheinander;
1. Sortieren Sie die „Score“-Werte von hoch nach niedrig und verwenden Sie sie als Schwellenwerte nacheinander;
2. Für jeden Schwellenwert gelten die Testproben, deren „Score“-Wert größer oder gleich diesem Schwellenwert ist, als positive Beispiele, und die anderen sind negative Beispiele. Dadurch entsteht eine Reihe von Prognosezahlen. 
Sie ähnelt der P-R-Kurvenberechnung und wird nicht noch einmal beschrieben
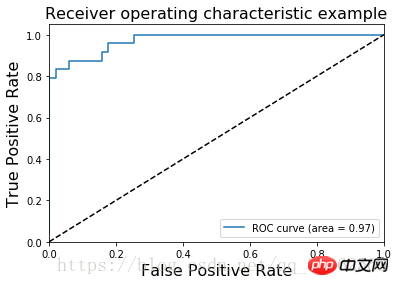
Das ROC-Bild des Irisblütendatensatzes ist 
 AUC (Area Under Curve) ist definiert als die Fläche unter der ROC-Kurve
AUC (Area Under Curve) ist definiert als die Fläche unter der ROC-Kurve
Der AUC-Wert liefert einen numerischen Gesamtwert für den Klassifikator. Normalerweise ist der Klassifikator umso besser, je größer der Wert ist 🎜>
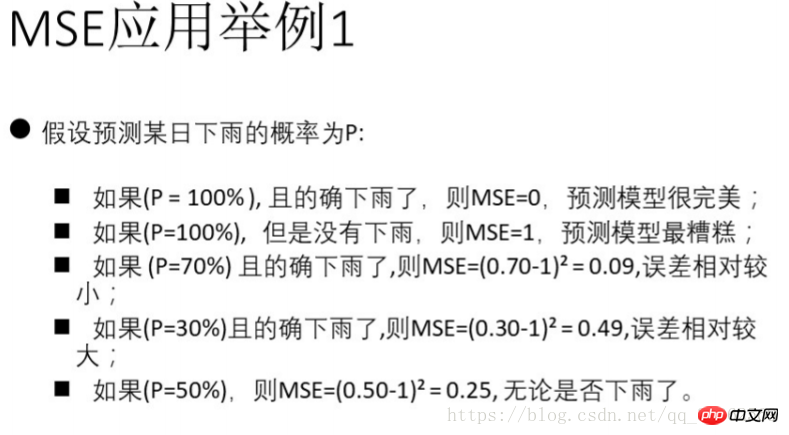
2) Mittlerer absoluter Fehler MAE (mittlerer absoluter Fehler) 
3) mittlerer quadratischer Fehler MSE (mittlerer quadratischer Fehler) 
from sklearn.metrics import log_loss log_loss(y_true, y_pred)from scipy.stats import pearsonr pearsonr(rater1, rater2)from sklearn.metrics import cohen_kappa_score cohen_kappa_score(rater1, rater2)
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Klassifizierungsbewertungsindikatoren und Regressionsbewertungsindikatoren sowie der Python-Code-Implementierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



