


Dieser Artikel teilt Ihnen den Python-Code zur Implementierung der Bildtexterkennung mit. Ich hoffe, er kann Freunden in Not helfen BeispielDas Folgende ist das Bild, das wir identifizieren möchten
Werfen wir zunächst einen Blick auf die Renderings
Eine Codezeile kann Bilder identifizieren, wir müssen hinter den Kulissen einige Vorbereitungsarbeiten durchführen
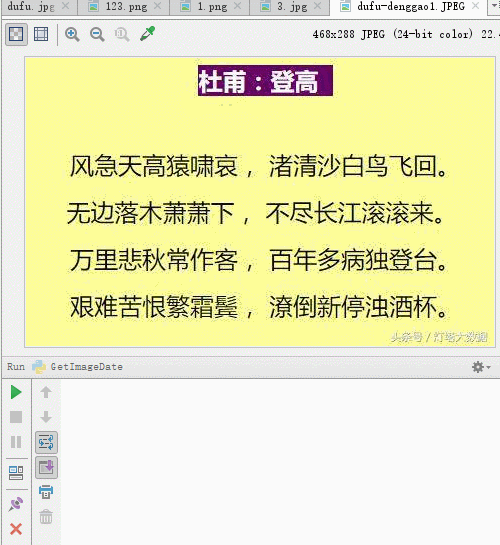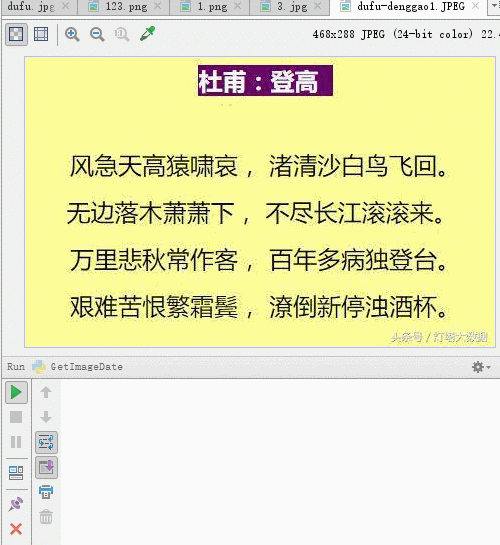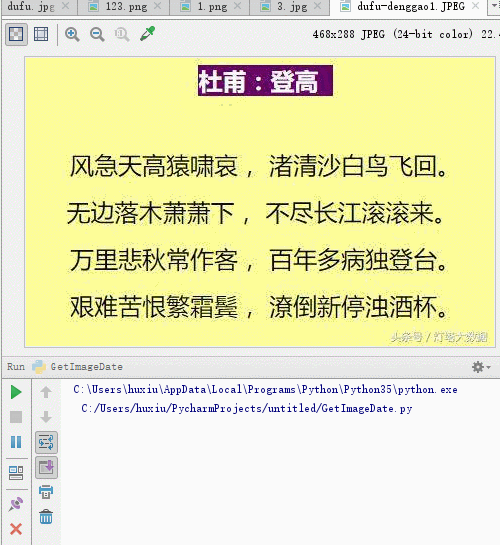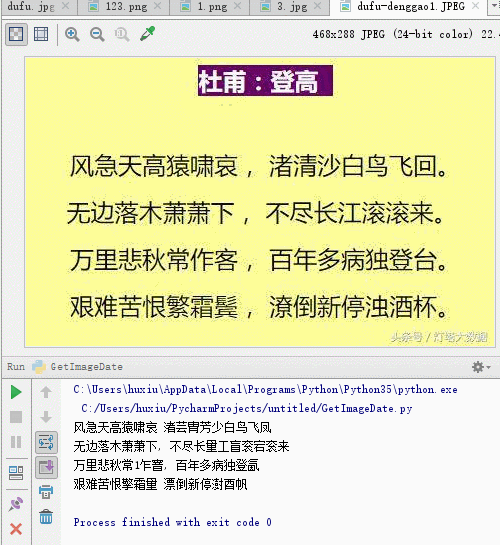
风急天高猿啸哀 渚芸胄芳少白鸟飞凤 无边落木萧萧下, 不尽长量工盲衮宕衮来 万里悲秋常1乍窨, 百年多病独登氤 艰难苦恨擎霜量 漂倒新停澍酉帆
- 2. Wenn Sie den Pycharm-Editor verwenden, können Sie Pycharm direkt verwenden, um eine schnelle Installation zu erreichen.
Befolgen Sie die folgenden Schritte auf der Einstellungsseite von pycharm
Auf diese Weise können Sie Pytesseract erfolgreich installieren. Um PIL zu installieren, müssen Sie im dritten Schritt oben nur nach PIL suchen und klicken Installieren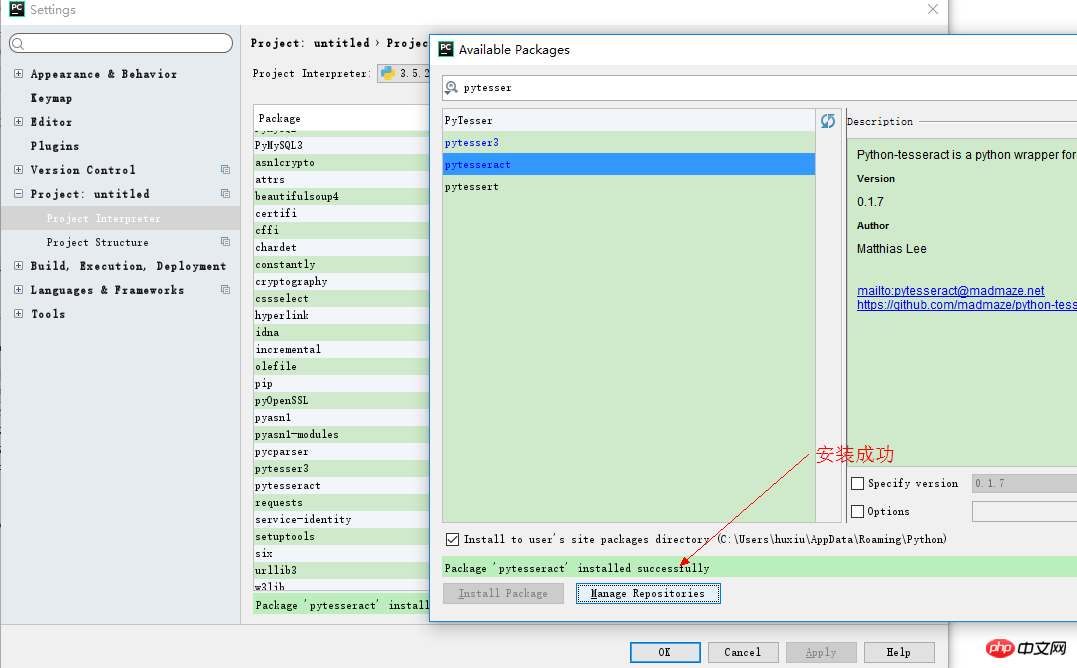
Zu diesem Zeitpunkt haben wir die Bibliothek installiert und den folgenden Code ausgeführt
<🎜 ist nicht installiert >
from PIL import Image import pytesseract text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim') print(text)
Zweitens installieren Sie die Erkennungs-Engine tesseract-ocr
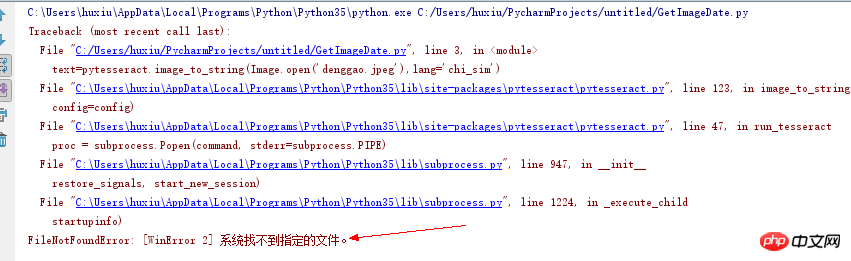
Entpacken und installieren Sie tesseract-ocr und führen Sie die folgenden Schritte aus, um die chinesische Erkennung zu unterstützen. Weil tesseract-ocr die chinesische Erkennung standardmäßig nicht unterstützt.
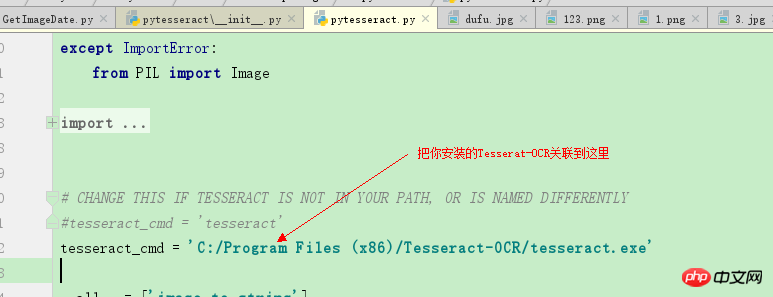
2. Nach der Installation von tesseract-ocr müssen wir noch einige Konfigurationen vornehmen 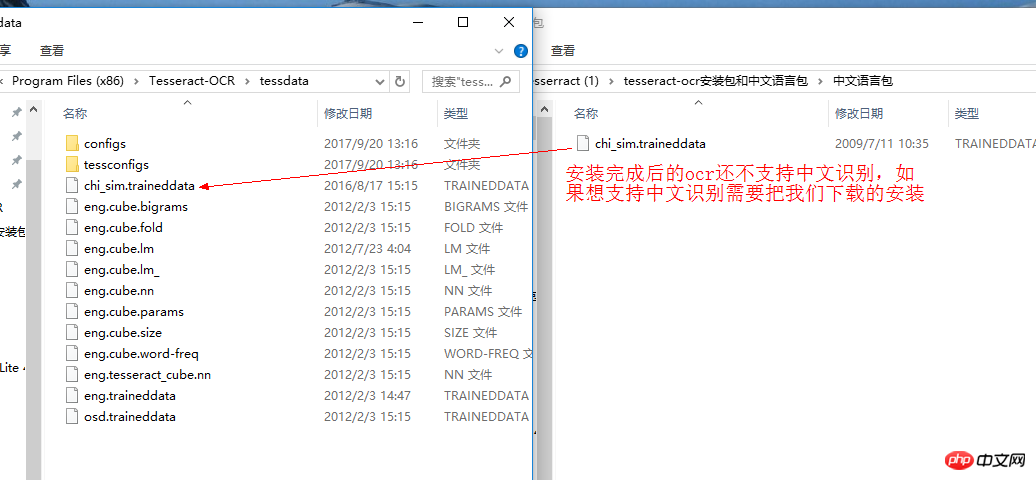 Suchen Sie pytesseract.py in C:UsershuxiuAppDataLocalProgramsPythonPython35Libsite-packagespytesseract und öffnen Sie es Führen Sie den folgenden Vorgang aus:
Suchen Sie pytesseract.py in C:UsershuxiuAppDataLocalProgramsPythonPython35Libsite-packagespytesseract und öffnen Sie es Führen Sie den folgenden Vorgang aus:
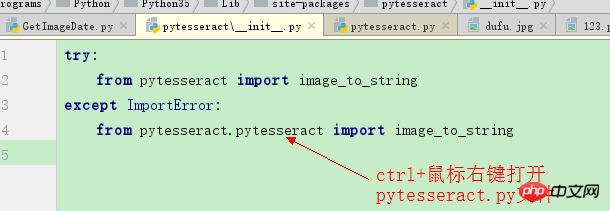
kann auch zum schnellen Öffnen von pytesseract.py über pycharm verwendet werden
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY #tesseract_cmd = 'tesseract' tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
Jetzt sind alle unsere Konfigurationen abgeschlossen. Führen Sie den folgenden Code aus, um das Bildgedicht Du Fu's Ascension in Text zu analysieren
Das obige ist der detaillierte Inhalt vonPython-Code realisiert die Bildtexterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



